爬虫 Day2
resp.close()#关掉resp
一requests入门
(一) 用到的网页:豆瓣电影分类排行榜 - 喜剧片
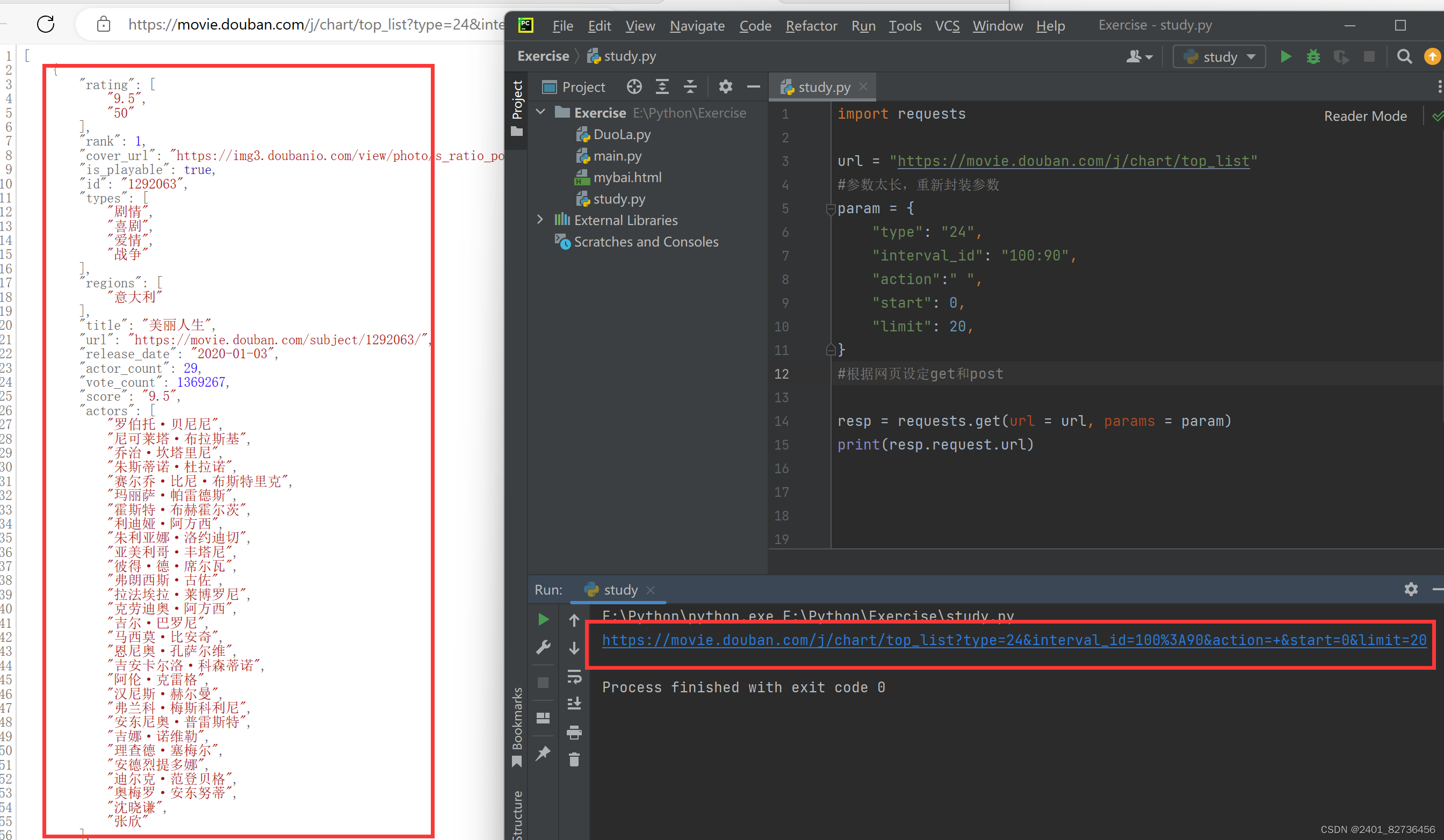
import requestsurl = "https://movie.douban.com/j/chart/top_list"
#参数太长,重新封装参数
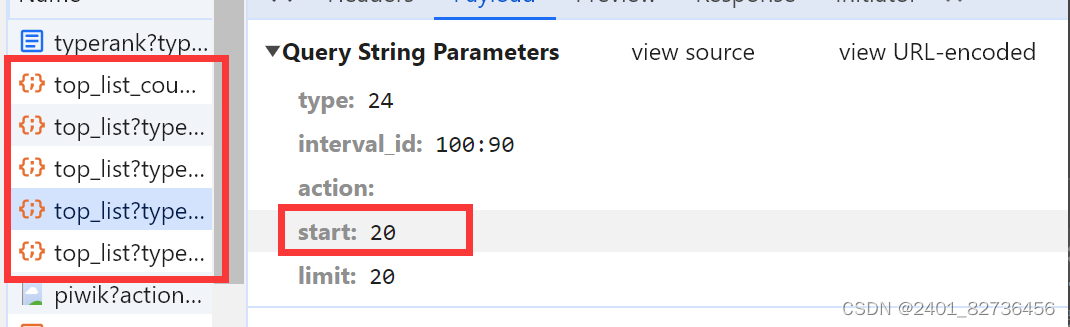
param = {"type": "24","interval_id": "100:90","action":" ","start": 0,"limit": 20,
}
#根据网页设定get和postresp = requests.get(url = url, params = param)
print(resp.request.url)
#text 抓取不下来
#print(resp.text)
抓取结果:
(二)反爬
import requestsurl = "https://movie.douban.com/j/chart/top_list"
#参数太长,重新封装参数
param = {"type": "24","interval_id": "100:90","action":" ","start": 0,"limit": 20,
}
#根据网页设定get和post
#text 直接抓取不下来,要换headers
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
resp = requests.get(url = url, params = param,headers = headers)
print(resp.json())
# print(resp.text)
resp.close()#关掉resp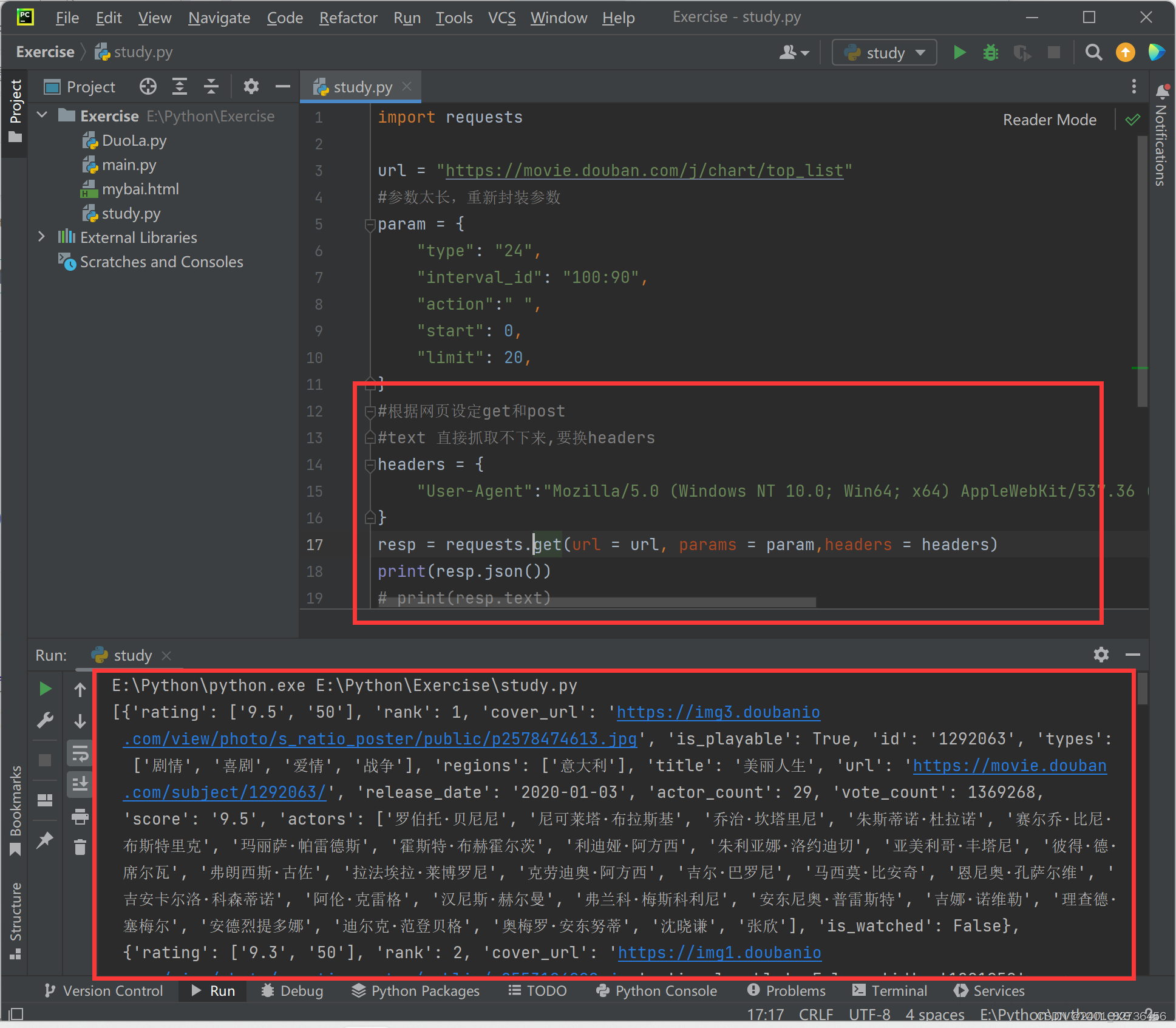
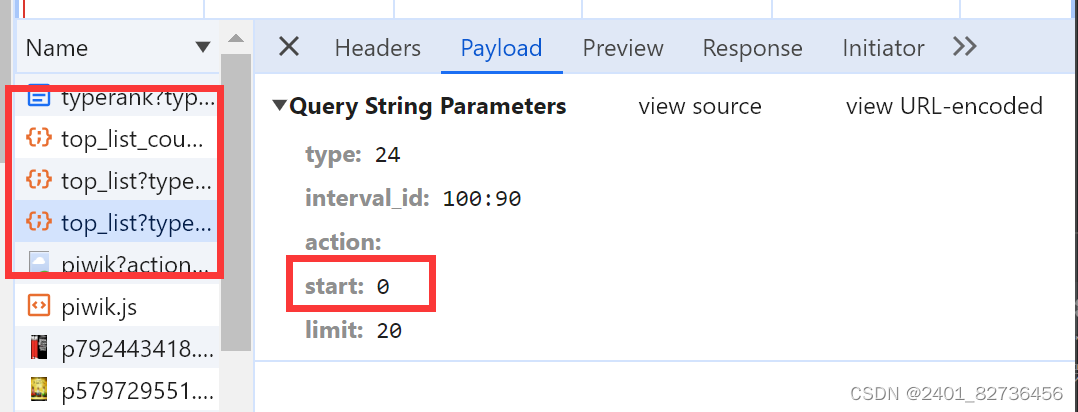
注意到每次下滑刷新榜单只有start参数改变,20递增
二从html里提取数据--数据解析
1.正则re解析--效率高
2.bs4 beautiful soup解析--效率不高
3.xpath解析--简洁
1.正则解析
. 匹配换行符之外的所有
\w 匹配数字、字母、下划线 \W非数字、字母、下划线
\s 匹配任意空白符 \S
\d 匹配任意数字 \D
\n 匹配换行符
\t 匹配制表符
^ 开始
$ 结束
a | b 匹配字符a或b
[] 字符组 [a-zA-Z0-9],
[^] 非字符组
* 重复0零次或更多次
+ 重复一次或更多次
? 重复0次或1次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
例:你玩儿什么游戏,矿工游戏你会吗,晚上一起玩游戏吧
惰性匹配:尽可能多的匹配):玩儿.*?游戏 : 玩儿什么游戏
贪婪匹配:玩儿.*游戏 :玩儿什么游戏,矿工游戏你会吗,晚上一起玩游戏

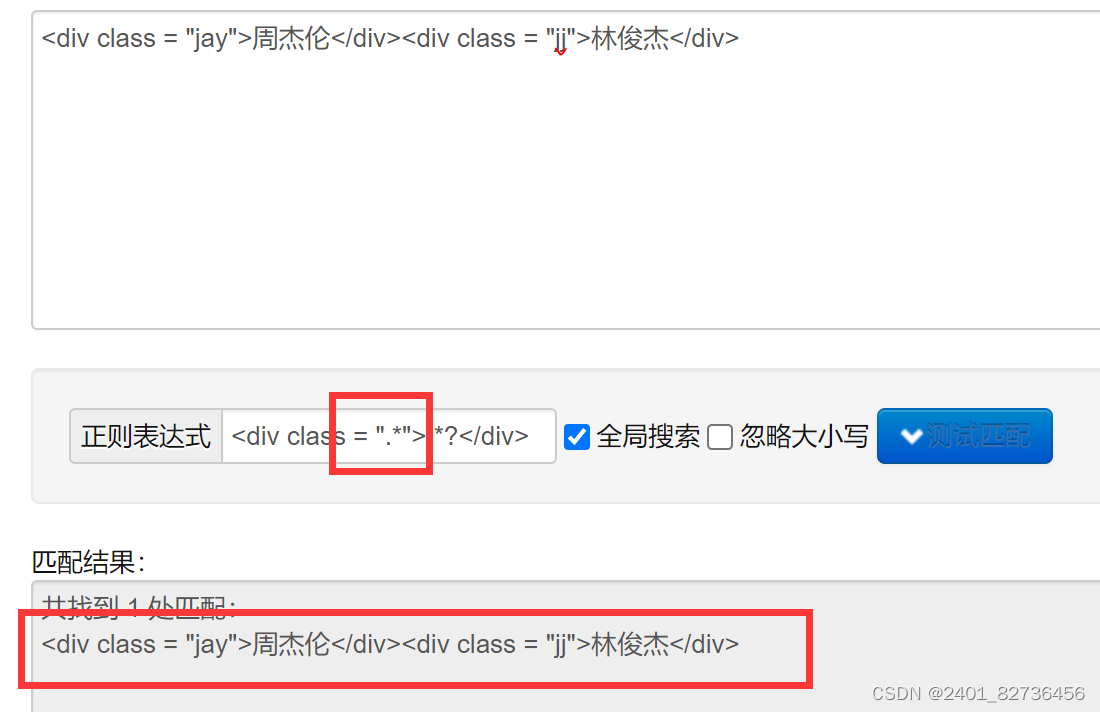
但我们需要的只是“周杰伦”和“林俊杰”。
2.示例
import re
#findall的结果是列表
#匹配字符串中所有符合正则的内容
lst = re.findall(r"\d+","我的电话是10010,我朋友的电话是10086")
print(lst)
print("")
#finditer: 匹配字符串中的所有内容【返回的是迭代器】,从迭代器中拿内容需要.group
it = re.finditer(r"\d+","我的电话是10010,我朋友的电话是10086")
for i in it:print(i.group())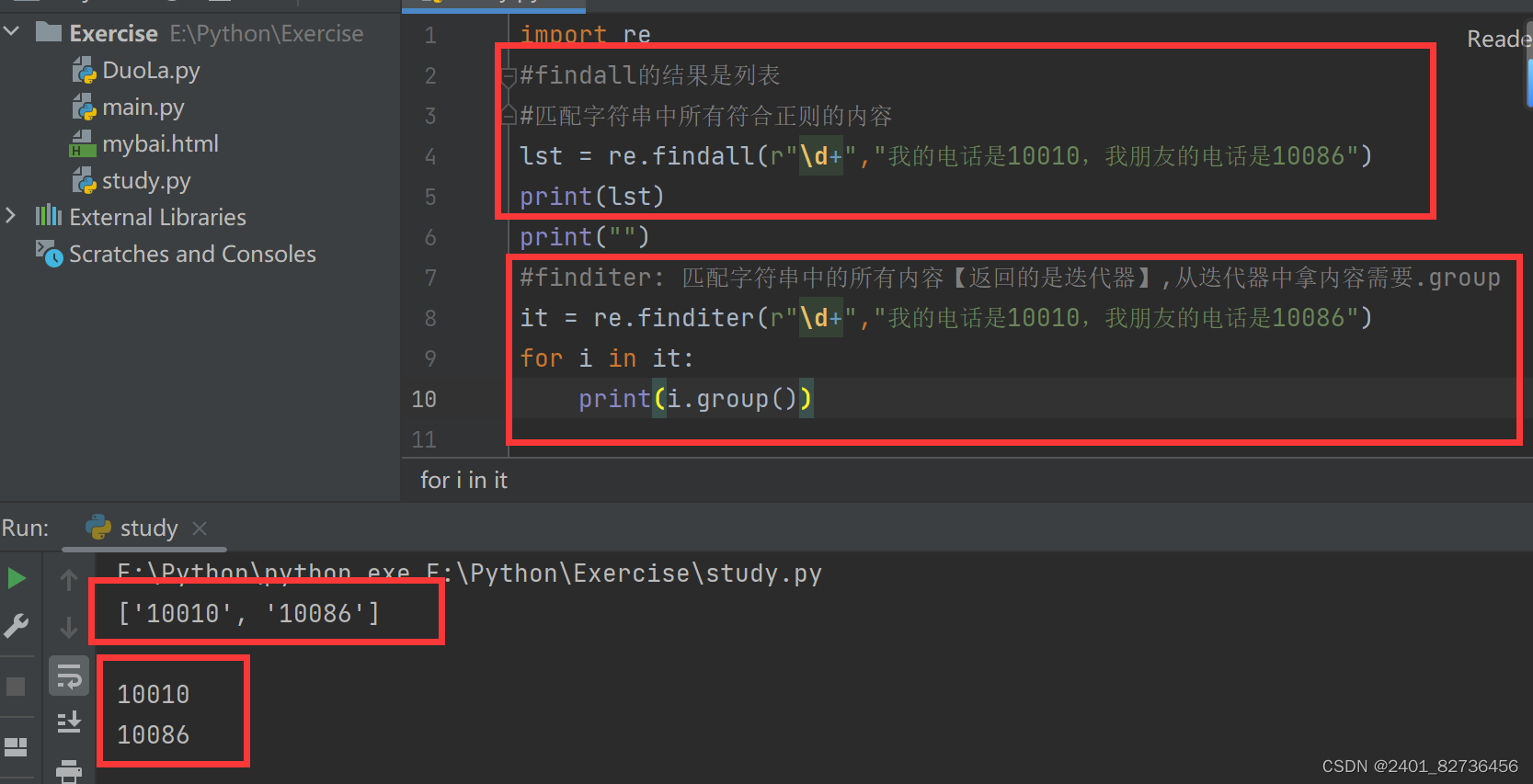
示例2:
findall
finditer
search
match
compile
import re
print("#findall的结果是列表")
#findall的结果是列表
#匹配字符串中所有符合正则的内容
lst = re.findall(r"\d+","我的电话是10010,我朋友的电话是10086")
print(lst)
print("")
print("#finditer: ")
#finditer: 匹配字符串中的所有内容【返回的是迭代器】,从迭代器中拿内容需要.group()
it = re.finditer(r"\d+","我的电话是10010,我朋友的电话是10086")
for i in it:print(i.group())
print("")
print("#serch:检索到一个就返回,检验存在性")
#serch是全文匹配返回的是match对象,拿数据需要.group(),检索到一个就返回,检验存在性
s = re.search(r"\d+","我的电话是10010,我朋友的电话是10086")
print(s.group())
print("")
print("#match是从头开始匹配")
#match是从头开始匹配
s = re.match(r"\d+","10010,我朋友的电话是10086")#"我的电话是10010,我朋友的电话是10086"
print(s.group())
print("")
print("#预加载正则表达式")
#预加载正则表达式
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话是10010,我朋友的电话是10086")
print("#这里输出的还是迭代器")#这里输出的还是迭代器
print(ret)
print("用迭代器输出:")
for i in ret:print(i.group())
print("#match:")
ans = obj.match("10010,我朋友的电话是10086")
print(ans.group())
# obj.search()
# obj.findall()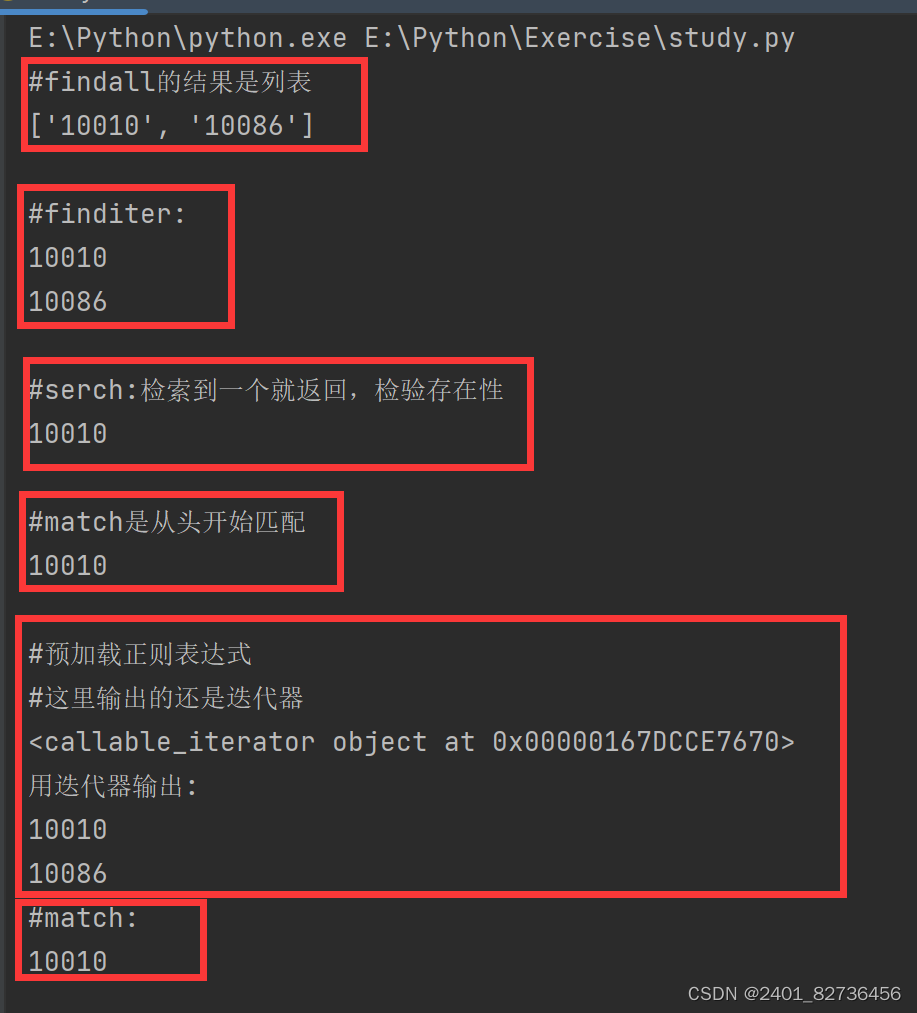
示例3:
import re
s ="""<div class='jay'><span id = '1'>周杰伦</span><div><div class='Ang'><span id = '2'>杨异或</span><div><div class='jjaa'><span id = '3'>林经济</span><div><div class='yja'><span id = '4'>周伦</span><div><div class='may'><span id = '5'>五樱桃</span><div>
"""
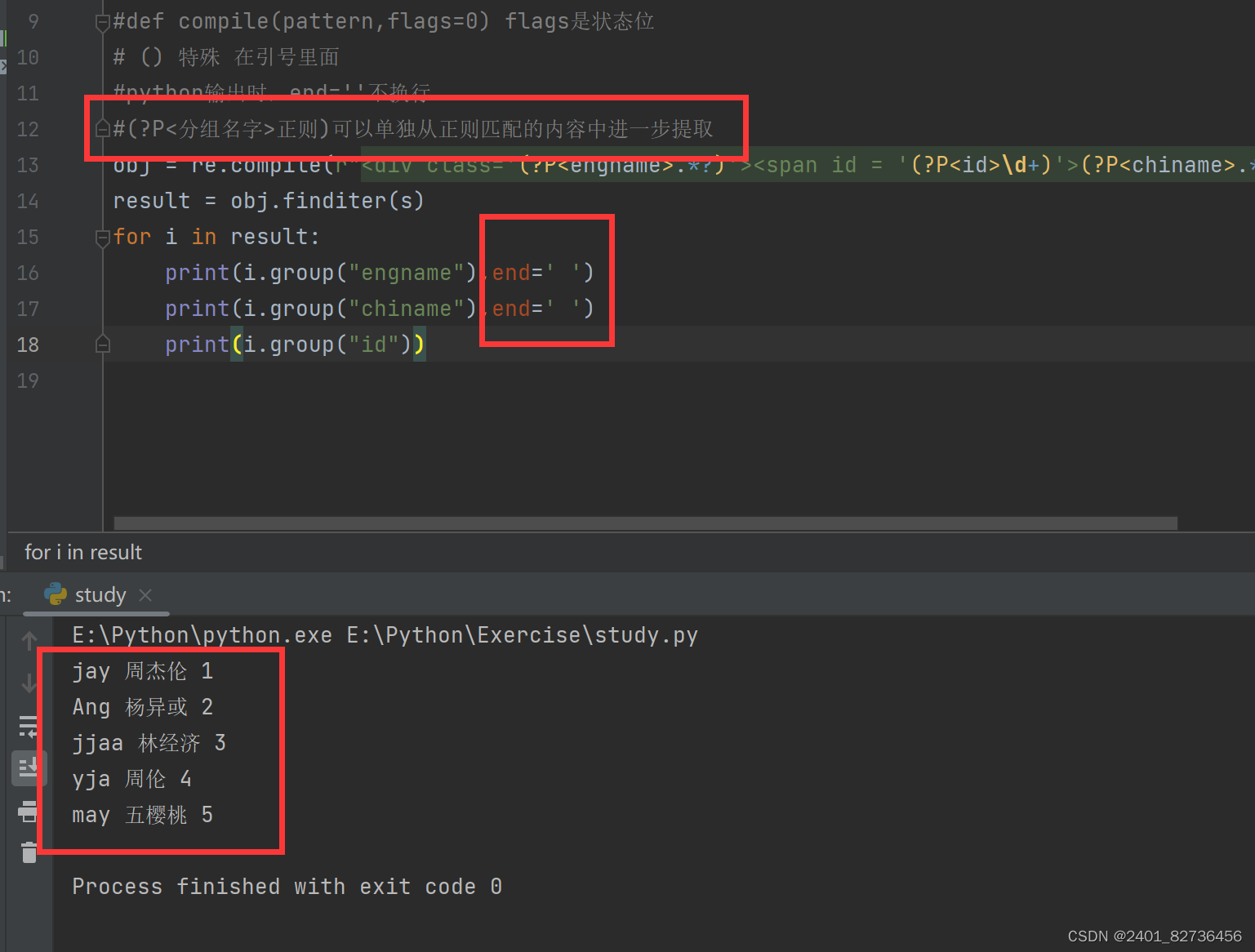
#def compile(pattern,flags=0) flags是状态位
# () 特殊 在引号里面
#python输出时,end=''不换行
#(?P<分组名字>正则)可以单独从正则匹配的内容中进一步提取
obj = re.compile(r"<div class='(?P<engname>.*?)'><span id = '(?P<id>\d+)'>(?P<chiname>.*?)</span><div>",re.S) #让.能匹配换行符
result = obj.finditer(s)
for i in result:print(i.group("engname"),end=' ')print(i.group("chiname"),end=' ')print(i.group("id"))