C语言数据结构易错知识点(6)(快速排序、归并排序、计数排序)
快速排序属于交换排序,交换排序还有冒泡排序,这个太简单了,这里就不再讲解。
归并排序和快速排序都是采用分治法实现的排序,理解它们对分支思想的感悟会更深。
计数排序属于非比较排序,在数据集中的情况下可以考虑使用。这时效率也比较高。
下面讲解一下这三种排序在代码实现上易错的地方:
一、快速排序
快速排序通过每趟排序确定一个数的最终位置最终实现将数组变得有序的功能。主要有三种方法,第一种方法偏向常规,第二种方法是双指针法,第三种方法是非递归法,除此之外,还有一些优化的方案,如挖坑法,随机确定key,三数取中,后面代码实现上会简要说明。
方法一:常规法
1.代码实现:
void QuickSort1(int* arr, int left, int right)
{int start = left, end = right, key = left;if (left >= right)return;while (left < right){while (left < right && arr[right] >= arr[key])right--;while (left < right && arr[left] <= arr[key])left++;swap(&arr[left], &arr[right]);}swap(&arr[key], &arr[left]);key = left;QuickSort1(arr, start, key - 1);QuickSort1(arr, key + 1, end);
}
2.下面是单趟排序的逻辑:

至于需要注意的点,就是当key在左侧时,一定要右侧先动,左侧再动,这样才能保证相遇点的值小于等于arr[key](这个结论可以画图证明,这里就不展开了),当然,逆序同理。
3.下面是整体逻辑的详细解读,写代码时一定要注意细节,后续快排代码不再重复:

4.由于相遇点的值小于等于arr[key]这个结论一定程度上难以理解,于是就出现了一种优化方案——挖坑法,代码如下:
void QuickSort5(int* arr, int left, int right)
{if (left >= right)return;int start = left, end = right, key = left, piti = left;//存储坑的下标int tmp = arr[key];//用来初始坑里的值while (left < right){while (left < right && arr[right] >= tmp)right--;if (left < right){arr[piti] = arr[right];piti = right;}while (left < right && arr[left] <= tmp)left++;if (left < right){arr[piti] = arr[left];piti = left;}}arr[piti] = tmp;key = piti;QuickSort5(arr, start, key - 1);QuickSort5(arr, key + 1, end);
}5.当数组接近有序时,每次调用后key的位置都会很偏,导致递归次数接近N,总时间复杂度来到O(N ^ 2),因此取key尤为关键,关键在于不要一来就取到最小值,因此随机取key和三数取中可以一定程度上缓解这个问题:,代码如下:
三数取中:
int GetMid(int* arr, int left, int right)
{int mid = (left + right) / 2;if (arr[mid] >= arr[left]){if (arr[mid] < arr[right])return mid;else{if (arr[left] < arr[right])return right;elsereturn left;}}else{if (arr[mid] > arr[right])return mid;else{if (arr[right] < arr[left])return left;elsereturn right;}}}
随机取key:
int key = rand() % (right - left + 1) + left;//随机值但是这些方法依旧不能完全消除快排的缺陷,当数组是1111111111这种时,时间复杂度依然会变成O(N ^ 2)
6.时间复杂度分析
快排的时间复杂度是O(NlogN),分析方法如下:
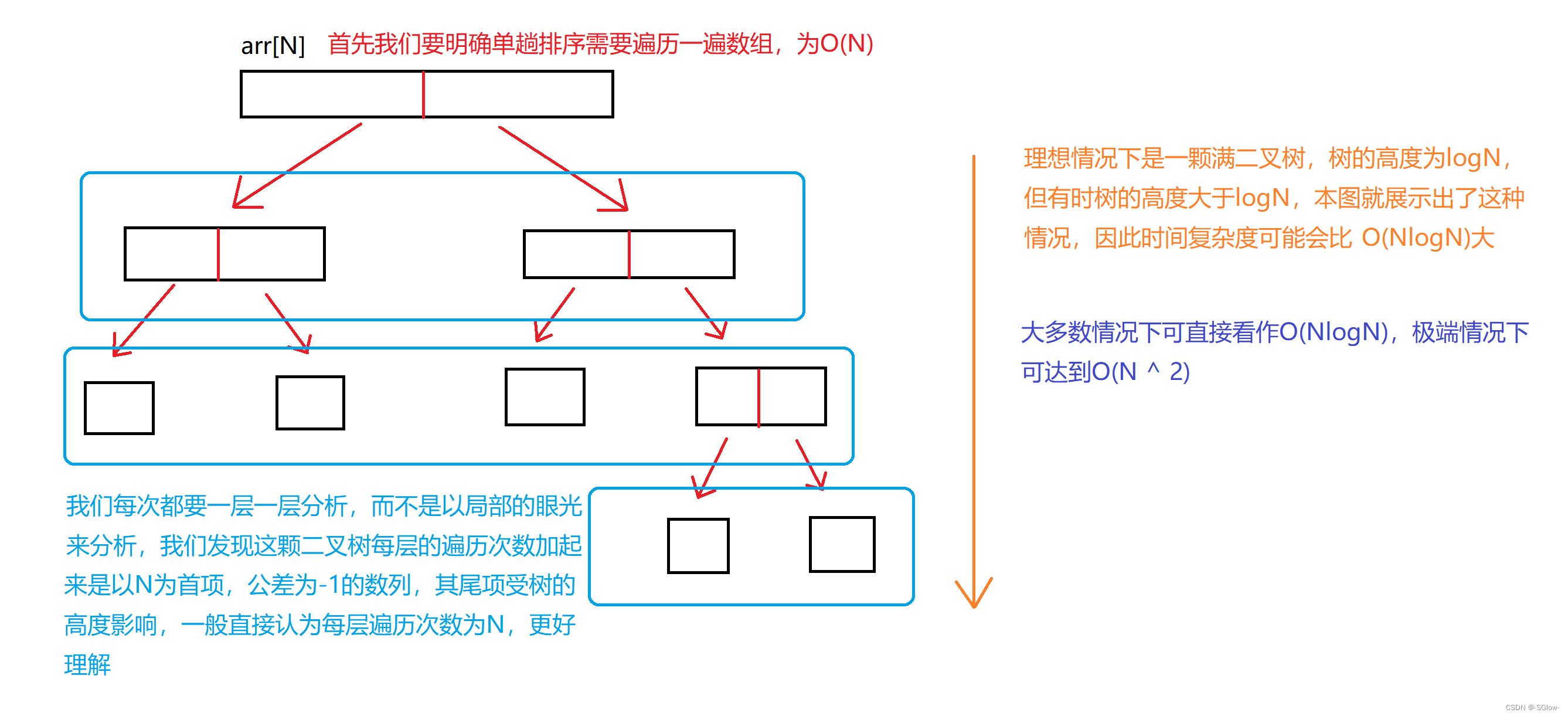
需要补充的是,logN与N的差别很大,N-logN依然是N的量级,举个例子:已知2的10次方是1024,假如有1024个数据,在快排中,单趟排序的遍历次数为1024、1023、1022一直到1014(末项可能会更小,但不会小多少),我们发现,这些数字差别很小,几乎是由N来决定的,所以上面图中说我们一般可以将单趟遍历的次数看作N
方法二:双指针法
这个方法的代码实现比较简单,关键在于prev指针和cur指针之间嵌入大于arr[key]的值,注意每次arr[prev]的下一个元素都是大于arr[key]的(当然也有可能相同或者没有元素,但是在这两种特殊情况下对我们功能的实现没有影响),最后交换arr[key]和arr[prev]达到一样的效果,使右侧大于arr[key],左侧小于等于arr[key]。后续逻辑相同。
代码实现如下:
void QuickSort3(int* arr, int left, int right)
{int prev = left, cur = left + 1, key = left;if (left > right)return;while (cur <= right){if (arr[cur] > arr[key])cur++;elseswap(&arr[++prev], &arr[cur++]);}swap(&arr[key], &arr[prev]);key = prev;QuickSort3(arr, left, key - 1);QuickSort3(arr, key + 1, right);
}
方法三:非递归法
这种方法利用了前序遍历和栈的相似性。为什么说是前序遍历呢?因为在遍历时,该层遍历还同时保存了左递归和右递归的必要信息,就像二叉树的父节点能够找到子节点,而子节点找不到父节点。如果是中序或后序就没有这样的特性,就不适合用栈或队列等数据结构来实现。这也是为什么归并排序不适合用栈和队列来实现非递归。
代码如下:
void QuickSort4(int* arr, int left, int right)
{Stack s;StackInit(&s);StackPush(&s, right), StackPush(&s, left);//从右向左入栈while (!isStackEmpty(&s)){int left = StackTop(&s);StackPop(&s);int right = StackTop(&s);StackPop(&s);int prev = left, cur = left + 1, key = left;//从左向右取数据while (cur <= right){if (arr[cur] > arr[key])cur++;elseswap(&arr[++prev], &arr[cur++]);}swap(&arr[key], &arr[prev]);key = prev;if(key + 1 < right)StackPush(&s, right), StackPush(&s, key + 1);//后取得if(left < key - 1)StackPush(&s, key - 1), StackPush(&s, left);//先取得}StackDestroy(&s);
}
相关栈的功能实现如下:
void StackInit(Stack* ps)
{ps->arr = NULL;ps->capacity = ps->size = 0;
}void StackPush(Stack* ps, int val)
{if (ps->capacity == ps->size){ps->capacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;int* tmp = (int*)realloc(ps->arr, sizeof(int) * ps->capacity);assert(tmp);ps->arr = tmp;}ps->arr[ps->size++] = val;
}int StackTop(Stack* ps)
{return ps->arr[ps->size - 1];
}void StackPop(Stack* ps)
{ps->size--;
}bool isStackEmpty(Stack* ps)
{return ps->size == 0;
}void StackDestroy(Stack* ps)
{free(ps->arr), ps->arr = NULL;ps->capacity = ps->size = 0;}
需要注意入栈顺序是从右向左,右下标先入,左下标后入,右递归先入,左递归后入。基本逻辑和递归相似,理解了原理就很好写。
二、归并排序
归并排序一定程度上比较好理解,但非递归法需要注意的细节比较多
方法一:递归法
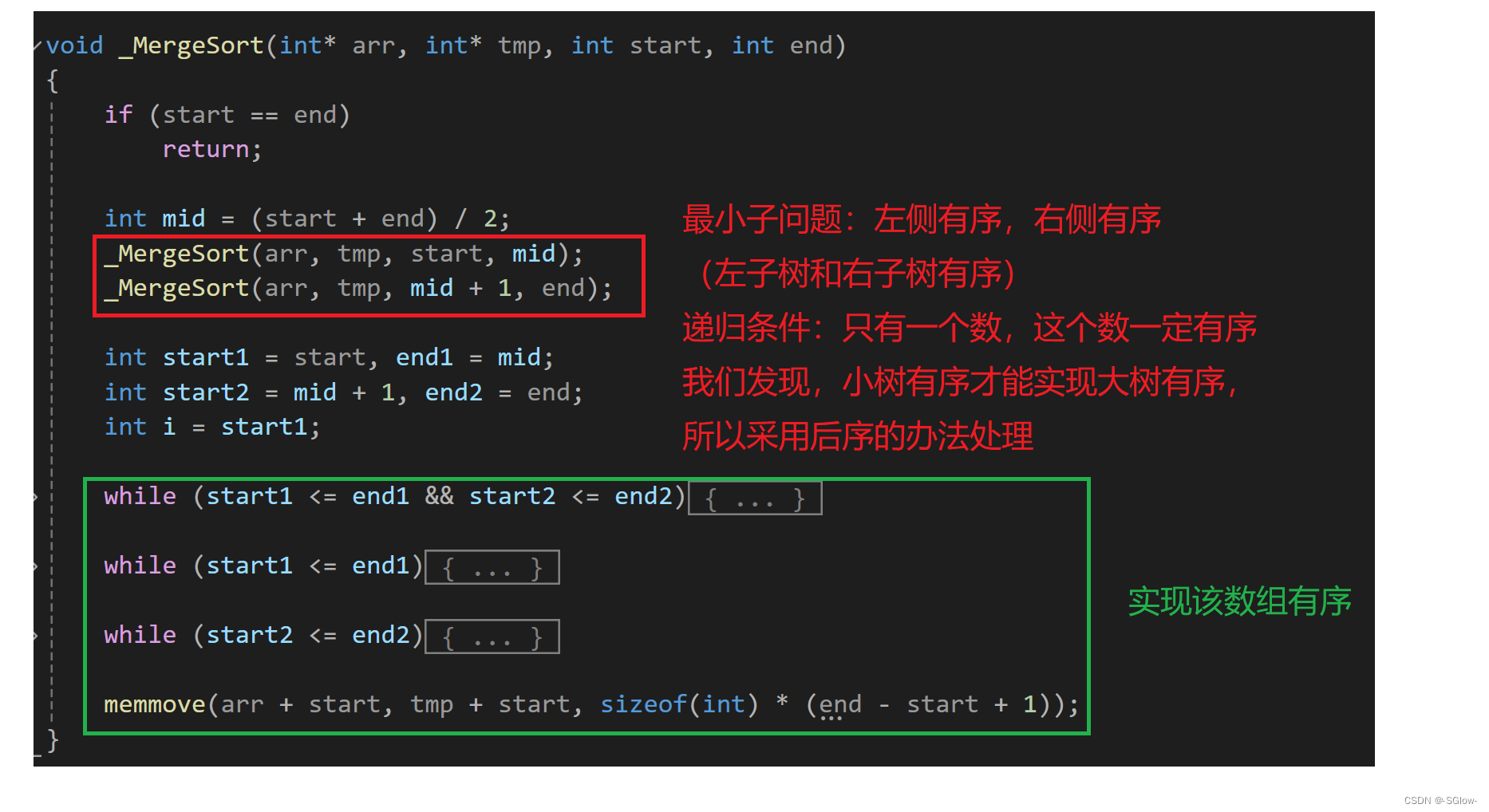
void _MergeSort(int* arr, int* tmp, int start, int end)
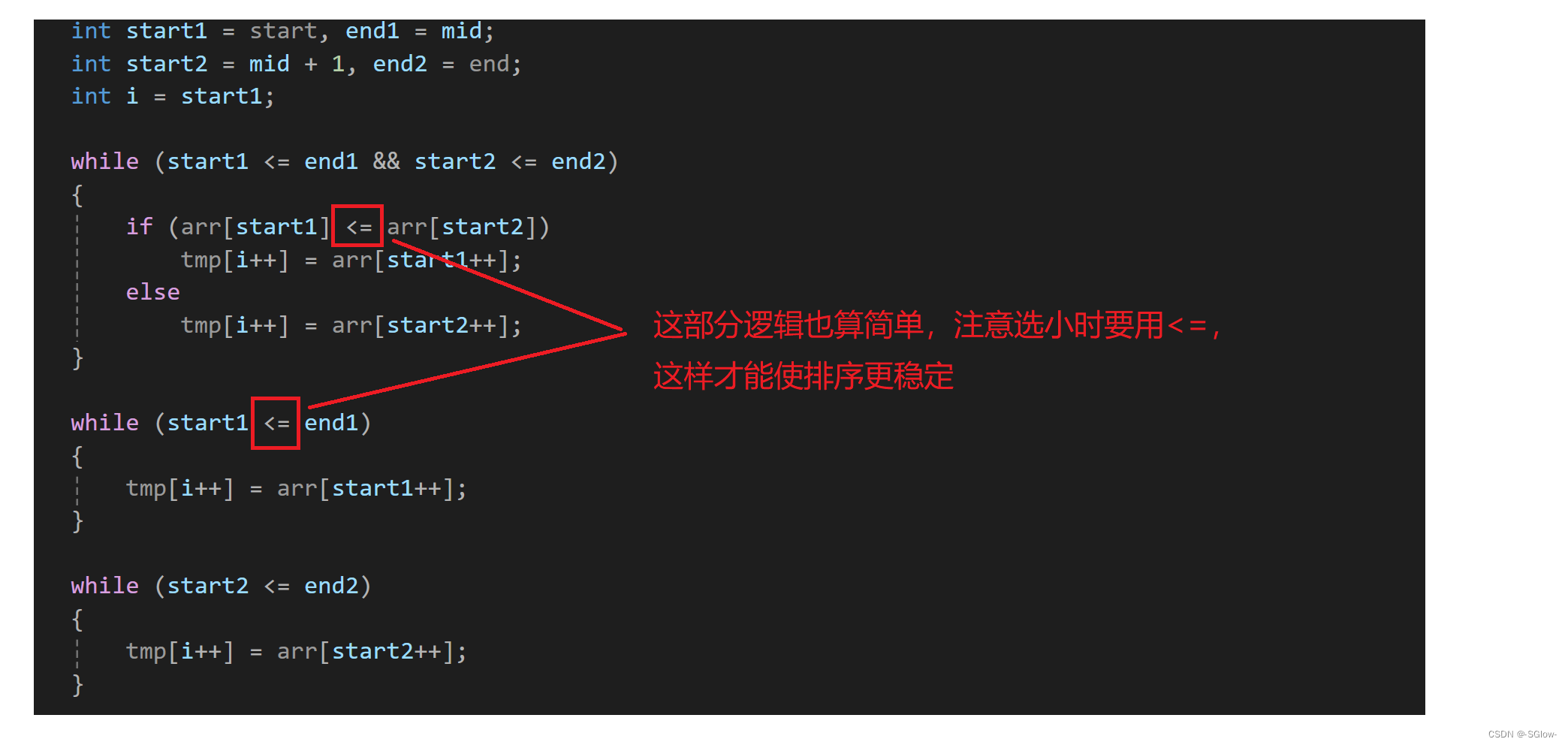
{if (start == end)return;int mid = (start + end) / 2;_MergeSort(arr, tmp, start, mid);_MergeSort(arr, tmp, mid + 1, end);int start1 = start, end1 = mid;int start2 = mid + 1, end2 = end;int i = start1;while (start1 <= end1 && start2 <= end2){if (arr[start1] <= arr[start2])tmp[i++] = arr[start1++];elsetmp[i++] = arr[start2++];}while (start1 <= end1){tmp[i++] = arr[start1++];}while (start2 <= end2){tmp[i++] = arr[start2++];}memmove(arr + start, tmp + start, sizeof(int) * (end - start + 1));
}void MergeSort1(int* arr, int size)
{int* tmp = (int*)malloc(sizeof(int) * size);assert(tmp);_MergeSort(arr, tmp, 0, size - 1);free(tmp), tmp = NULL;
}整体逻辑:
方法二:非递归法
非递归法理解起来较为困难,下面详细分析:
代码实现:
void MergeSort2(int* arr, int size)
{int* tmp = (int*)malloc(sizeof(int) * size);assert(tmp);int gap = 1;while (gap <= size){for (int i = 0; i < size; i += 2 * gap){int start1 = i, end1 = start1 + gap - 1;int start2 = end1 + 1, end2 = start2 + gap - 1;int j = start1;if (end1 >= size || start2 >= size)break;while (end2 >= size)end2--;while (start1 <= end1 && start2 <= end2){if (arr[start1] <= arr[start2])tmp[j++] = arr[start1++];elsetmp[j++] = arr[start2++];}while (start1 <= end1){tmp[j++] = arr[start1++];}while (start2 <= end2){tmp[j++] = arr[start2++];}memmove(arr + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}free(tmp), tmp = NULL;
}
1.整体逻辑
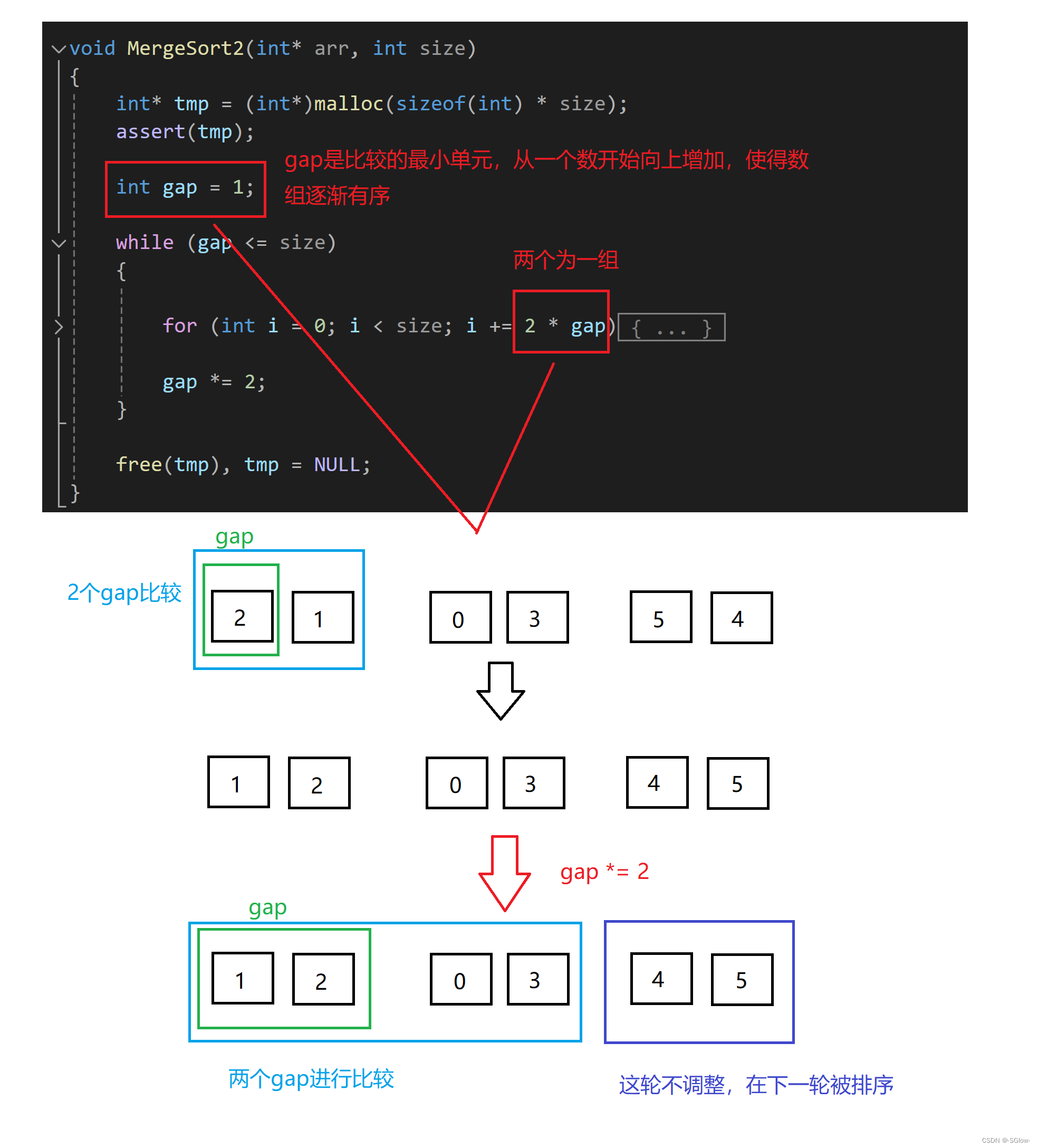
它的逻辑大体上和递归法相似,但非递归法是直接从最小元素开始向上归并。
2.非递归归并的难点在于数组前面归并是两两为一组,会导致有落单的情况,需要进行处理,上面这张图就展示出了一种情况,下面分析一下:

三、计数排序
这个排序非常简单,不做过多分析
代码实现:
void CountSort(int* arr, int size)
{int max = arr[0], min = arr[0];for (int i = 0; i < size; i++){if (arr[i] > max)max = arr[i];if (arr[i] < min)min = arr[i];}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));assert(count);for (int i = 0; i < size; i++){count[arr[i] - min]++;}for (int i = 0, j = 0; i < range; i++){while (count[i]--){arr[j++] = i + min;}}}注意这个方法用于数据集中时使用,这个时候效率很高。但分散数据就别用,会浪费大量空间。这个排序讨论其稳定性没有意义,因为它只能做到数值的排序,这些排序后没有意义。