使用logstash把mysql同步到es,Kibana可视化查看
1:首先需要电脑本地有es环境,并且要牢记版本后,后续安装的logstash和Kibana一定要版本对应
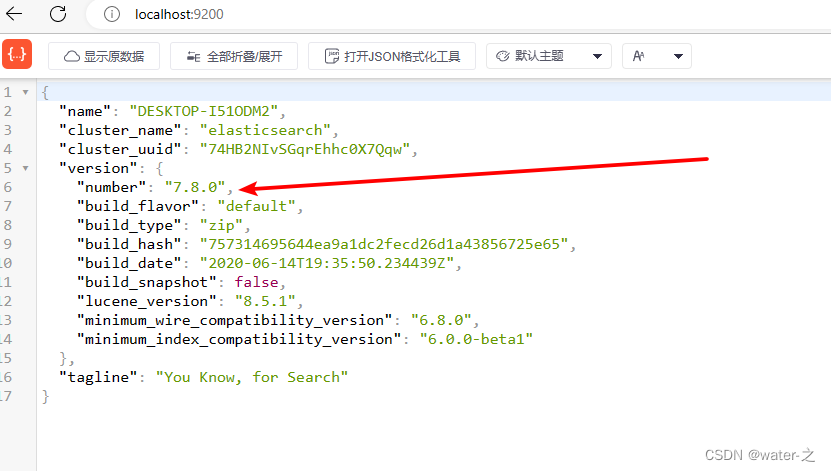
查看es版本:http://localhost:9200/
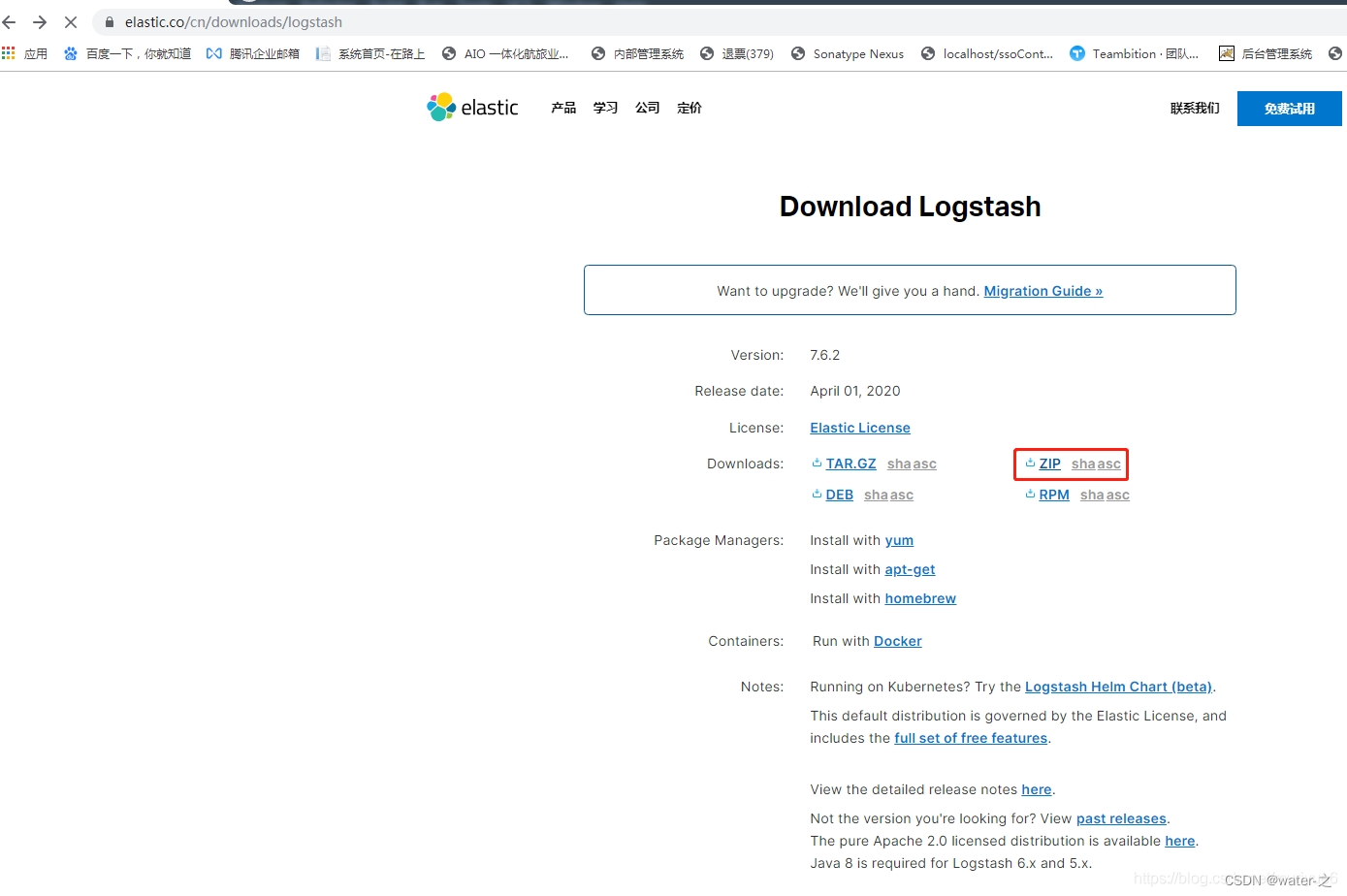
2:安装对应版本的logstash:找到自己对应ES版本,然后解压
Logstash下载地址:https://www.elastic.co/cn/downloads/logstash
3:解压后我这里重命名了一下,进入后是这个样子:
4:进入bin目录,新建配置为文件:my_logstash.conf,里面的jdbc_driver_library需要自己手动添加这个jar包,然后statement 设置为你所需的sql语句,里面注释也写得很清楚, jdbc_connection_string里面数据库的名字改成自己的
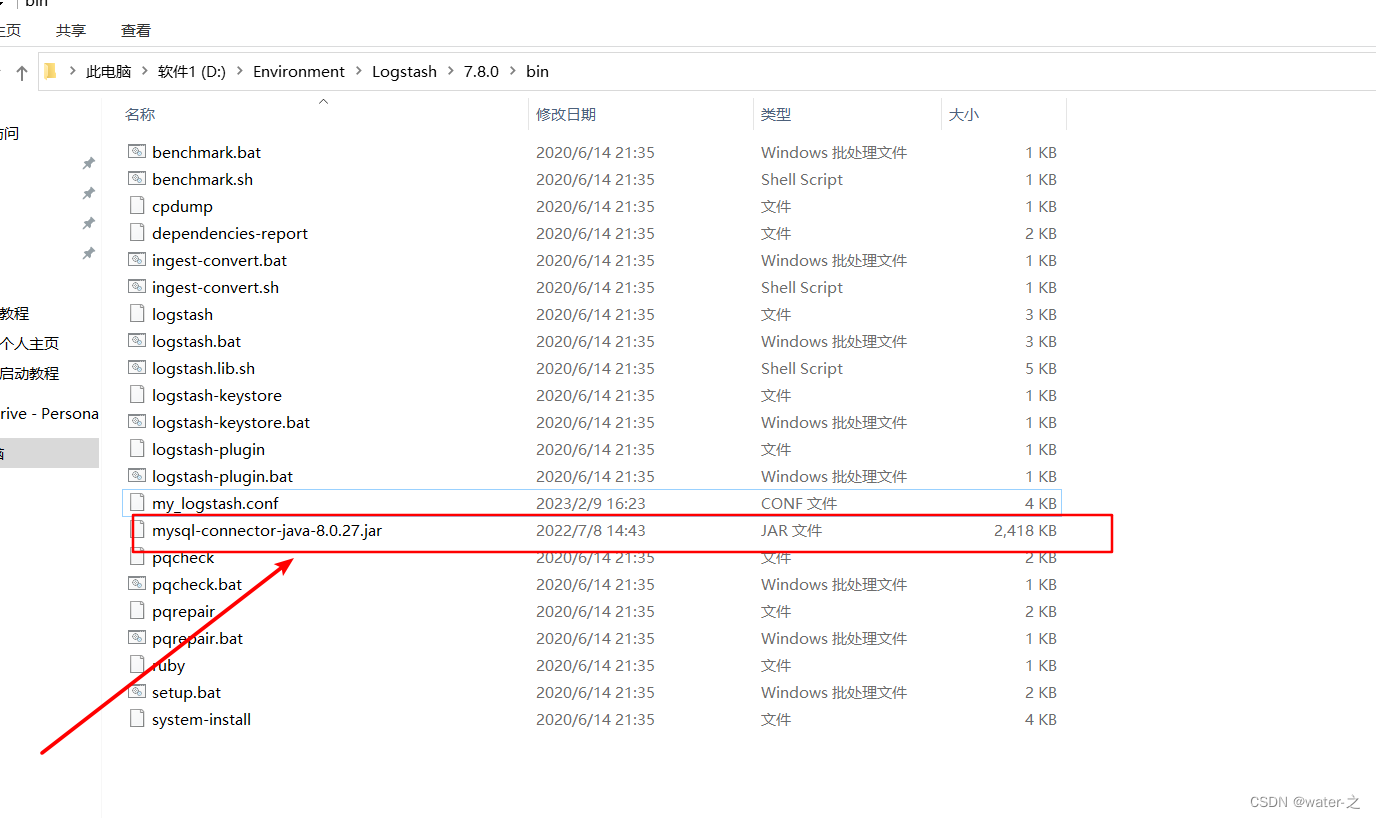
my_logstash.conf:
input {stdin{}jdbc {# 设置 MySql/MariaDB 数据库url以及数据库名称jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/ry-vue-blog?tinyInt1isBit=false&characterEncoding=UTF-8&useSSL=false&autoReconnect=true"# 用户名和密码jdbc_user => "root"jdbc_password => "root"# 数据库驱动mysql-connector-java-8.0.19.jar所在位置,可以是绝对路径或者相对路径,下载地址:https://download.csdn.net/download/qq_30667039/86490851jdbc_driver_library => "D:\Environment\Logstash\7.8.0\bin\mysql-connector-java-8.0.27.jar"# 驱动类名jdbc_driver_class => "com.mysql.cj.jdbc.Driver"# 是否开启分页,ture为开启jdbc_paging_enabled => false# 分页每页数量jdbc_page_size => "50"# 设置时区jdbc_default_timezone =>"Asia/Shanghai"# 执行的sql文件路径# statement_filepath => "E:/logstash-7.8.0/bin/scrm.sql"# 使用这个可以直接写sql语句,但是复杂的语句最好是写在文件内statement =>"SELECT * FROM blog_article"# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务schedule => "*/5 * * * * *"#是否需要记录某个字段值,如果为true,我们可以自定义要记录的数据库某个字段值,例如id或date字段。如果为false,记录的是上次执行的标记,默认是一个timestampuse_column_value => true#记录上次执行字段值路径。我们可以在sql语句中这么写:WHERE ID > :last_sql_value。其中 :sql_last_value 取得就是该文件中的值,这个last_time会以文件形式存在last_run_metadata_path => "E:\logstash-7.8.0\bin\last_time"#如果use_column_value为真,需配置此参数. 指定增量更新的字段名。当然该字段必须是递增的,比如id或date字段。tracking_column => "updateTime"# tracking_column 对应字段的类型,只能选择timestamp或者numeric(数字类型),默认numeric。tracking_column_type => "timestamp"#如果为true,每次会记录所更新的字段的值,并保存到 last_run_metadata_path 指定的文件中record_last_run => true# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录clean_run => false# 是否将字段名称转小写。默认是true。这里注意Elasticsearch是区分大小写的lowercase_column_names => false}
} output {elasticsearch {# es地址 集群数组hosts => ["127.0.0.1:9200"] hosts => ["127.0.0.1:9200"] # 同步的索引名必须要有@timestamp 不然yyyyMM不起效index => "blog_article"# 设置_docID和数据相同document_id => "%{id}"#自定的模板名称#template_name => "ps_seal_log"#自定义的模板配置文件#template => "/usr/local/logstash/logstash-7.12.1/mysqlnote/ps_test_log_template.json"#是否重写模板#template_overwrite => true }stdout{}
}注意上面 index => "blog_article"这里是索引,根据自己的需求设置索引名
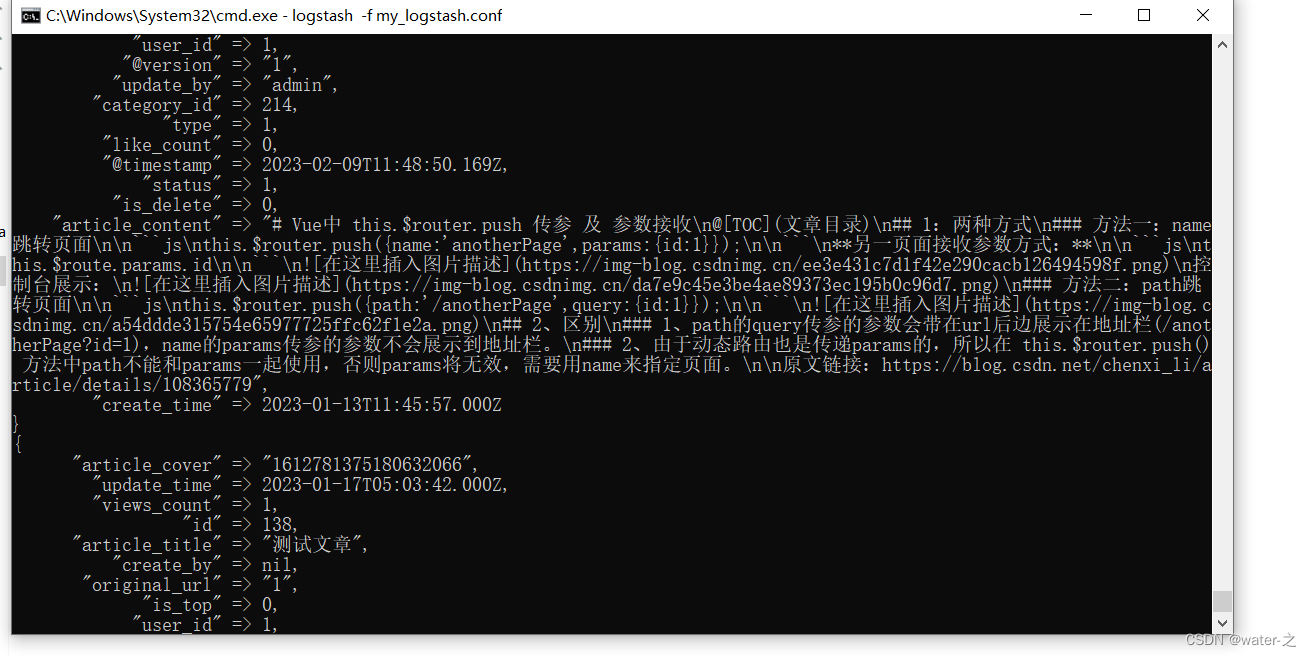
5:然后就可以启动logstash进行数据的同步:在当前bin打开cmd输入命令:logstash -f my_logstash.conf:自动开始同步
6:下载Kibana同样对应es版本:解压后:(记得换成自己的版本,更改后面的-6-6-0为自己的ES版本)
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-6-6-0
7:修改kibana配置文件:改成中文
8:启动kibana:访问: http://localhost:5601/
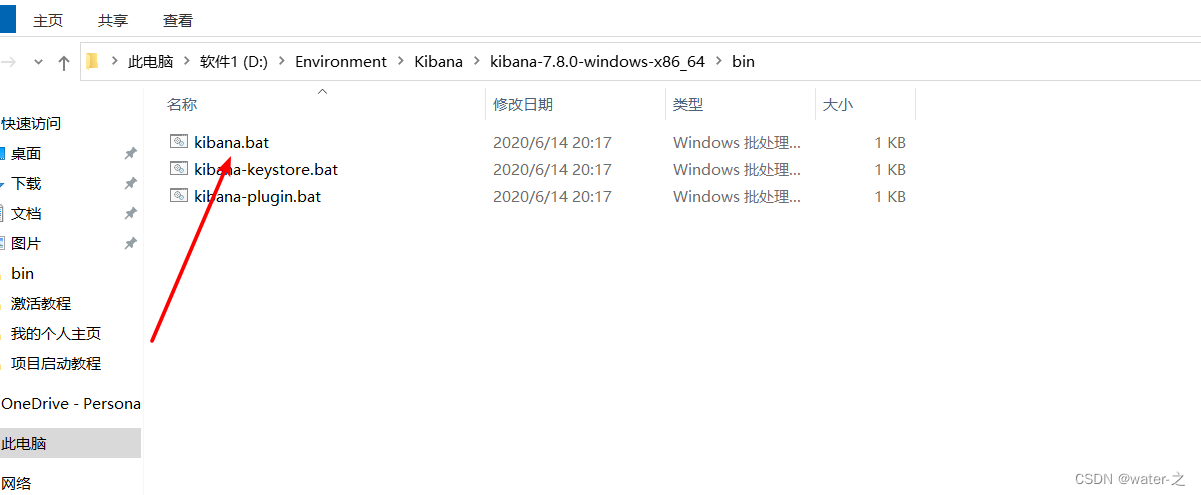
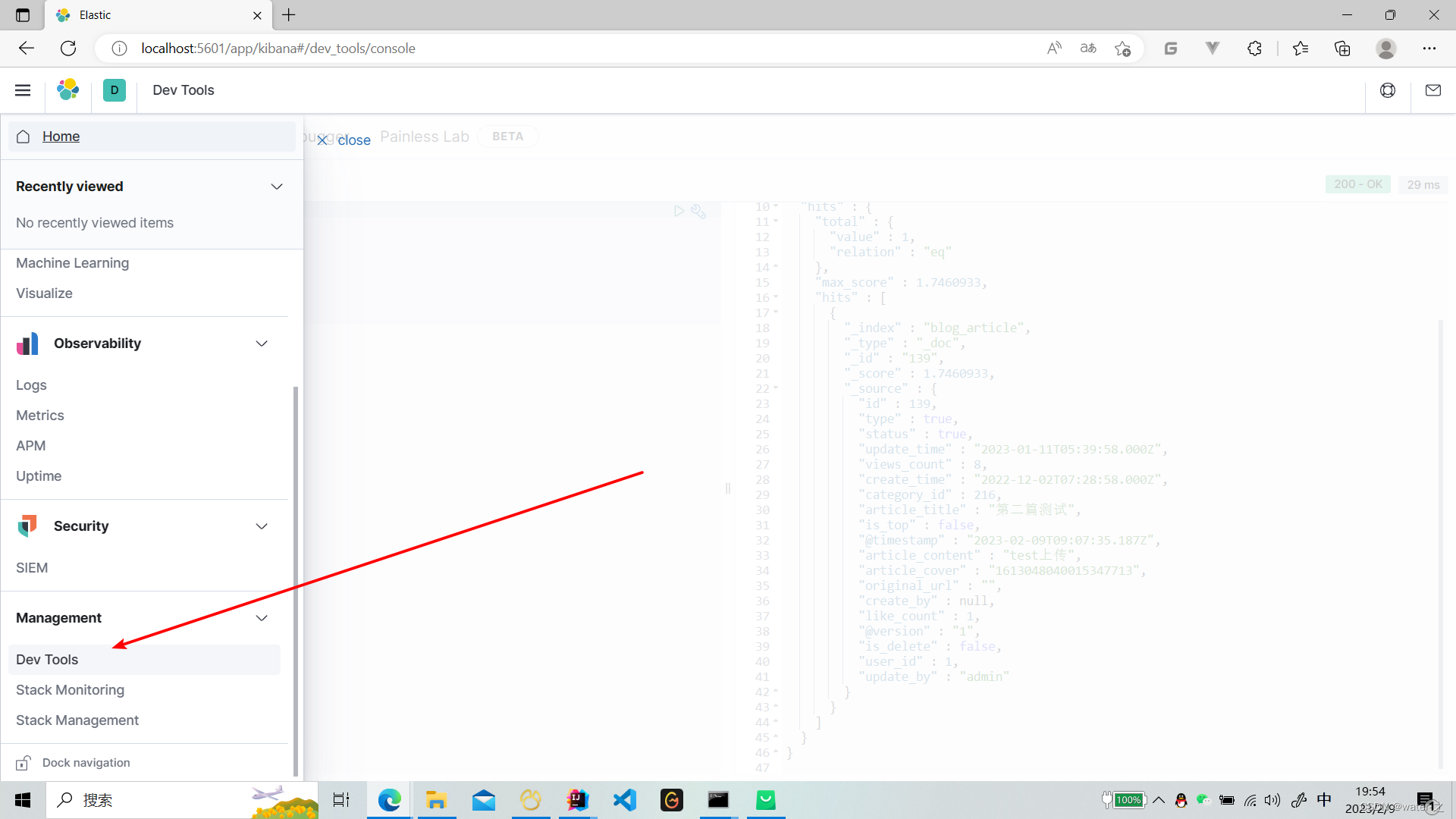
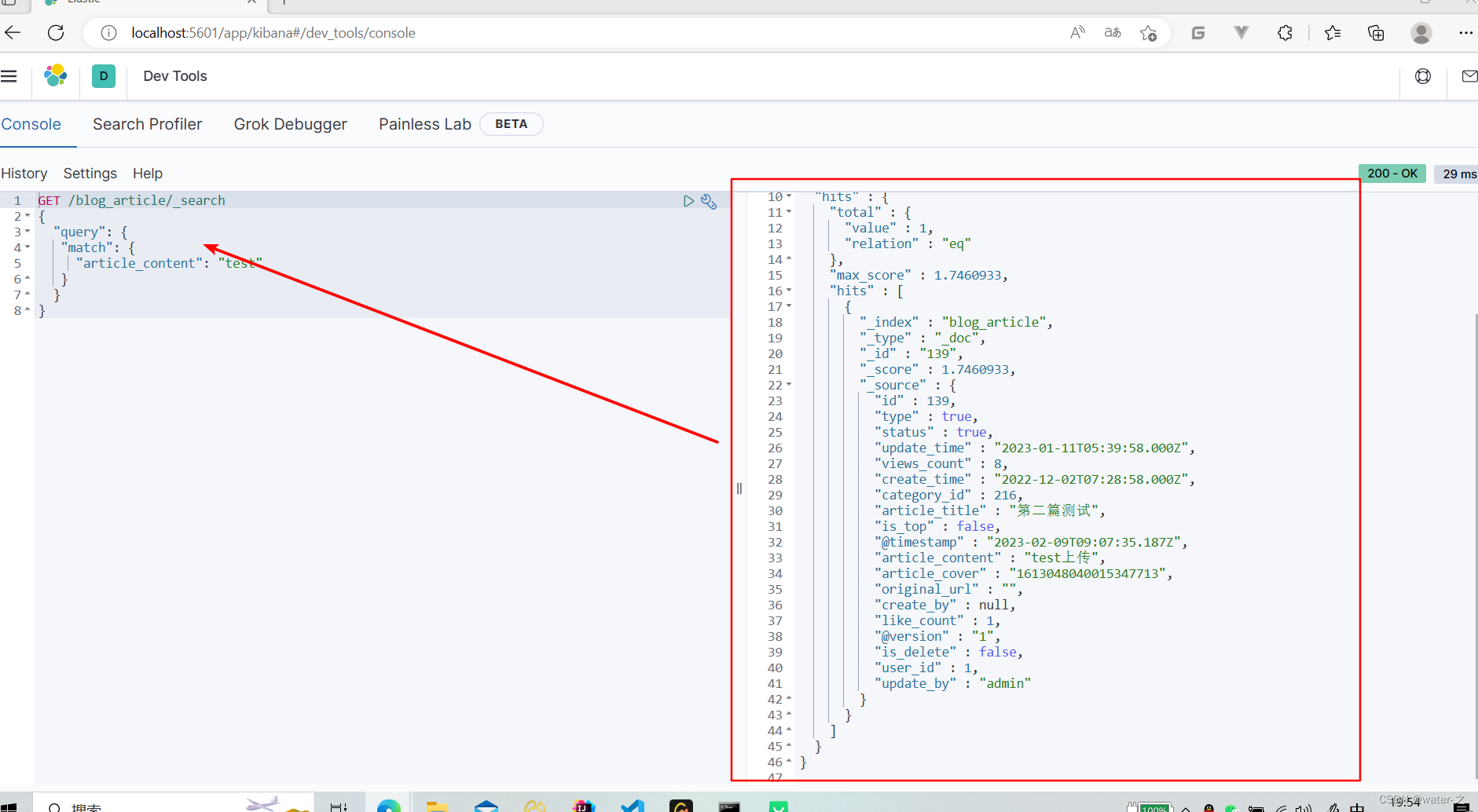
9:查询同步的索引: