Spark UI
Spark UI
- Executors
- Environment
- Storage
- SQL
- Exchange
- Sort
- Aggregate
- Jobs
- Stages
- Stage DAG
- Event Timeline
- Task Metrics
- Summary Metrics
- Tasks
展示 Spark UI ,需要设置配置项并启动 History Server
# SPARK_HOME表示Spark安装目录
${SPAK_HOME}/sbin/start-history-server.sh
打开 Spark UI 先见默认 Jobs 页面
- 每个 Action 都对应一个 Job,而每个 Job 都对应着一个作业
Spark UI导航条:

| 入口页 | 内容 | 作用 |
|---|---|---|
| Jobs | Actions,数据读取/移动操作 | 作业详情概览 |
| Stages | DAG 中每个 Stages 的入口 | Stages 详细概览 |
| Storage | 分布式数据集缓存详细页 | Cache 在内存/磁盘中的发布情况 |
| Environment | 配置项,环境变量详情 | Spark 配置项是否合理 |
| Execution | 分布式运行环境/计算负载详情 | 执行计划的每个环节 |
Executors
Executors 有两个部分:Summary/Executors
- Executors:更细的粒度记录着每一个 Executor 的详情
- Summary :所有 Executors 度量指标的累计和
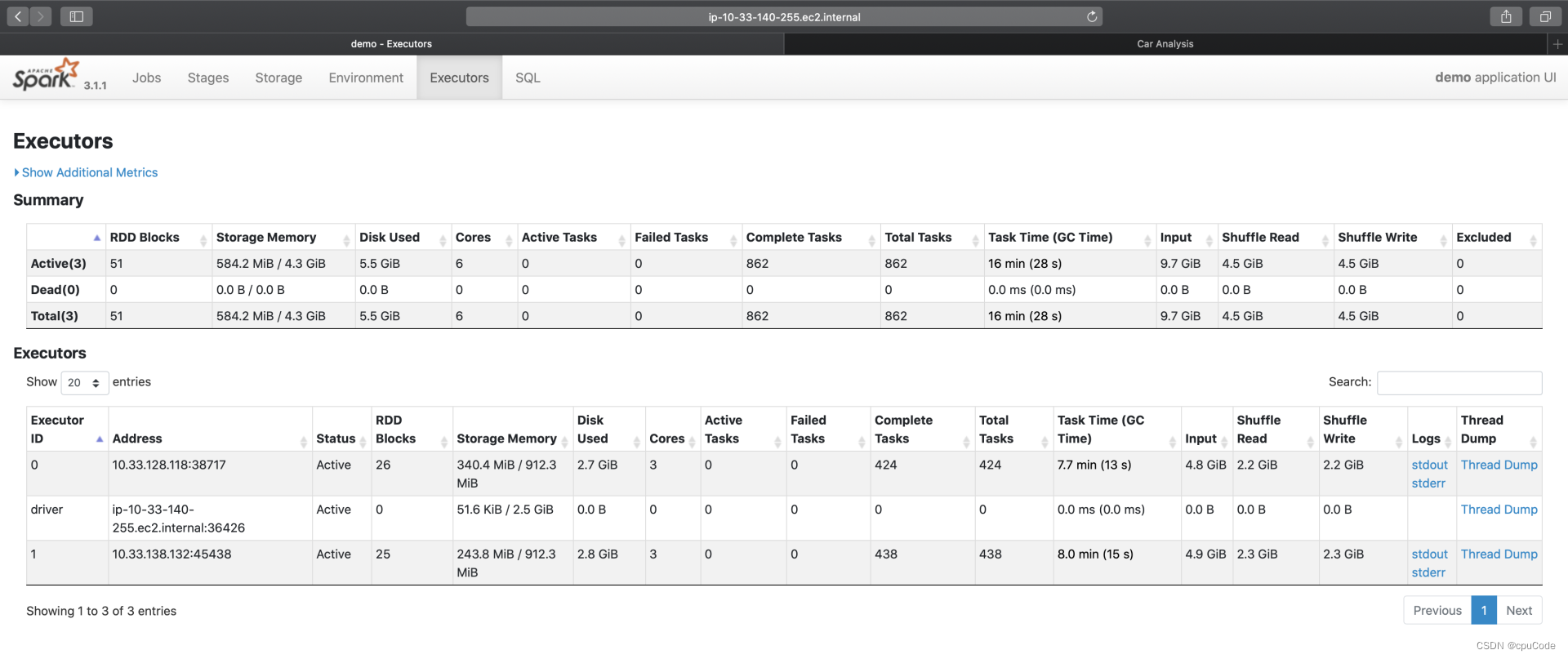
每个 Executor 的工作负载信息:
| Metrics | 含义 |
|---|---|
| RDD Blocks | 原始数据集的分区数 |
| Storage memory | Cache 的内存占用 |
| Disk Used | 计算过程中消耗的磁盘空间 |
| Cores | 计算 CPU 核数 |
| Action/Failed/Complete/Total Tasks | (活跃的/失败的/完成的/总共的)分布式任务数量 |
| Task Time(GC Time) | 任务执行时间(括号内为任务 GC 时间) |
| Input | 输入数据量大小 |
| Shuffle Read/Write | Shuffle 读写过程中消耗的数据量 |
| Logs/Thread Dump | 日志与 Core Dump |
- 根据每个 Executor 的资源消耗,能判断不同 Executors 是否存在负载不均衡
Environment
Environment 记录了各种各样的环境变量与配置项信息
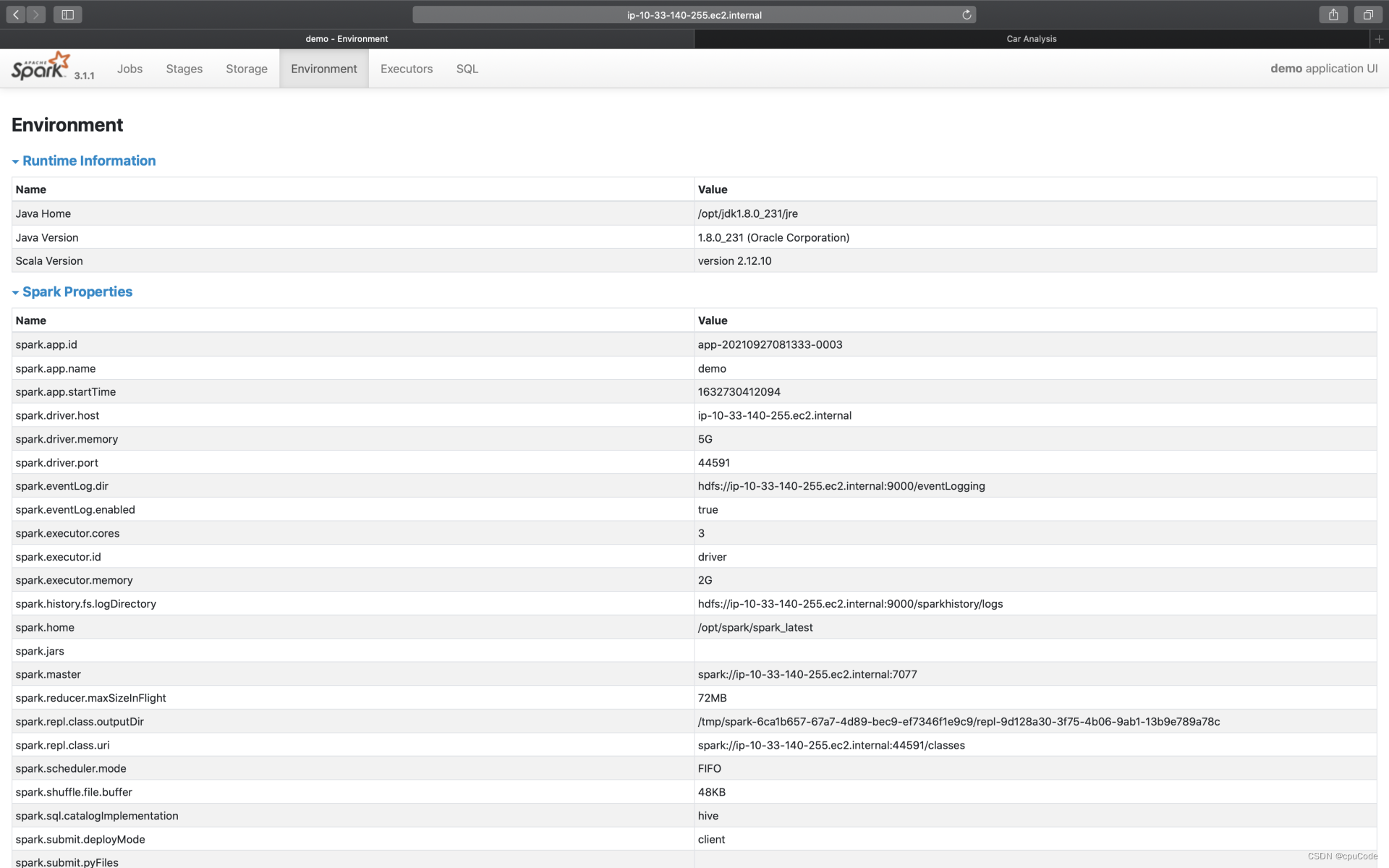
5 个环境信息:
| Metrics | 含义 |
|---|---|
| Runtime information | Java, Scala 版本号等信息 |
| Spark Properties | 所有 Spark 配置项设置 |
| Hadoop Properties | Hadoop 配置信息 |
| System Properties | 应用提交方法(spark-shell/ spark-submit) |
| Classpath Entries | Classpath 路径设置信息 |
- 根据 Spark Properties 信息,能排除是否因配置项设置而导致问题
Storage
Storage 记录了每个分布式缓存(RDD Cache、DataFrame Cache)
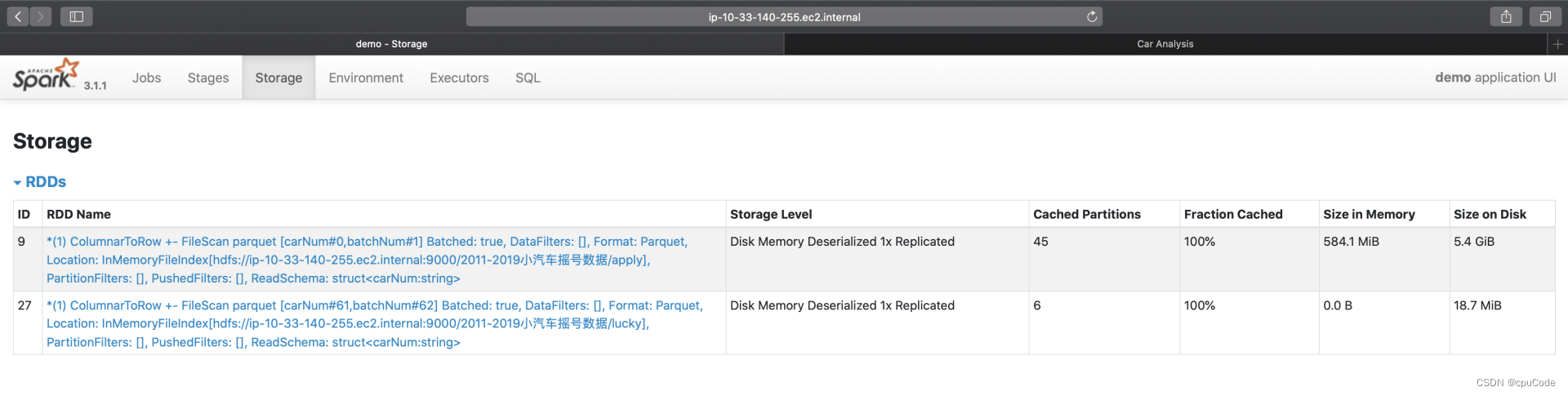
Storage 信息:
| Storage Level | 存储级别 |
|---|---|
| Cached Partitions | 已缓存分区数 |
| Fraction Cached | 缓存比例 |
| Size in Memory | 内存大小 |
| Size on Disk | 磁盘大小 |
- Cached Partitions/Fraction Cached 分别记录:数据集成功缓存的分区数量/这些缓存的分区占所有分区的比例
Fraction Cached < 100%时,说明分布式数据集没有完全缓存到内存(磁盘),这时就要注意缓存换入换出的问题
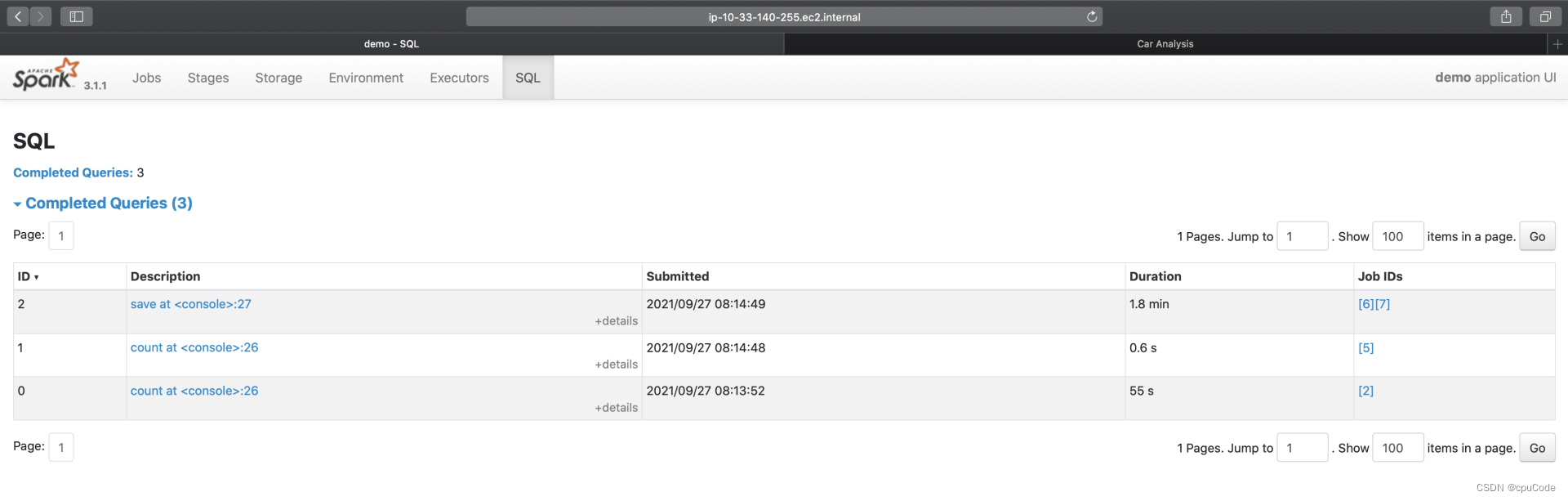
SQL
SQL 的入口页面,记录了每个 Action 对应的 Spark SQL 执行计划。点击 Description 进入二级页面,记录了每个执行计划的详细信息
save 的执行计划 :
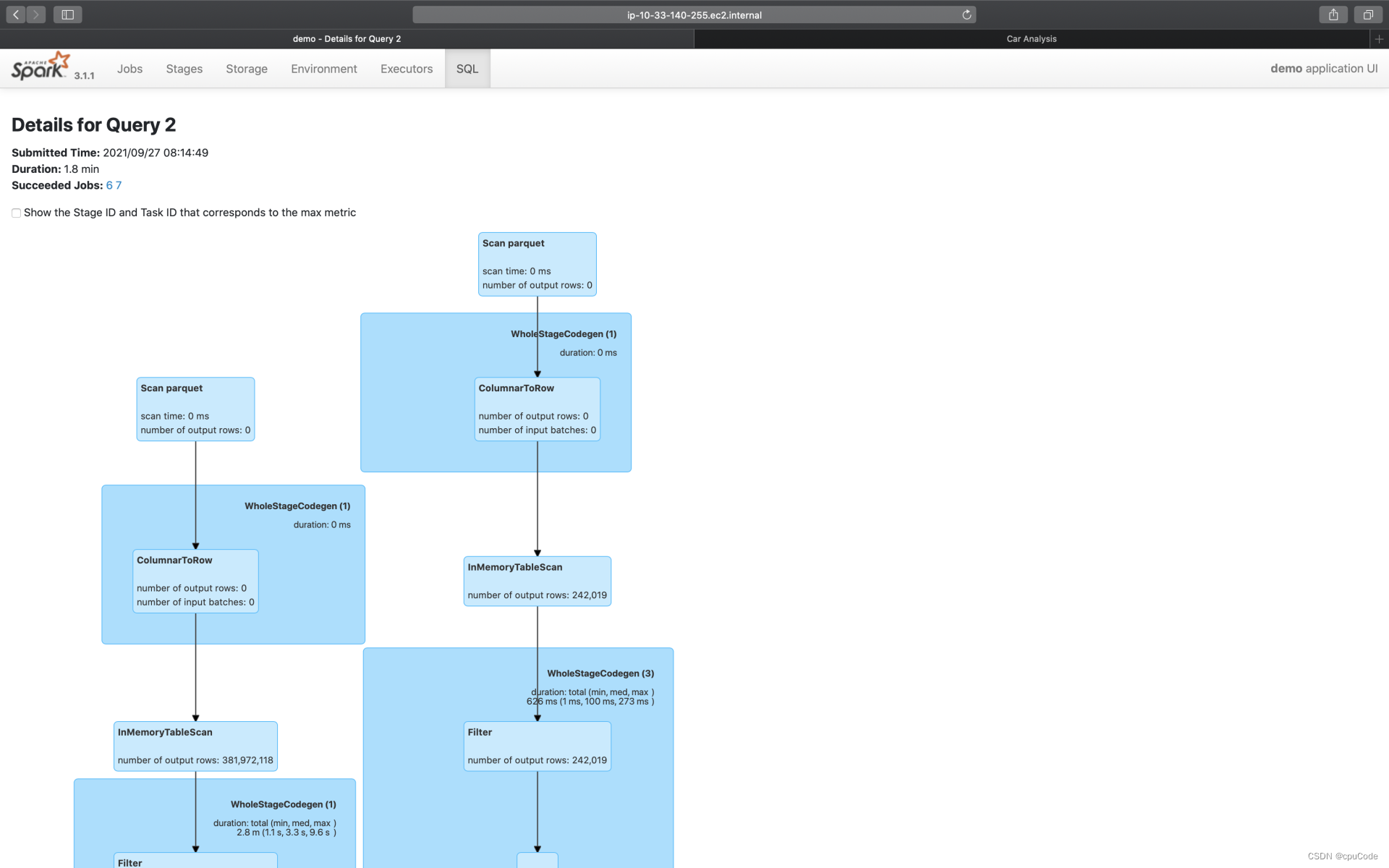
执行计划的示意图 :
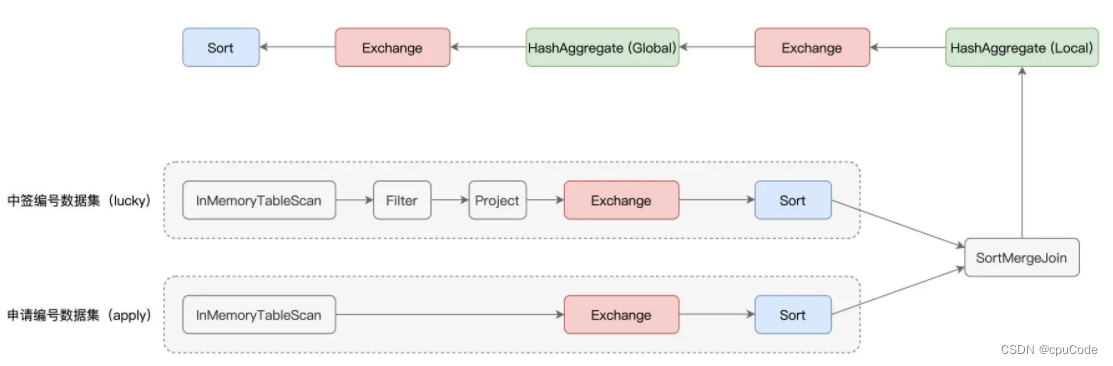
计算过程中有过滤、投影、关联、分组聚合、排序 :
- 红色部分为 Exchange,表示 Shuffle 操作
- 蓝的部分为 Sort,表示排序
- 绿色的部分为 Aggregate,表示(局部与全局的)数据聚合
Exchange
并列有两个 Exchange,对应的 SortMergeJoin 前的两个 Exchange :
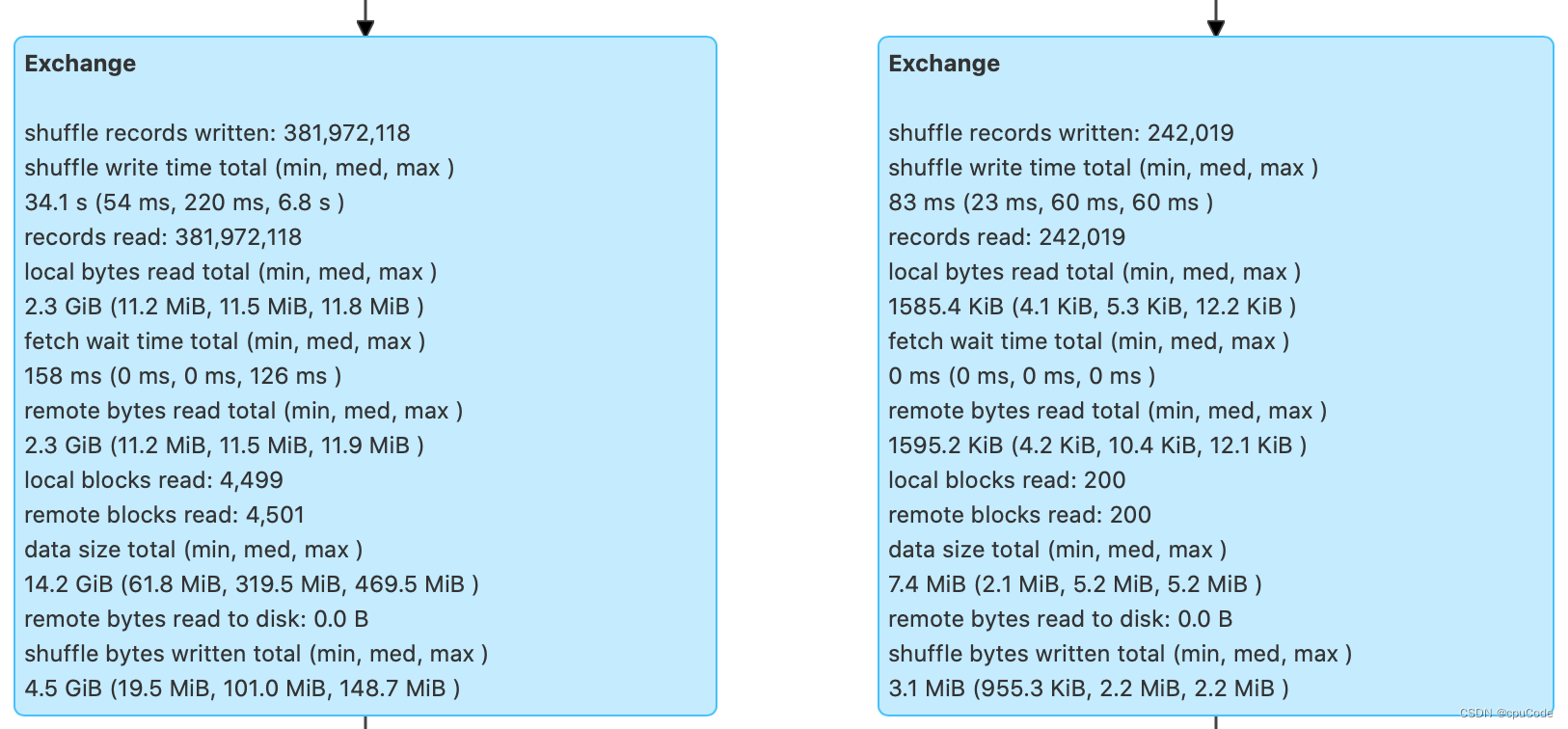
Shuffle 的计算信息:
| Shuffle records written | Shuffle Write 阶段写入的数据条目数 |
|---|---|
| Shuffle write time total | Shuffle Write 阶段花费的写入时间 |
| Records read | Shuffle Read 阶段读取的数据条目数 |
| Local bytes read total | Shuffle Read 阶段从本地节点读取的数据总量 |
| Fetch wait time total | Shuffle Read 阶段花费在网络传输上的时间 |
| Remote bytes read total | Shuffle Read 阶段跨网络,从远节点读取的数据总量 |
| Local blocks read | Shuffle Read 阶段从本地节点读取数据块数 |
| Remote blocks read | Shuffle Read 阶段跨网络,从远节点读取的数据块数 |
| Data size total | 原始数据在内存中展开后的总大小 |
| Remote bytes read to disk | Shuffle Read 阶段因数据块过大而直接落盘的情况 |
| Shuffle bytes written total | Shuffle 中间文件总大小 |
- 而过滤后的中签编号数据大小不足 10MB,对于这种大表 Join 小表,用 SortMergeJoin 不是很合理。可以使用强制广播或 AQE 让 Spark SQL 选择 BroadcastHashJoin
Sort
Sort 在运行时的内存消耗:
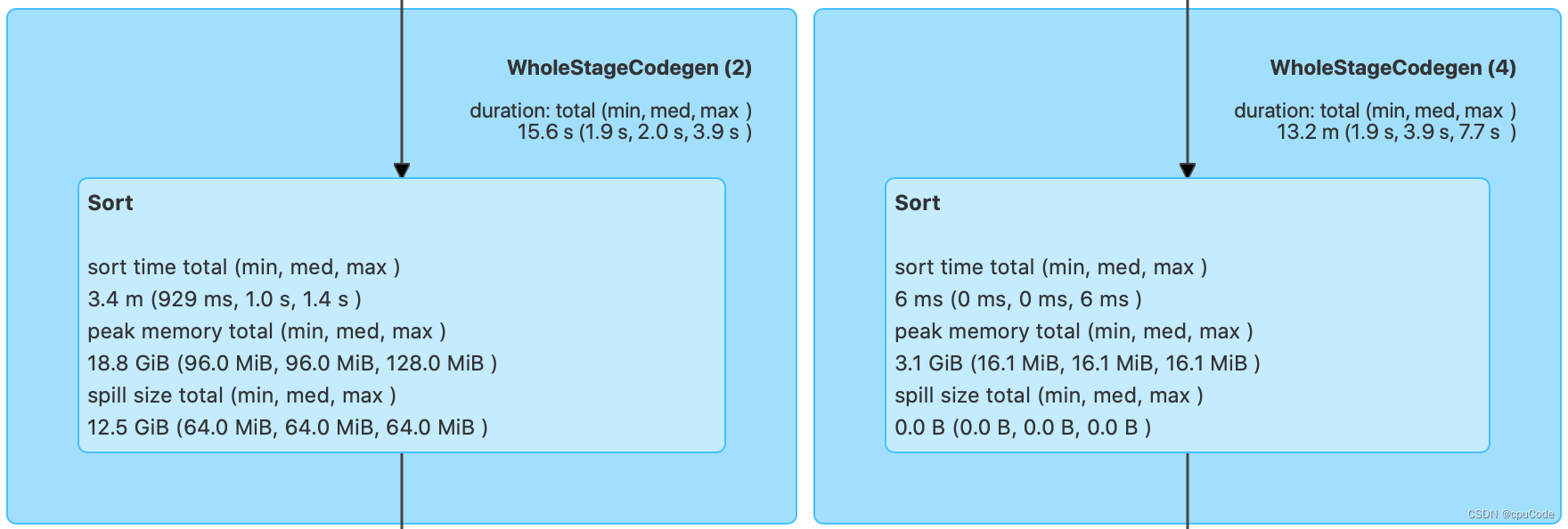
Sort 信息:
| Sort time total | 排序消耗的总时间 |
|---|---|
| Peak memory total | 内存消耗峰值 |
| Spill size total | 排序过程中溢出到磁盘的数据总量 |
- 根据
Peak memory total/Spill size total信息,能有效的设置spark.executor.memory/spark.memory.fraction/
spark.memory.storageFraction,提高性能
例子:18.8GB 的峰值消耗和 12.5GB 的磁盘溢出这两条信息,就能知道当前 3GB 的 Executor Memory 是不够的。需要调整上面的 3个参数,来加速 Sort 的执行性能
Aggregate
Aggregate 主要是内存消耗,记录Spill size(磁盘溢出)/ Peak memory total(峰值消耗)

图中:零溢出与 3.2GB 的峰值消耗,证明 3GB 的 Executor Memory 能满足
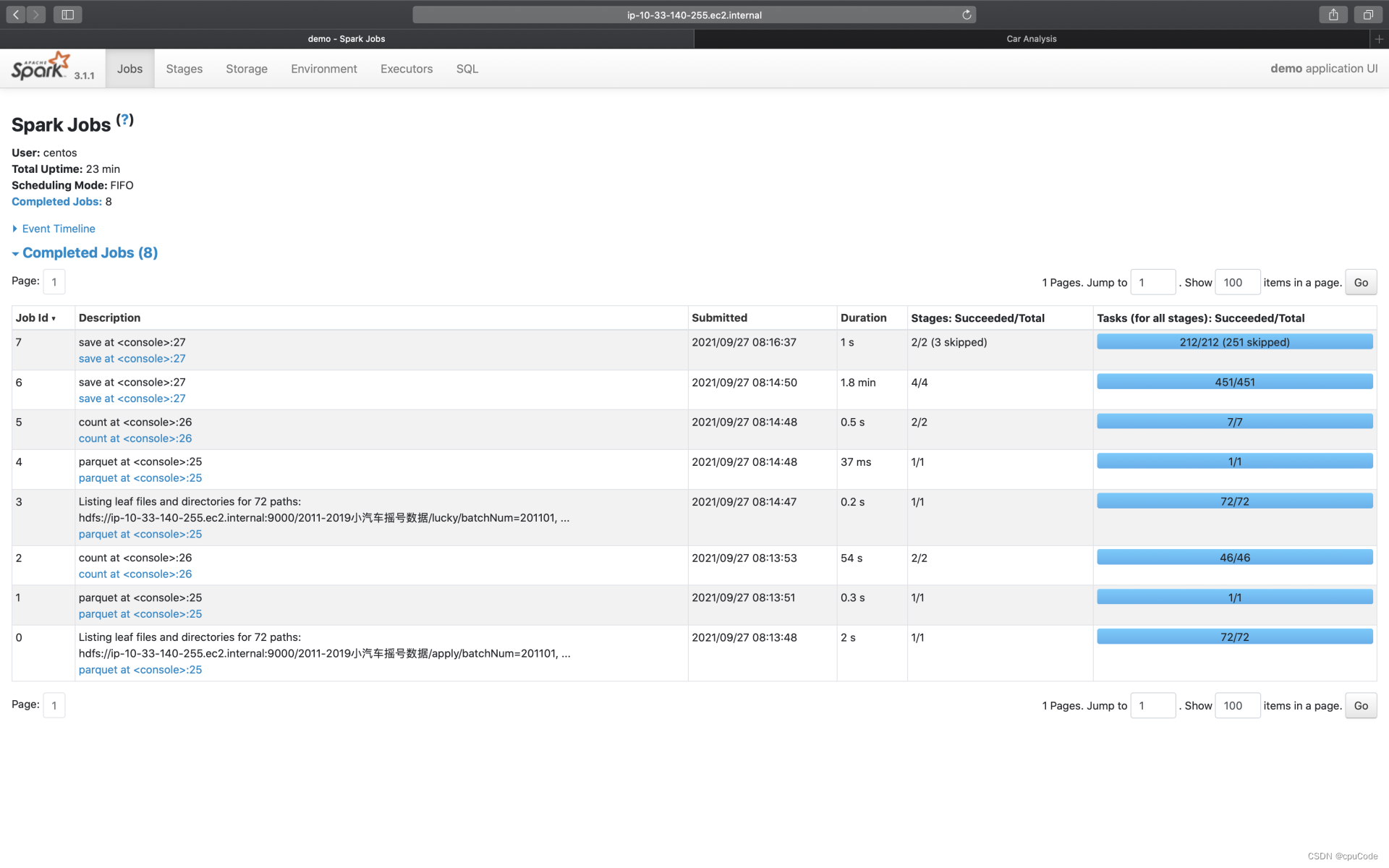
Jobs
Jobs 的入口页面记录了每个 Action 对应作业的执行情况
- 点击 Description 进入二级页面,记录了每个作业详细信息
- Jobs 详情页会显示当前 Job 的所有 Stages。每个 Stage 的执行细节能通过 Description 的跳转
Stages
Stages 记录了每一个作业的 Stages。Description 进入二级页面,记录了每个 Stage 详情页
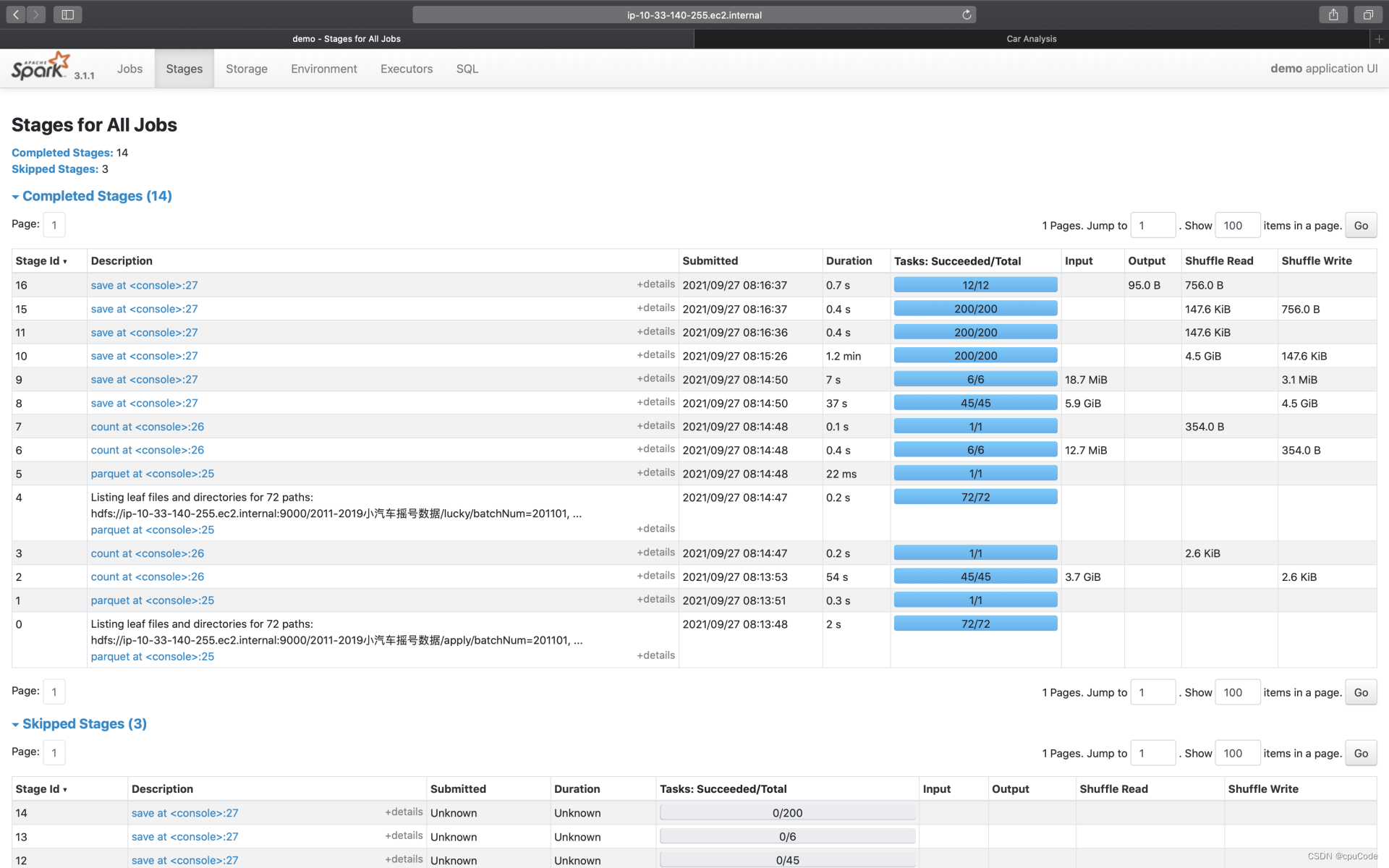
Stage 详情页包含 3 大类信息: Stage DAG、Event Timeline、Task Metrics
- Task Metrics 分为 Summary、Entry details 提供不同粒度的信息汇总
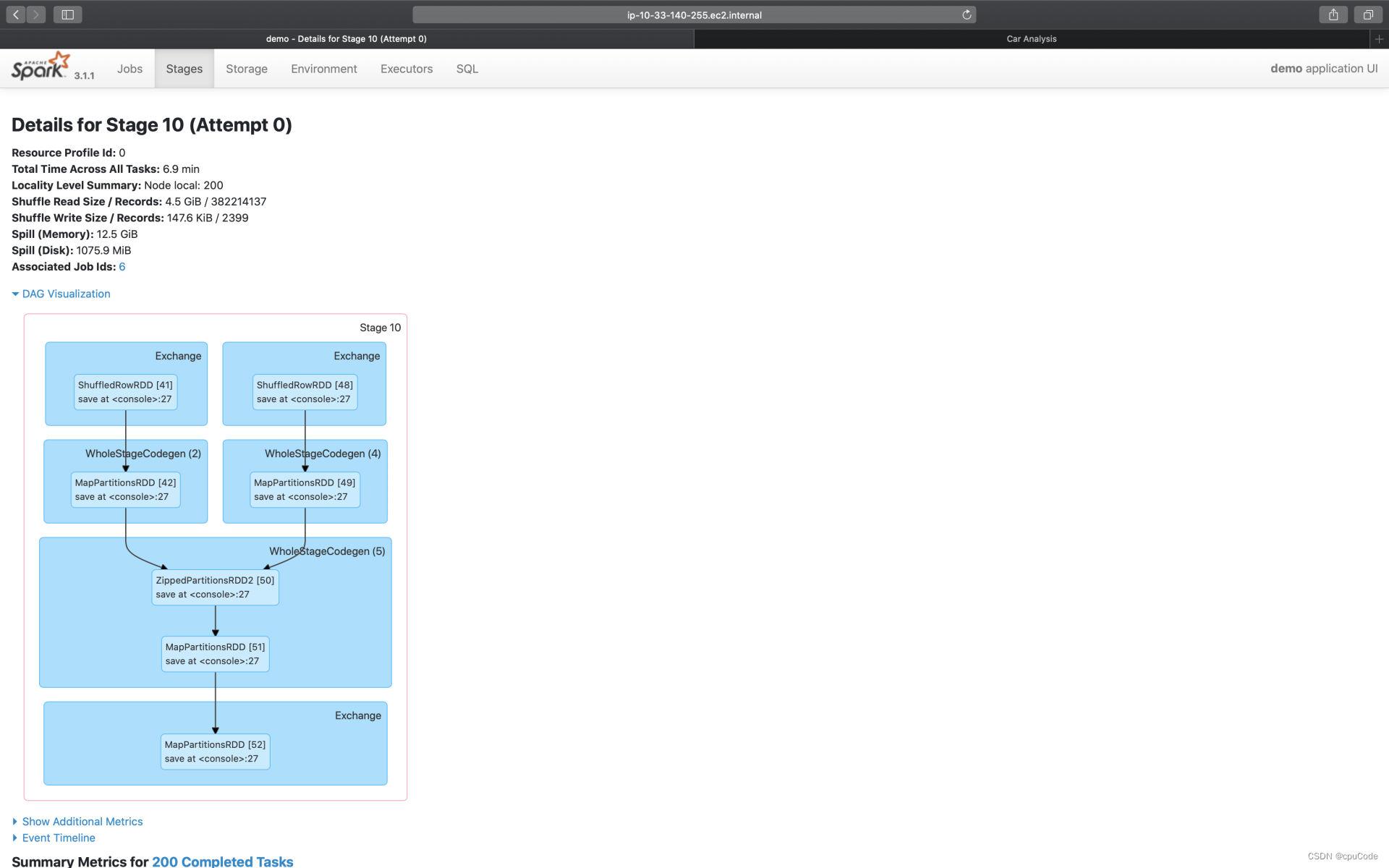
Stage DAG
点击 DAG Visualization,就能获取到当前 Stage 的 DAG Stage。 DAG 仅是 SQL 页面完整 DAG 的一个子集
Event Timeline
点击 Event Timeline ,可视化信息记录了分布式任务调度与执行过程中,不同计算环节的主要时间花销
- 图中的每个条带就代表着一个分布式任务,条带由不同的颜色构成
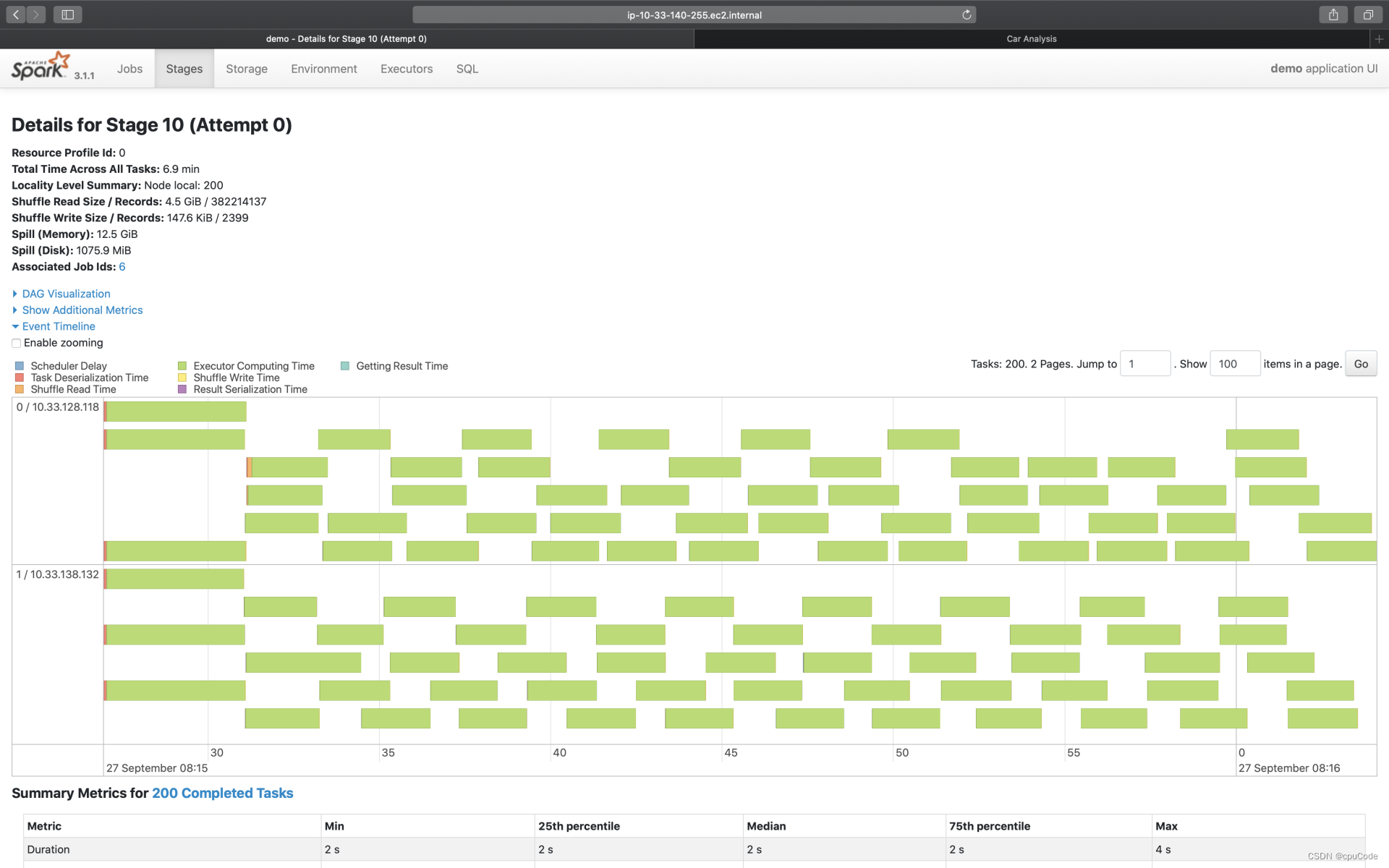
不同环节的计算时间:
| Metrics | 颜色 | 含义 |
|---|---|---|
| Scheduler Delay | 深蓝 | 调度延迟(调度系统开销) |
| Task Deserialization Time | 红色 | 任务的反序列化时间(调度系统开销) |
| Shuffle Read Time | 橙色 | Shuffle Read 时间开销 |
| Executor Computing Time | 绿色 | 计算时间 |
| Shuffle Write Time | 黄色 | Shuffle Write 时间开销 |
| Result Serialization Time | 紫色 | 任务结果的序列化时间 |
| Getting Result Time | 浅蓝 | 结果收集花费的时间 |
结合 Event Timeline,来判断作业是否存在调度开销过大、Shuffle 负载过重的问题
例子:深蓝的部分(Scheduler Delay)很多,就说明任务的调度开销很重。这时就需要参考公式:D / P ~ M / C ,来调整 CPU、内存、并行度,来减低任务的调度开销
- D 是数据集尺寸,P 为并行度
- M 是 Executor 内存,C 是 Executor 的 CPU 核数
- 波浪线 ~ 表示:等式两边的数值,要在同一量级
例子:黄色(Shuffle Write Time)/橙色(Shuffle Read Time)的面积较大,就说明任务的 Shuffle 负载很重,这时就需要考虑是否能通过Broadcast Join 来消除 Shuffle
Task Metrics
Task Metrics
- Summary Metrics : 对所有 Tasks 执行细节的统计汇总
- Tasks : 以 Task 为粒度,记录着每个分布式任务的执行细节
Summary Metrics
点击 Show Additional Metrics ,勾选 Select All ,让所有的度量指标都生效
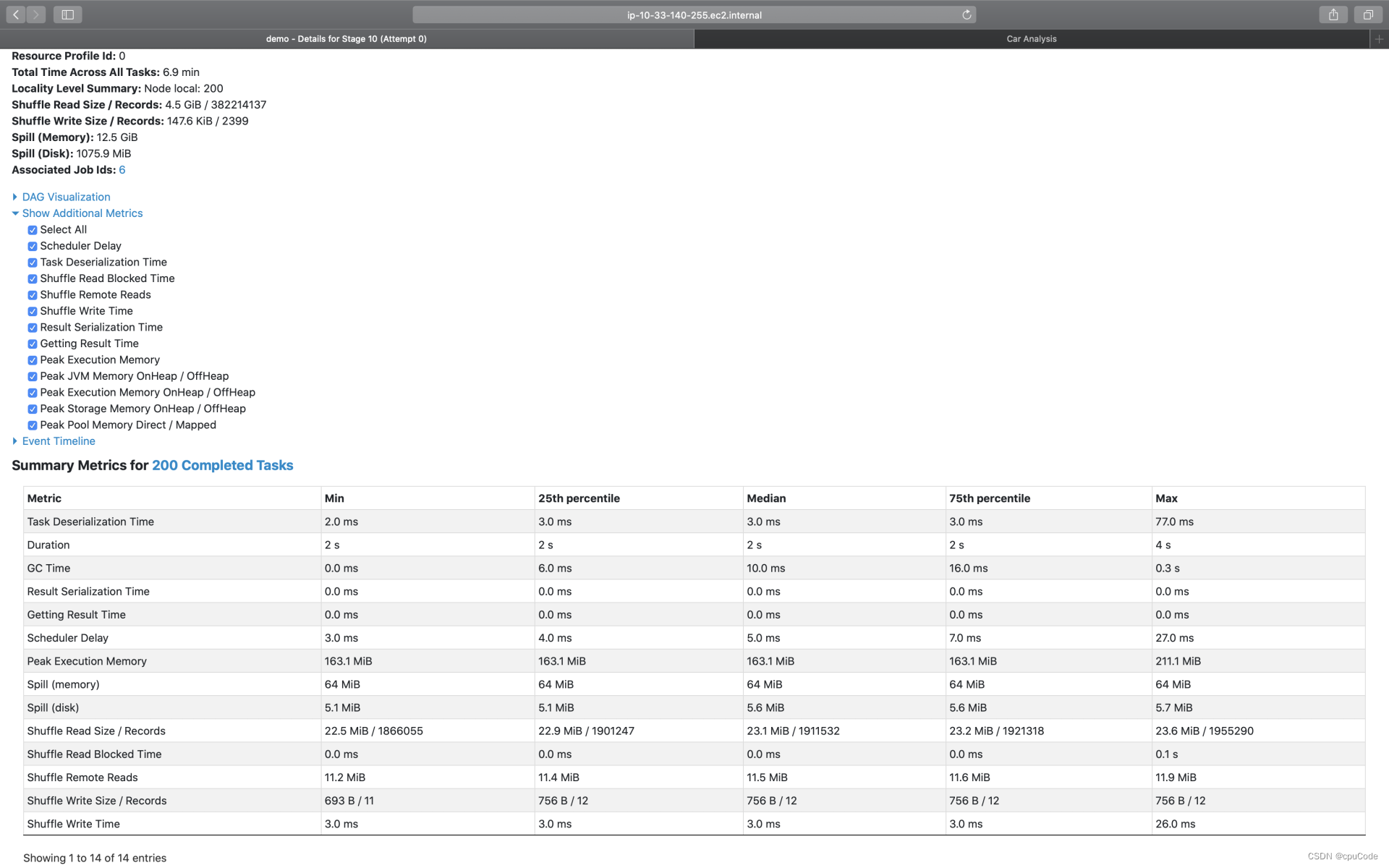
不同环节的计算时间 :
| Metrics | 含义 |
|---|---|
| Duration | Task 执行时间 |
| GC Time | 任务执行过程中, Java GC 时间 |
| Peak Execution Memory | 内存峰值消耗 |
| Spill ( Memory ) | 溢出数据的内存占用 |
| Spil (Disk) | 溢出数据的磁盘占用 |
| Shuffle Read Size/ Records | Shuffle Read 读取的数据量/条目数量 |
| Shuffle Read Blocked Time | Shuffle Read 的网络延迟 |
| Shuffle Remote Reads | Shuffle Read 跨节点、从远端节点拉取的数据量 |
| Shuffle Write Size Records | Shuffle Write 写入的数据量/条目数量 |
| Shuffle Write Time | Shuffle Write 花费的写入时间 |
Spill (溢出数据) : 因内存数据结构(PartitionedPairBuffer、AppendOnlyMap)空间受限,而腾挪出去的数据
- Spill(Memory):这块数据在内存中的存储大小
- Spill(Disk):这块数据在磁盘中的大小
Spill(Memory) / Spill(Disk)= Explosion ratio (数据膨胀系数) 。能估算它在内存中的存储大小
Tasks
Tasks度量指标 :
| Metrics | 含义 |
|---|---|
| Locality level | 本地性级别 |
| Logs | 执行日志 |
| Errors | 执行错误细节 |
- Locality level:每个 Task 会结合本地性倾向,把 Tasks 调度到合适的 Executors/计算节点,尽可能保证数据不动、代码动
- Logs : Tasks 的执行日志,记录了 Tasks 在执行过程中的运行状态
- Errors :记录了报错信息,帮助快速定位问题