ETL的全量和增量模式
在当今信息爆炸的时代,数据管理已经成为各行各业必不可少的一环。而在数据管理中,全量与增量模式作为两种主要的策略,各自具有独特的优势和适用场景,巧妙地灵活运用二者不仅能提升数据处理效率,更能保障数据的准确性。
一、ETL同步方式详解
1.全量同步:
优势:全量同步可以确保目标系统中的数据与源系统完全一致,适用于需要定期将所有数据进行同步的场景。
缺点:
数据量大:全量同步需要传输大量数据,可能会占用较多的网络带宽和时间。
频繁同步困难:如果数据量巨大,频繁进行全量同步可能不太实际。
适用场景:
初次数据迁移:在初次迁移数据或初始化目标系统时,通常需要进行全量同步。
数据完整性要求高:对数据完整性要求高、不允许出现丢失任何数据的情况下,通常会选择全量同步。
2.增量同步:
优势: 增量同步只传输自上次同步以来发生变化的数据,节约了传输成本和时间,适用于频繁更新的场景。
缺点:
初始同步复杂:进行初始同步时,需要先进行一次全量同步,然后才能切换到增量同步模式。
可能出现数据漏同步:增量同步需要准确记录同步的位置,否则可能出现数据遗漏或重复同步的情况。
适用场景:
实时数据同步:对实时性要求高,需要及时将变化的数据同步到目标系统的场景。
节约网络资源:在网络资源有限的情况下,增量同步可以减少数据传输量,节约网络带宽。
二、ETLCLoud同步案例
ETL的全量同步场景案例设计:整库同步
1.流程设计
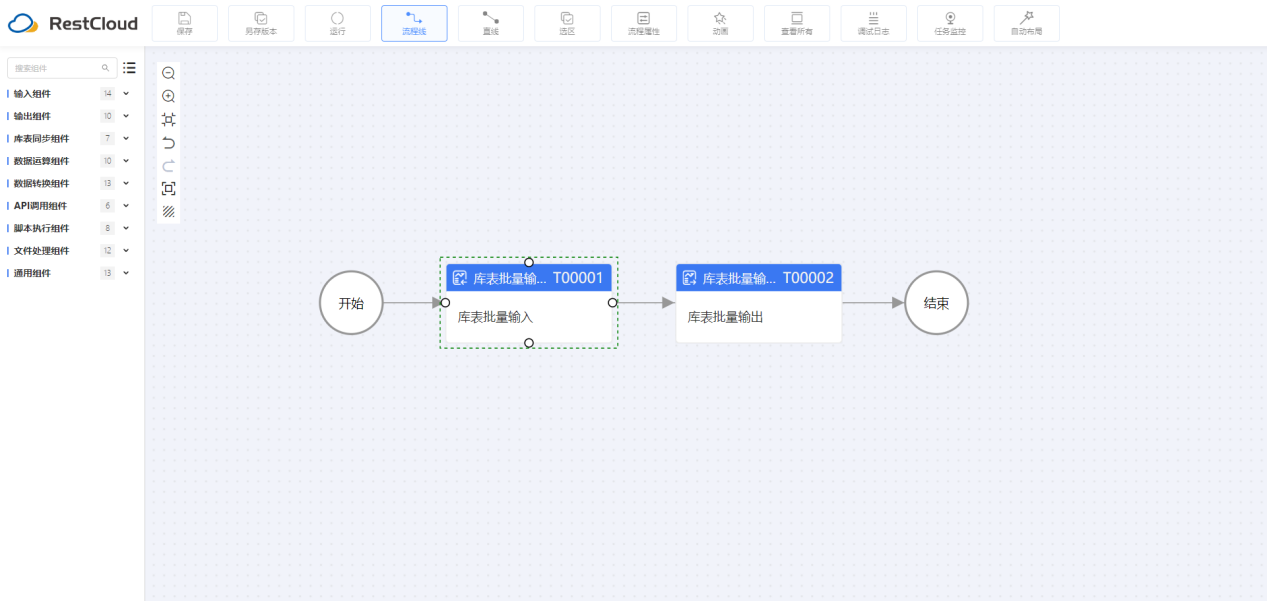
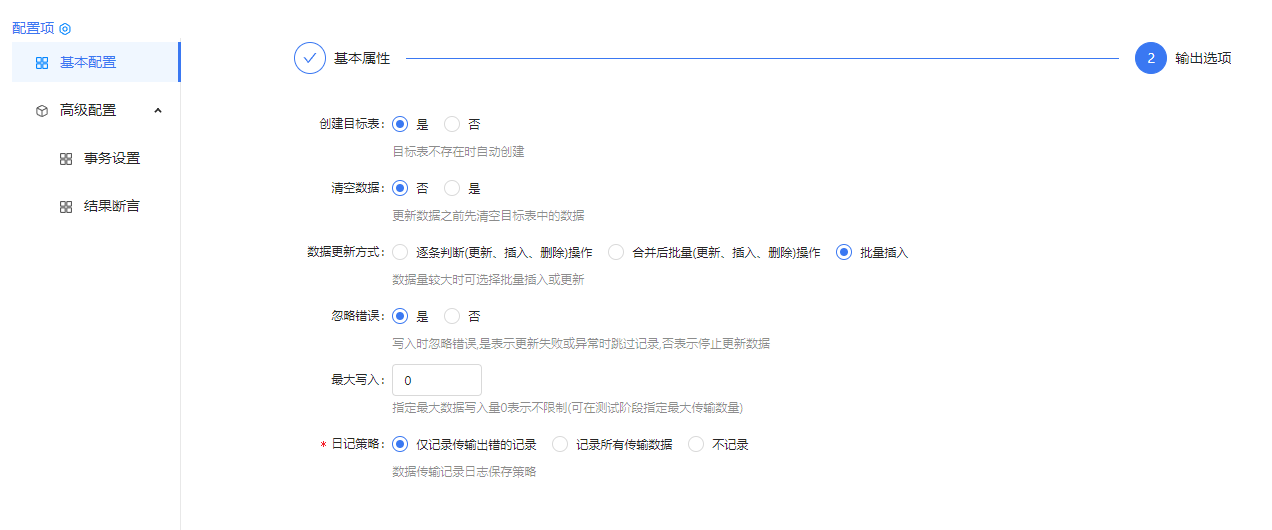
2.组件配置



3.同步结果

ETL增量模式同步场景案例设计:表增量同步
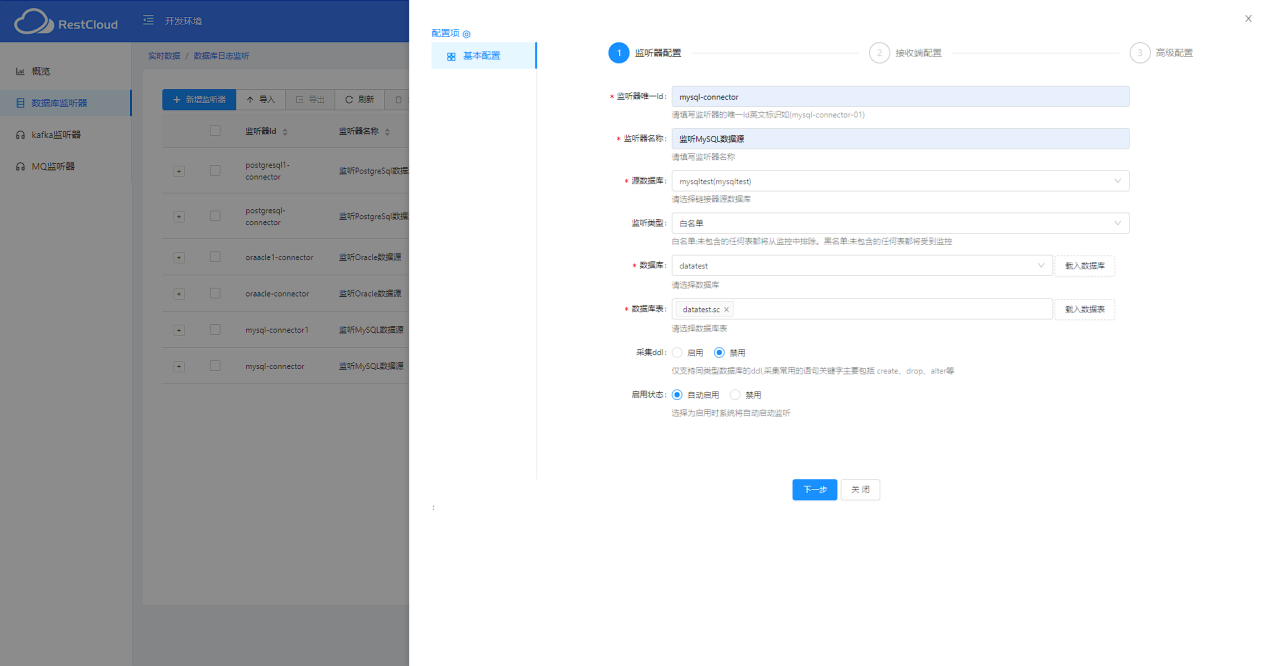
1.创建数据监听器

2.配置数据监听器


3.启动同步任务

4.监控同步任务
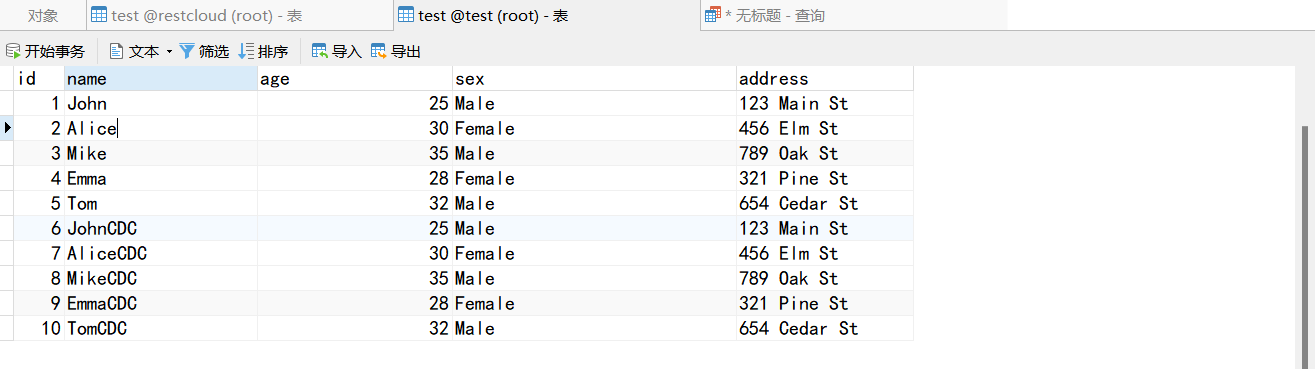
使用Navicat查看源表数据(restcloud.test)

使用Navicat查看目标表数据(test.test)

执行插入语句

监控面板统计图

再次使用Navicat查看源表数据(restcloud.test)

目标表数据(test.test)
三、总结
在实际应用中,ETLCloud的全量和增量模式可以根据业务需求灵活切换和组合使用,以达到最佳的数据处理效果。例如,在数据初始化阶段可以使用全量模式进行数据同步,确保数据的完整性;而在日常数据同步过程中,则可以采用增量模式,提高数据处理的效率。全量和增量模式各有优势,可以根据具体情况选择合适的模式或结合两者,从而实现高效、稳定的数据处理和管理。