golang 在多线程中避免 CPU 指令重排
发布日期:2024-03-26 16:29:39

起因
golang 的发明初衷便是多线程,是一门专门用于多线程高并发的编程语言。其独创的 GMP 模型在多线程的开发上提供了很大的便利。
现代计算机基本上都是多核 CPU 的结构。CPU 在进行指令运行的时候,为了提高效率,会在一些情况下对指令进行重排序,其目的是在保持运行结果和不重拍序的指令一致的前提下,提高程序的运行效率。但是对于多线程并行执行来说,我们可能需要对此额外关注,以避免重排对多线程的影响。
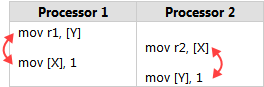
英特尔在其 x86/64 体系结构规范第 3 卷 §8.2.3 中列出了几个这样的问题。这里有一个最简单的例子。假设内存中有两个整数 X 和 Y,最初的值都是 0。两个并行运行的处理器执行以下的机器代码:

虽然在这个例子中使用汇编语言,但这确实是说明 CPU 排序的比较好的方式。每个处理器将 1 存储到其中一个整数变量中,然后将另一个整数加载到寄存器中。(r1 和 r2 只是实际 x86 寄存器(如 eax)的占位符名称。)
现在,无论哪个处理器先将 1 写入内存,都很自然地希望另一个处理器读取回该值,这意味着我们最终应该得到 r1=1、r2=1,或者两者都有。但根据英特尔的规范,情况不一定如此。在规范中,在这个例子的结尾,r1 和 r2 都等于 0 是合法的!这可能是一个违反直觉的结果!
理解这一点的一种方法是,与大多数处理器系列一样,英特尔x86/64处理器可以根据某些规则重新排序机器指令的内存交互,只要它永远不会改变单线程程序的执行。特别地,允许每个处理器将存储的效果延迟超过来自不同位置的任何加载。因此,最终可能会出现指令按以下顺序执行的情况:
程序测试
CPU 指令重排导致的问题
在下面的程序中,来实现上述 CPU 指令重排在多线程中造成的数据不一致现象。下面代码中,声明了 a,b,x,y 四个变量并将其默认值设置为 0。声明两个 go routine 分别执行目标操作(见代码)。正常情况,不管下面 a = 1,x = b,b = 1, y = a 这四条质量如何执行,如果没有重排产生,那么永远不可能出现 x == 0 和 y == 0 同时发生的情况。
但是由于 CPU 指令重排的原因,在实际执行的情况下,在第 1738, 110002, 12987 次测试到了 CPU 指令重排的发生。
func withCpuReordering() {index := 0for {index += 1var a, b int32 = 0, 0var x, y int32 = 0, 0var wg sync.WaitGroupwg.Add(2)go func() {defer wg.Done()a = 1x = b}()go func() {defer wg.Done()b = 1y = a}()wg.Wait()if x == 0 && y == 0 {panic("CPU Reordering occurs!")} else {fmt.Println("Now processing in loop", index)}}
}
绑定 CPU 消除指令重排
上述例子的现象只在多核 CPU 执行的之后才会出现,也就是线程并行执行的时候才会出现。如果我们将上述程序的执行都锁定在一个 CPU 上,也就能避免这种情况的发生。
在下面代码中,我们制定 go routine 最多只能使用一个 CPU。在整个测试过程中,没有出现 x == 0 和 y == 0 同时发生的情况。
func main() {runtime.GOMAXPROCS(1)withCpuReordering()
}原因在于指令重排的目的在于提高执行效率,而不是改变执行结果。
通过内存屏障消除指令重排
在 Go 语言的 sync/atomic 包中,原子操作函数的实现会使用 CPU 提供的原子操作指令,以实现对共享变量的原子读写操作。这些原子操作指令通常会在硬件层面实现内存屏障(Memory Barrier),以确保对共享变量的读写操作在不同的 CPU 核心之间具有一定的有序性。
在下面的代码中,通过 atomic 包中的原子操作函数代替了上述代码中的赋值操作,从而解决了执行结果不一致的情况。
func withoutCpuReordering() {index := 0for {index += 1var a, b int32 = 0, 0var x, y int32 = 0, 0var wg sync.WaitGroupwg.Add(2)go func() {defer wg.Done()atomic.StoreInt32(&a, 1)atomic.StoreInt32(&x, atomic.LoadInt32(&b))}()go func() {defer wg.Done()atomic.StoreInt32(&b, 1)atomic.StoreInt32(&y, atomic.LoadInt32(&a))}()wg.Wait()if x == 0 && y == 0 {panic("CPU Reordering occurs!")} else {fmt.Println("Now processing in loop", index)}}
}
类似的指令和不同的平台
所有这些不同的 CPU 系列,每个都有独特的指令来强制执行内存排序,编译器根据不同的 CPU 系列将代码编译成不同的指令,并且每个跨平台项目都实现了自己的可移植层。这些都无助于简化无锁编程!这也是最近引入 C++11 原子库标准的部分原因。这是一种标准化的尝试,使编写可移植的无锁代码变得更容易。
比如 mfence 指令特定于 x86/64 的 CPU 架构。如果想使代码更具可移植性,可以将此内在特性封装在预处理器宏中。Linux 内核将其封装在一个名为 smp_mb 的宏,以及相关的宏中,如 smp_rmb 和 smp_wmb,并在不同的体系结构上提供了替代实现。例如,在 PowerPC 上,smp_mb 被实现为 sync。
参考文档:
[1] Memory Reordering Caught in the Act https://preshing.com/20120515/memory-reordering-caught-in-the-act/