用搜索引擎收集信息-常用方式
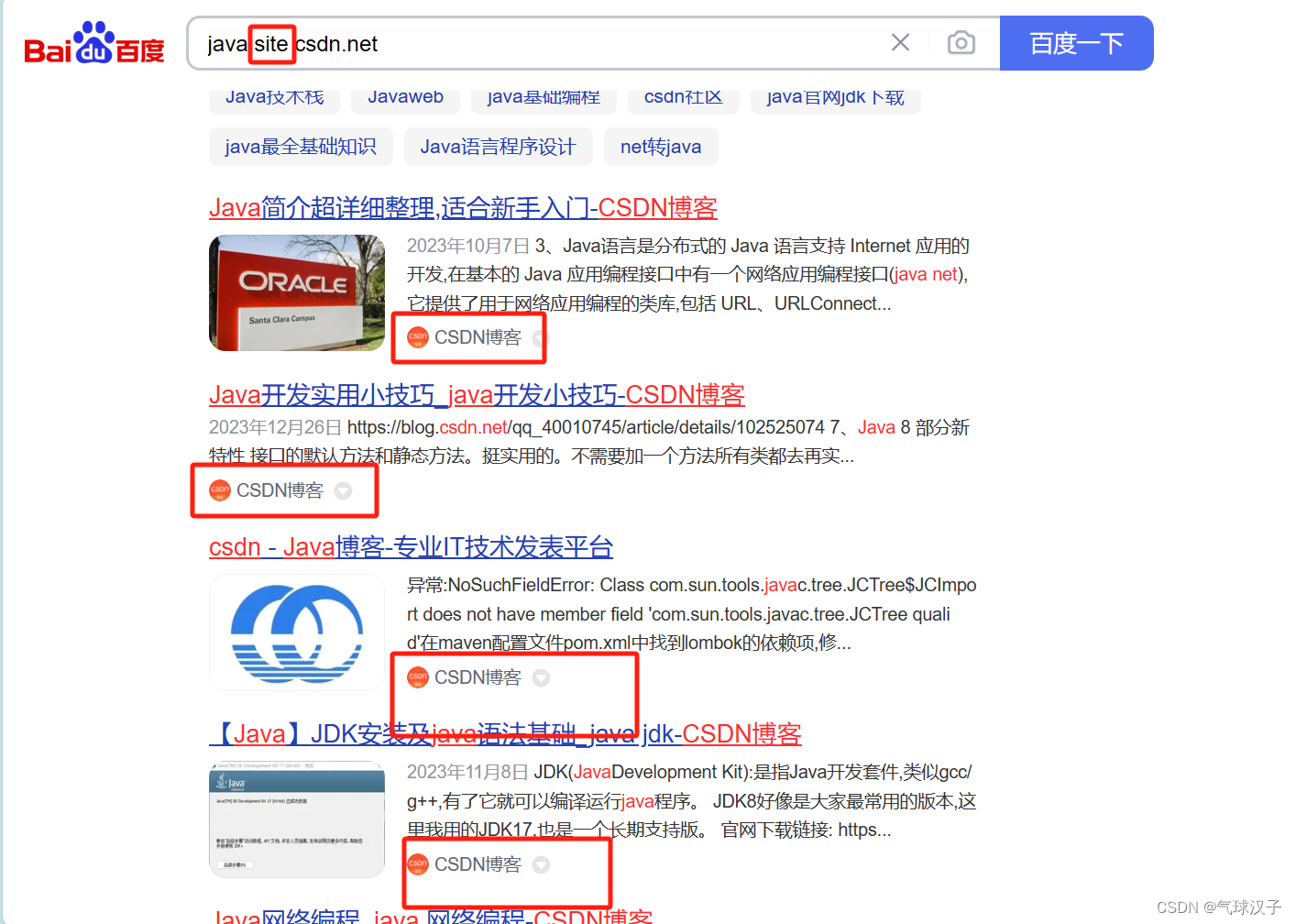
1,site csdn.net (下图表示只在csdn网站里搜索java)
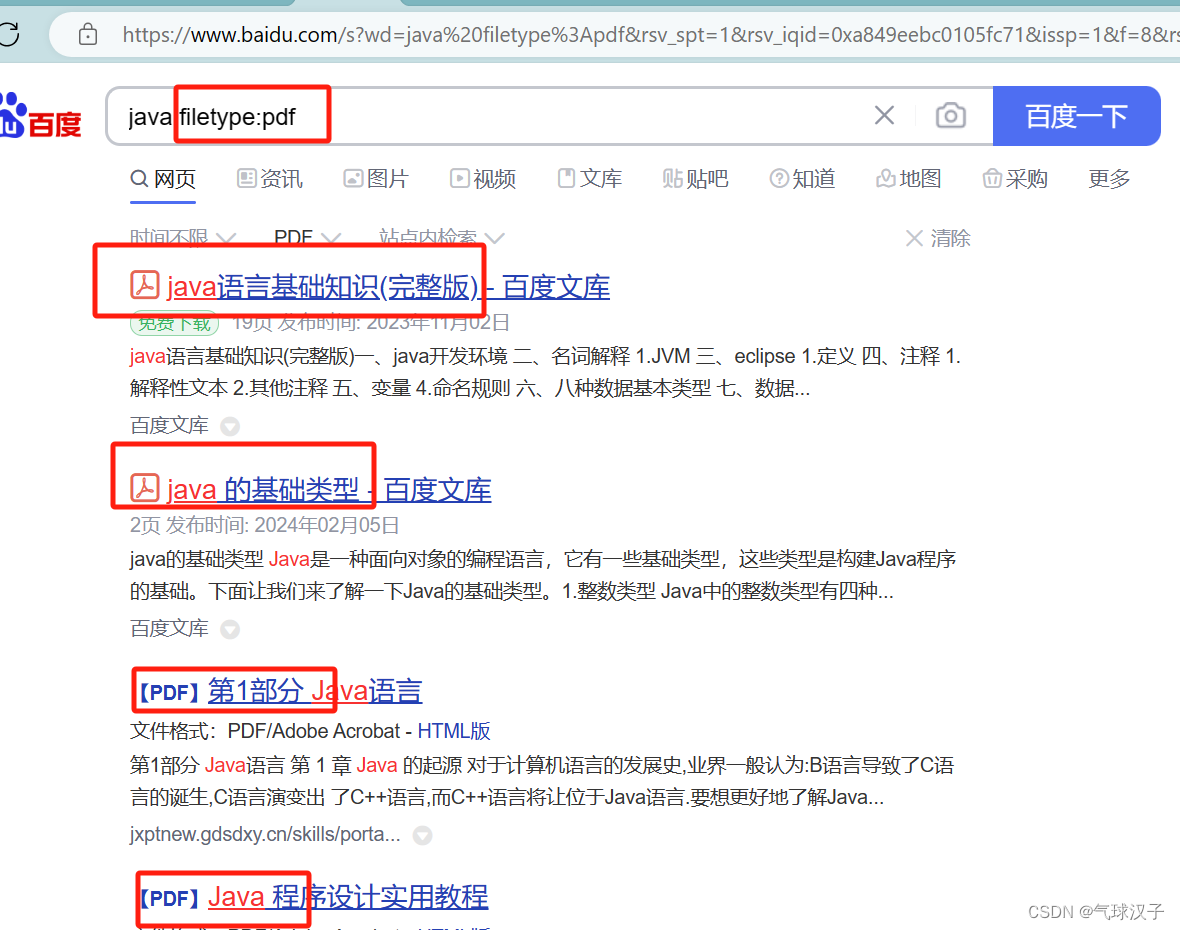
2,filetype:pdf (表示只检索某pdf文件类型)
表示在浏览器里面查找有关java的pdf文件
3,intitle:花花 (表示搜索网页标题里面有花花)
4,intext:Powered by Discuz(表示搜索网页正文里面有Powered by Discuz)
5,inurl:index.php?id=1(表示搜索网页连接里面有index.php?id=1)
1,site csdn.net (下图表示只在csdn网站里搜索java)
2,filetype:pdf (表示只检索某pdf文件类型)
表示在浏览器里面查找有关java的pdf文件
3,intitle:花花 (表示搜索网页标题里面有花花)
4,intext:Powered by Discuz(表示搜索网页正文里面有Powered by Discuz)
5,inurl:index.php?id=1(表示搜索网页连接里面有index.php?id=1)