【面试题】数据底层原理:Elasticsearch写入流程解析

前言:本篇博客将介绍Elasticsearch的数据底层原理,涉及数据写入的过程以及相关概念。我们将深入探讨buffer、translog、refresh、commit、flush和merge等核心概念,帮助您更好地理解Elasticsearch的数据存储机制。

写入数据的基本过程
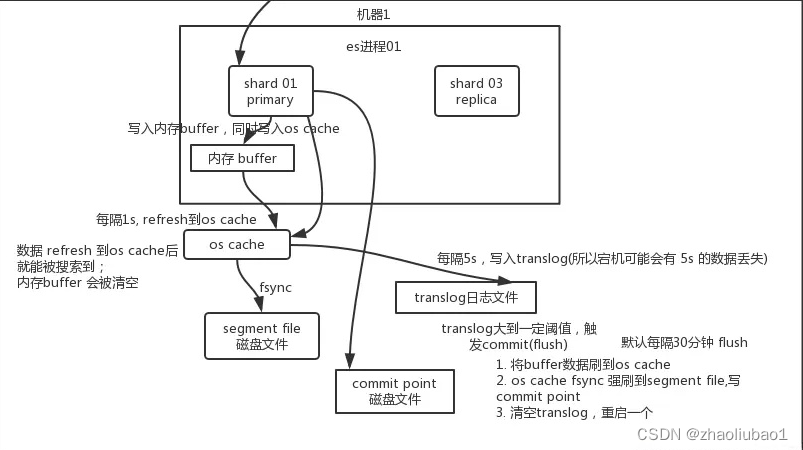
Elasticsearch是一个分布式搜索引擎,数据写入的基本过程如下:
-
数据首先被写入buffer,此时数据在buffer中是无法被搜索到的。同时,数据也会被写入translog日志文件,以实现数据的持久化。
-
当buffer快要写满或经过一定时间后,会执行refresh操作,将buffer中的数据刷新到一个新的segment文件中。这个刷新的过程实际上是将数据先写入操作系统缓存(os cache)中。每隔1秒钟,Elasticsearch将buffer中的数据写入一个新的segment文件,因此每秒钟会产生一个新的segment文件。如果buffer中没有数据,则不会执行refresh操作,仅会创建一个空的segment文件。只有当数据被刷新到os cache中,才能被搜索到。
-
一旦数据进入os cache,该segment文件中的数据就可以被搜索引擎提供给外部使用。
-
以上过程会不断重复进行,新的数据不断进入buffer和translog,并被写入一个又一个新的segment文件。每次refresh操作完成后,buffer会被清空,而translog保留。随着数据写入的推进,translog的大小会越来越大。当translog达到一定长度时,会触发commit操作。
-
在commit操作中,首先将buffer中的现有数据刷新到os cache中,然后清空buffer。
-
接下来,将一个commit point写入磁盘文件,其中包含了该commit point对应的所有segment文件。
-
最后,强制将os cache中的所有数据通过fsync操作刷写到磁盘文件中。

Translog日志文件的作用
Translog日志文件的作用是在执行commit操作之前,将数据写入专门的日志文件。无论数据是停留在buffer还是os cache中,都是存储在内存中的。一旦机器宕机,内存中的数据将会丢失。
为了防止数据丢失,需要将数据对应的操作写入translog日志文件。在机器重启时,Elasticsearch会自动读取translog日志文件中的数据,并恢复到内存的buffer和os cache中。

Commit操作和Flush操作
Commit操作是指:
- 写入commit point,用于标识该commit point所对应的所有segment文件。
- 将os cache中的数据通过fsync操作强制刷写到磁盘文件。
- 清空translog日志文件。
Flush操作是对应commit操作的全过程。通过手动执行Flush操作,可以将os cache中的数据通过fsync操作强制刷写到磁盘文件中,并记录一个commit point,同时清空translog日志文件。

删除操作和更新操作
- 删除操作:在执行commit操作时,会生成一个.del文件,其中标识某个文档为已删除状态。搜索时,根据.del文件可以知道该文档已被删除。
- 更新操作:将原始文档标识为已删除状态,然后写入新的数据。

Segment文件的管理与Merge操作
-
每次refresh操作会产生一个新的segment文件,因此默认情况下,每秒钟会创建一个新的segment文件。随着时间推移,segment文件会越来越多。为了优化性能,Elasticsearch会定期执行merge操作。
-
Merge操作将多个segment文件合并为一个,并压缩数据以减少磁盘空间的使用。合并后的segment文件可以提高搜索性能,减少磁盘的随机访问。
-
Merge操作分为两个阶段:合并(Merge)和删除(Delete)。
-
合并阶段:将多个segment文件合并为一个新的segment文件。在合并的过程中,相同文档ID的数据将会被合并为最新版本,删除标记将会被应用。合并操作会减少segment文件的数量,提高搜索性能。
-
删除阶段:在合并后的segment文件中,已被标记为删除的数据将会被真正地删除,释放磁盘空间。
-
-
Merge操作是一个耗时的过程,会占用CPU和磁盘IO资源。为了避免对搜索性能产生负面影响,Elasticsearch会在后台异步执行Merge操作。
-
Merge操作的频率和合并策略可以通过配置进行调整,以满足不同场景的需求。
这就是Elasticsearch数据写入的底层原理。通过理解这些核心概念,您可以更好地管理和优化Elasticsearch集群的性能和存储空间使用。
