毕业设计:日志记录编写(3/17起更新中)
目录
- 3/17
- 1.配置阿里云python加速镜像:
- 2. 安装python3.9版本
- 3. 爬虫技术选择
- 4. 数据抓取和整理
- 5. 难点和挑战
- 3/24
- 1.数据库建表信息
- 2.后续进度安排
- 3. 数据处理和分析
3/17
当前周期目标:构建基本的python环境:运行爬虫程序
1.配置阿里云python加速镜像:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
安装chrome驱动到python安装目录下
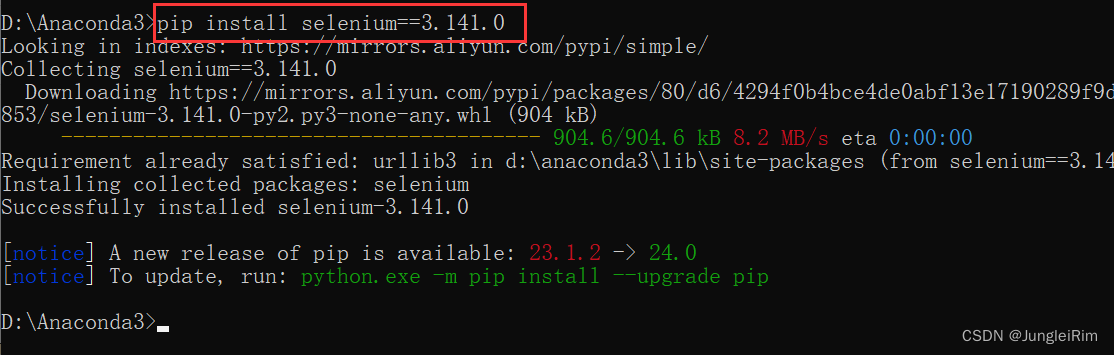
2. 安装python3.9版本
3. 爬虫技术选择
爬虫技术是采集数据的主要手段之一。以下是一些常用的爬虫技术:
Requests + Beautiful Soup: 对于静态网页,使用 Python 的 Requests 库获取网页源代码,然后使用 Beautiful Soup 解析数据。
Scrapy: 对于动态网页或需要大规模数据采集的情况,可以考虑使用 Scrapy 框架,它提供了强大的爬虫功能和数据处理能力。
Selenium: 如果需要模拟用户操作,比如登录或者触发 JavaScript 事件,可以使用 Selenium 这样的工具。
4. 数据抓取和整理
针对短视频平台的数据采集,你可能需要考虑以下内容:
视频信息: 包括标题、描述、发布时间、观看次数、点赞数、评论数等。
评论信息: 获取视频的评论内容、评论者的信息(如用户名、头像、粉丝数等)以及评论时间等。
用户信息: 可能需要获取用户的基本信息和行为数据,比如关注数、粉丝数、发布的视频数量等。
5. 难点和挑战
反爬虫机制: 很多网站会有反爬虫机制,你可能需要应对验证码、IP 封锁等问题。
数据量和频率限制: 确保你的爬虫不会给目标网站造成过大的负担,遵守网站的访问频率限制。
数据存储和处理: 采集到的数据可能会很庞大,你需要考虑如何高效地存储和处理这些数据,以及如何建立合适的数据库结构。
3/24
周期目标:编写运行爬虫程序,拿到抖音用户和评论数据,并持久化存入MySQL:
1.数据库建表信息
创作者视频信息表设计:
CREATE TABLE douyin_aweme (id INT PRIMARY KEY AUTO_INCREMENT, -- 自增IDuser_id VARCHAR(64), -- 用户IDsec_uid VARCHAR(128), -- 用户sec_uidshort_user_id VARCHAR(64), -- 用户短IDuser_unique_id VARCHAR(64), -- 用户唯一IDnickname VARCHAR(64), -- 用户昵称avatar VARCHAR(255), -- 用户头像地址user_signature VARCHAR(500), -- 用户签名ip_location VARCHAR(255), -- 评论时的IP地址add_ts BIGINT, -- 记录添加时间戳last_modify_ts BIGINT, -- 记录最后修改时间戳aweme_id VARCHAR(64), -- 视频IDaweme_type VARCHAR(16), -- 视频类型title VARCHAR(500), -- 视频标题`desc` TEXT, -- 视频描述create_time BIGINT, -- 视频发布时间戳liked_count VARCHAR(16), -- 视频点赞数comment_count VARCHAR(16), -- 视频评论数share_count VARCHAR(16), -- 视频分享数collected_count VARCHAR(16), -- 视频收藏数aweme_url VARCHAR(255) -- 视频详情页URL
);
普通用户评论信息表设计:
CREATE TABLE douyin_aweme_comment (id INT PRIMARY KEY AUTO_INCREMENT, -- 自增IDuser_id VARCHAR(64), -- 用户IDsec_uid VARCHAR(128), -- 用户sec_uidshort_user_id VARCHAR(64), -- 用户短IDuser_unique_id VARCHAR(64), -- 用户唯一IDnickname VARCHAR(64), -- 用户昵称avatar VARCHAR(255), -- 用户头像地址user_signature VARCHAR(500), -- 用户签名ip_location VARCHAR(255), -- 评论时的IP地址add_ts BIGINT, -- 记录添加时间戳last_modify_ts BIGINT, -- 记录最后修改时间戳comment_id VARCHAR(64), -- 评论IDaweme_id VARCHAR(64), -- 视频IDcontent TEXT, -- 评论内容create_time BIGINT, -- 评论时间戳sub_comment_count VARCHAR(16) -- 评论回复数
);2.后续进度安排
1.编写后端程序,进行分模块管理
2.将目前拿到的实验数据(视频信息38条,用户评论信息1000条)进行数据清洗
3.构思后端逻辑
4.前端UI设计



3. 数据处理和分析
采集到的数据可能需要进行清洗、去重、分析等处理,以便后续的应用。你可以考虑使用 Pandas、NumPy、或者其他数据处理工具进行数据分析和挖掘。