HQL,SQL刷题,尚硅谷
目录
相关表数据:
题目及思路解析:
多表连接
1、课程编号为"01"且课程分数小于60,按分数降序排列的学生信息
2、查询所有课程成绩在70分以上 的学生的姓名、课程名称和分数,按分数升序排列
3、查询该学生不同课程的成绩相同的学生编号、课程编号、学生成绩
4、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
5、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
6、查询学过 “李体音”老师所教的所有课的同学的学号、姓名
7、查询学过“李体音”老师所讲授的任意一门课程的学生的学号、姓名
8、查询没学过"李体音"老师讲授的任一门课程的学生姓名
9、查询至少有一门课与学号为“001”的学生所学课程相同的学生的学号和姓名
10、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
编辑
总结归纳:
知识补充:
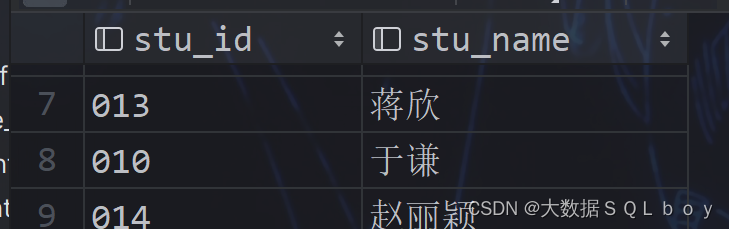
相关表数据:
- Score_info表
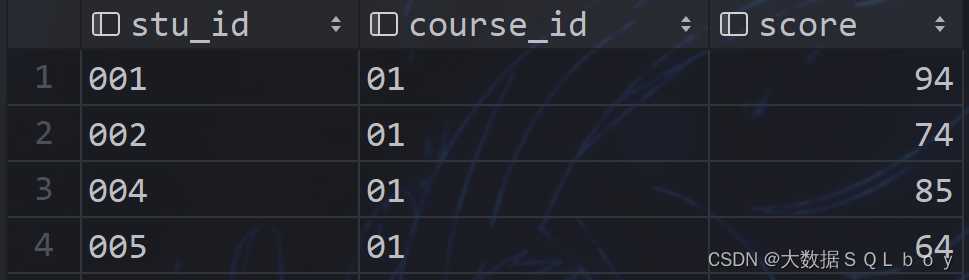
2、Student_info表

3、Course_info表

4、Teacher_info 表

题目及思路解析:
多表连接
1、课程编号为"01"且课程分数小于60,按分数降序排列的学生信息
代码:
selectst.stu_id,stu_name,birthday,gender,score
from student_info st
join score_info sc on st.stu_id=sc.stu_id
where course_id='01'and score<60
order by score desc;
思路分析:
这道题没什么特别的,就是简单join连接查询,不过结果显示可以加上成绩,可能比较好看点
结果:

2、查询所有课程成绩在70分以上 的学生的姓名、课程名称和分数,按分数升序排列
链接 :HQL,SQL刷题,尚硅谷-CSDN博客
3、查询该学生不同课程的成绩相同的学生编号、课程编号、学生成绩
代码:
selectsc1.stu_id,sc1.scorefrom score_info sc1inner join score_info sc2 on sc1.stu_id=sc2.stu_idwhere sc1.course_id !=sc2.course_id and sc1.score=sc2.score;思路分析:
这道题主要是内连接,需要两张相同的表(简单理解为自己连自己),横向拼接,两张表对比找出不同课程的,然后同时成绩相同的学生成绩
结果:

4、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
注意:这里隐含条件是两门课程都选修的学生
这道题目意思是在选修两门课程的学生中,课程01成绩比02课程高的学生
代码1:
selectsc1.stu_idfrom score_info sc1join score_info sc2 on sc1.stu_id =sc2.stu_idwhere sc1.course_id='01' and sc2.course_id='02'and sc1.score>sc2.score;代码2:
selects1.stu_id
from
(selectsc1.stu_id,sc1.course_id,sc1.scorefrom score_info sc1where sc1.course_id ='01'
) s1
join
(selectsc2.stu_id,sc2.course_id,scorefrom score_info sc2where sc2.course_id ="02"
)s2
on s1.stu_id=s2.stu_id
where s1.score > s2.score;思路分析:
这道题还行,主要是题目开始理解错了,题目意思不太明确。
代码1和代码2主要区别是代码2 join之前进行子查询
主要也是内连接,自己连自己,然后按照条件筛选
注意:代码1比较简洁,但是在大数据场景下,特别是数据量比较大的时候,应选择代码2
结果:

5、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
代码1:
selectsc1.stu_id as `学号`,stu_name as `姓名`from score_info sc1join score_info sc2 on sc1.stu_id=sc2.stu_idleft join student_info st on st.stu_id=sc1.stu_idwhere sc1.course_id ="01" and sc2.course_id='02';代码2:
selectt1.stu_id as `学号`,s.stu_name as `姓名`
from
(selectstu_idfrom score_info sc1where sc1.course_id='01'and stu_id in (selectstu_idfrom score_info sc2where sc2.course_id='02')
)t1
join student_info s
on t1.stu_id = s.stu_id;思路分析:
代码1 和代码2主要的不同在于,代码1使用join连接,而代码2是通过子查询
代码1是通过内连接,自己连接自己,然后筛选出同时选修两门课程的学生
代码2是先查询选修课程2的学生,在此基础上,通过stu_id连接,筛选也选修了课程1的学生
注意:SQL文基本没什么区别,但在大数据场景下应当选择Join的(即选择代码2)
结果:

下面三题就比较有意思了,而且关联性较强
6、查询学过 “李体音”老师所教的所有课的同学的学号、姓名
HQL,SQL刷题,尚硅谷-CSDN博客
7、查询学过“李体音”老师所讲授的任意一门课程的学生的学号、姓名
HQL,SQL刷题,尚硅谷-CSDN博客
8、查询没学过"李体音"老师讲授的任一门课程的学生姓名
HQL,SQL刷题,尚硅谷-CSDN博客
9、查询至少有一门课与学号为“001”的学生所学课程相同的学生的学号和姓名
代码:
selectsc.stu_id,stu_name
from score_info sc
left join juntest.student_info si on sc.stu_id = si.stu_id
where sc.stu_id <>'001' and course_id in(selectcourse_idfrom score_infowhere stu_id ='001'
)
group by sc.stu_id, stu_name;思路分析:
这道题比较普通,先子查询得到001学生的选修课程,接着在此基础上外面查询筛选课程号在001学生的选修课程之中的学生。
稍微需要注意的是,子查询结果是多个因此用 in,然后外面查询记得学生号不等于001(即排除掉001学生)
结果:
10、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
注意:这里的平均成绩是学生所有课程的总成绩的平均成绩
代码:
selectsi.stu_name,ci.course_name,sc.score,t1.avg_score
from score_info sc
join student_info si
on sc.stu_id=si.stu_id
join course_info ci
on sc.course_id=ci.course_id
join
(selectstu_id,avg(score) avg_scorefrom score_infogroup by stu_id
)t1
on sc.stu_id=t1.stu_id
order by t1.avg_score desc;思路分析:
这道题关键在Join子查询部分,子查询部分是用来求平均成绩的,如果在最外层就求平均成绩求出来的是每个科目的平均成绩,因此需要加个子查询。
另外,这里可能有同学觉得子查询用了score_info表,Join连接又使用score_info表,太过于冗余,可不可以直接用子查询作为主表(即from 子查询),这里与上面的第二道题类似,是不可以的。
结果:

总结归纳:
1、考察多表连接使用,以及与子查询结合使用
2、在大数据场景下,join连接往往意味着需要shuffle,落盘
因此Join越多,计算、查询性能越差
3、在大数据场景下,先子查询在Join ,
一方面可以减少join时候的数据量,提高计算效率,
另一方面是子查询可以类似spark checkpoint,在执行数据计算时候出现中间数据丢 失时候,可以保存计算中间临时结果
4、另外,要仔细理解题目意思
知识补充:
1、表示不等于符合,<> 、!=
2、在外查询与子查询连接中,子查询返回结果为一个则可以使用=,>,<等,若是返回多个则使用in,not in等
3、---关于sum(if())函数
sum(if():有条件累加,常用于分类筛选统计
sum(if)只试用于单个条件判断,如果筛选条件很多,我们可以用sum(case when then else end)来进行多条件筛选注意,hive中并没有sum(distinct col1)这种使用方式,我们可以使用sum(col) group by col来达到相同效果.
4、goup by 分组聚合可以起到去重的作用