Redis:持久化、线程模型、大 key
Redis持久化方式有什么方式?
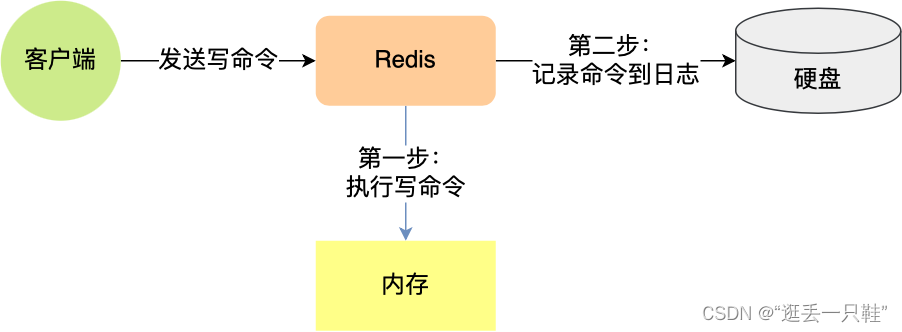
Redis 的读写操作都是在内存中,所以 Redis 性能才会高,但是当 Redis 重启后,内存中的数据就会丢失,那为了保证内存中的数据不会丢失,Redis 实现了数据持久化的机制,这个机制会把数据存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。
Redis 持久化的方式有两种:
- AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
- RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
AOF 日志是如何实现的?
Redis 在执行完一条写操作命令后,就会把该命令以追加的方式写入到一个文件里,然后 Redis 重启时,会读取该文件记录的命令,然后逐一执行命令的方式来进行数据恢复。
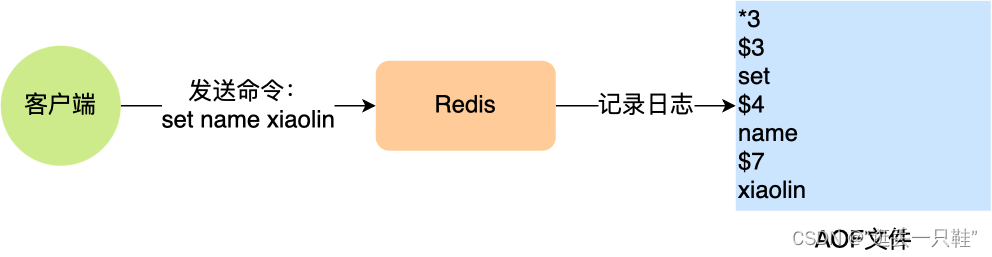
我这里以「set name xiaolin」命令作为例子,Redis 执行了这条命令后,记录在 AOF 日志里的内容如下图:
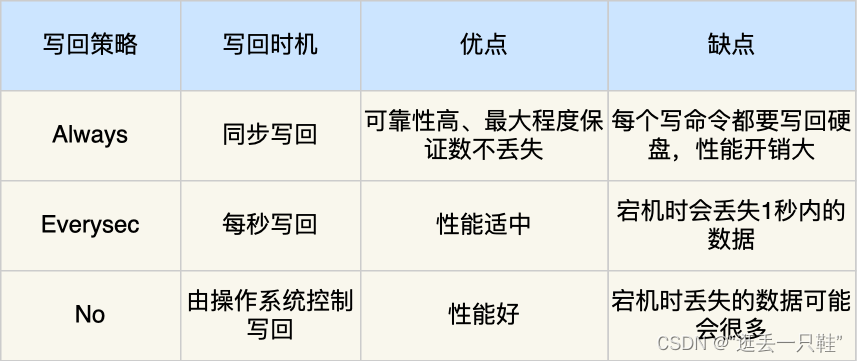
Redis 提供了 3 种写回硬盘的策略,在 Redis.conf 配置文件中的 appendfsync 配置项可以有以下 3 种参数可填:
Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
我也把这 3 个写回策略的优缺点总结成了一张表格:
RDB 快照是如何实现的呢?
因为 AOF 日志记录的是操作命令,不是实际的数据,所以用 AOF 方法做故障恢复时,需要全量把日志都执行一遍,一旦 AOF 日志非常多,势必会造成 Redis 的恢复操作缓慢。
为了解决这个问题,Redis 增加了 RDB 快照。所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片。
所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
Redis 是单线程还是多线程?
Redis 单线程指的是
「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」
这个过程是由一个线程(主线程)来完成的,这也是我们常说 Redis 是单线程的原因。
但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会**启动后台线程(BIO)**的:
Redis 在 2.6 版本,会启动 2 个后台线程,分别处理关闭文件、AOF 刷盘这两个任务;
Redis 在 4.0 版本之后,新增了一个新的后台线程,用来异步释放 Redis 内存,也就是 lazyfree 线程。
例如执行 unlink key / flushdb async / flushall async等命令,会把这些删除操作交给后台线程来执行,好处是不会导致 Redis 主线程卡顿。因此,当我们要删除一个大 key 的时候,不要使用 del 命令删除,因为 del 是在主线程处理的,这样会导致 Redis 主线程卡顿,因此我们应该使用 unlink 命令来异步删除大key。
Redis 在 6.0 版本之后,采用了多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上。但是对于命令的执行,Redis 仍然使用单线程来处理
Redis大key会有什么问题?怎么解决?
大 key 会带来以下四种影响:
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较小。
解决方式:
- 拆分成多个小key。这是最容易想到的办法,降低单key的大小,读取可以用mget批量读取。
- 设置合理的过期时间。为每个key设置过期时间,并设置合理的过期时间,以便在数据失效后自动清理,避免长时间累积的大Key问题。
- 启用内存淘汰策略。启用Redis的内存淘汰策略,例如LRU(Least Recently Used,最近最少使用),以便在内存不足时自动淘汰最近最少使用的数据,防止大Key长时间占用内存。
- 数据分片。例如使用Redis Cluster将数据分散到多个Redis实例,以减轻单个实例的负担,降低大Key问题的风险。
- 删除大key。使用UNLINK命令删除大key,UNLINK命令是DEL命令的异步版本,它可以在后台删除Key,避免阻塞Redis实例。