自然语言处理里预训练模型——BERT
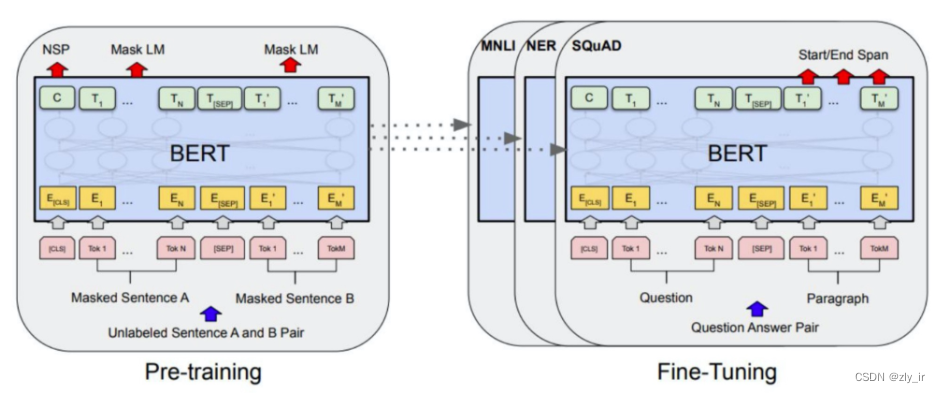
BERT,全称Bidirectional Encoder Representation from Transformers,是google在2018年提出的一个预训练语言模型,它的推出,一举刷新了当年多项NLP任务值的新高。前期我在零、自然语言处理开篇-CSDN博客 的符号向量化一文中简单介绍过其原理,今天我将更加详细的介绍下其工作流程。
零、BERT模型架构
当前的语言模型主要分为两种:
一种是自回归(Auto-Regressive)语言模型,Aotoregressive Lanuage Modeling,自回归语言模型:根据前面(或后面)出现的token来预测当前时刻的token,代表模型有ELMO、GTP(transformer中的decode解码器结构)(等,它一般采用生成类任务做预训练,类似于我们写一篇文章,自回归语言模型更擅长做生成类任务(Natural Language Generating,NLG),例如文章生成等。
另一种是自编码(Auto-Encoding)语言模型,Autoencoding Language Modeling,自编码语言模型:通过上下文信息来预测当前被mask的token,代表有BERT、Word2Vec(CBOW)等.它使用MLM做预训练任务,自编码预训模型往往更擅长做判别类任务,或者叫做自然语言理解(Natural Language Understanding,NLU)任务,例如文本分类,NER等。训练过程类似于做完形填空,下面会介绍到。
BERT模型采用的是transformer里的encode编码器的结构,它的模型总体结构如下:
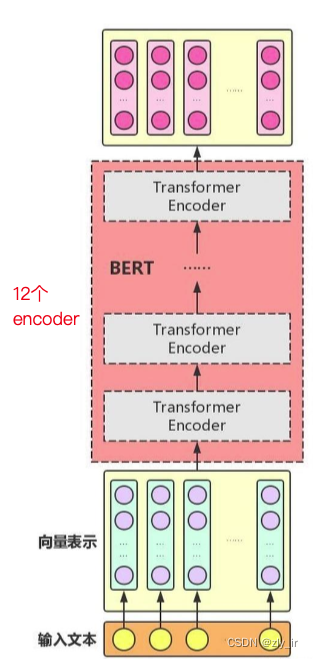
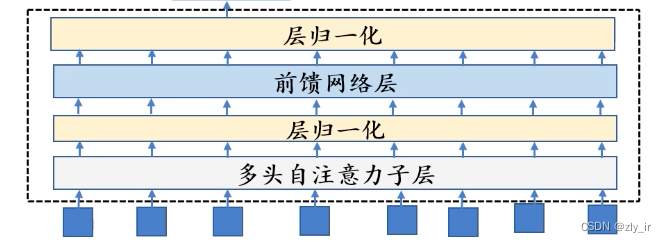
每一个transformer encode结构如下:
一、BERT的训练流程
1.0 BERT的输入
BERT的输入是一个长度为n的输入序列(n表示词组个数,token数),一般是512,通常包含下面三个部分:
(1)Token Embeddings:采用wordpiece对文本进行切割成一个个子词,经过embedding后每一个子词输出为768维的向量 (1, n, 768)。此层的tokenization使用的方法是WordPiece tokenization,将词转换为one hot编码,再经过embedding层,转换成768维向量。
(2)Segment Embeddings:切割句子用的(1, n, 768),相比transformer,这个是新增的。
(3)Position Embeddings:用于标记词在句子中的位置,(1, n, 768),使用的是cos和sin的固定位置标记法。
整个输入是一个1*512*768的张量。

对于输入的句子,将进行以下两个预训练任务。
1.1 BERT主要包含两个训练任务
1、 随机掩码训练任务:
(1)随机地将一句话里的某个单词替换成<mask>,输入到N层的transformer encode编码器里。
(2)将<mask>的隐层状态输入到softmax中进行预测,输出预测的单词结果。
(3)将预测得到的单词结果和原始数据中单词计算交叉熵,更新参数。
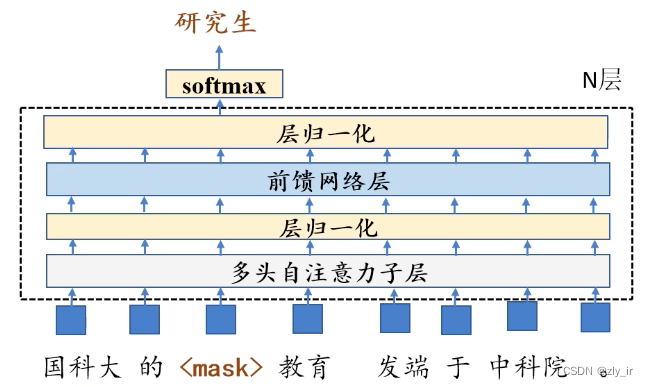
通过上面3步,可以学习到“研究生”这个单词单独的语义,又能学习到它的上下文的语义关系。是不是很像完形填空~。
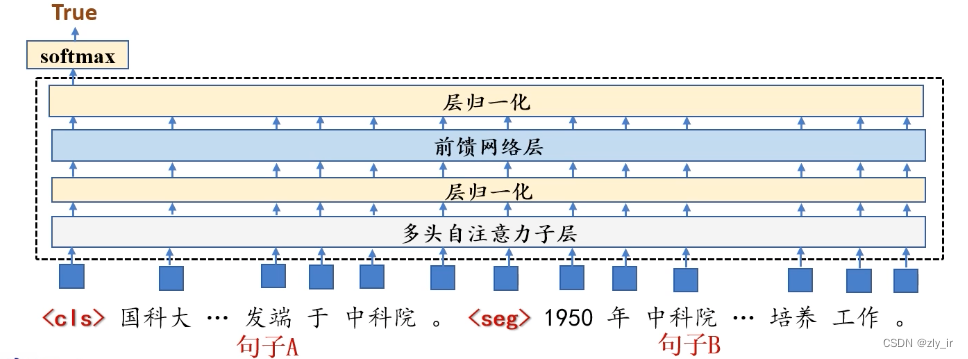
2、下一个句子预测任务
这个任务主要学习句子间的关系,它的训练过程如下:
(1)将数据集中连续两个句子A和B进行拼接(负例的构建就是随机组合句子就行)。
(2)在拼接的句子前端加入<cls>标签,代表句子是否连续,在两个句子间加入<seg>标签,输入到N层的transformer encode里。
(3)将<cls>的隐层状态输入softmax进行预测。
(4)将预测结果和实际结果计算交叉熵,更新参数。
二、BERT应用时的微调方法
BERT微调时,采用少量的标注数据,进行少量轮次的迭代,即可将模型微调为一个特定领域的任务模型,比如句子相似性匹配,句子分类,问答对匹配、序列标注等。