【机器学习300问】36、什么是集成学习?
一、什么是集成学习?
(1)它的出现是为了解决什么问题?
- 提高准确性:单个模型可能对某些数据敏感或者有概念偏见,而集成多个模型可以提高预测的准确性。
- 让模型变稳定:一些模型,如决策树,对训练数据的微小变化非常敏感。通过集成算法可以平滑这些变化,得到更稳定的预测结果。
- 增强鲁棒性:不同的模型可能对数据中的不同噪声和异常值有不同程度的敏感性,集成学习通过合并这些模型的输出来提高整体系统对噪声和异常值的耐受能力。
- 降低过拟合:通过组合多个模型,特别是在这些模型被训练来关注不同的数据子集时,集成学习能减轻单个模型由于对训练数据过度拟合而在实际使用中表现不佳的风险。
(2)集成学习的定义
集成学习(Ensemble Learning)是一种强大的机器学习范式,它通过构建并组合多个学习器(通常称为基学习器或弱学习器)来解决同一个问题。这类似于寻求多个专家意见而不是仅依靠单个专家的观点。集成学习的核心思想是:多个模型联合起来的整体性能,往往可以超过单个模型的性能。【三个臭皮匠赛过诸葛亮】
弱学习器(Weak Learner):是指那些单独看时预测能力并不特别强的学习模型,其准确率仅略高于随机猜测。在分类任务中,它们的性能仅略优于随机猜测就好,在回归任务中则表现为具有较小但非零预测误差,这些学习器可以是同质的(例如都是决策树)或异质的(来自不同类型的学习算法)
二、集成学习中的三种集成策略
(1)多数表决(Majority Voting)
在分类问题中,每个模型对于每个实例输出一个类别作为预测。多数表决是指统计所有弱学习器的预测结果,选择得票最多的类别作为最终预测结果。如果有多个类别的得票相同,则可能需要引入其他策略(如打破平局规则)。
比如有三个模型,两个模型预测一个实例为类别A,一个模型预测为类别B,那么多数表决的结果就是类别A。
(2)平均法(Averaging)
在回归问题中,或概率预测的分类问题中,最终的预测结果是每个模型输出预测的平均值。
比如一个回归问题中三个模型预测的结果分别是3.5, 4.0, 和4.5,那么平均法的结果就是 (3.5+4.0+4.5)/3 = 4.0。
(3)加权平均(Weighted Averaging)
在回归问题中,或概率预测的分类问题中, 类似于平均法,不过在加权平均中,每个模型的预测结果都会被赋予一个权重,这个权重通常是基于模型的表现的(比如预测的准确度),更好的模型会被赋予更高的权重。然后在计算出预测的加权平均值作为最终的预测结果。
比如模型A的权重是0.6,模型B是0.3,模型C是0.1,那么最终的预测结果是每个模型的预测值乘以其对应权重的和。
这三种集成策略可以看下图直观感受:

三、集成学习的三大分类
(1)并行集成
并行集成方法中的弱学习器通常是并行地或者独立地训练出来的,它们之间的训练过程相互独立,没有强依赖关系。并最终将它们的预测结果结合起来。
如Bagging(Bootstrap Aggregating)和随机森林算法,通过采样数据集生成多个模型,并行训练,最后采用投票、平均或其他统计方法综合结果。

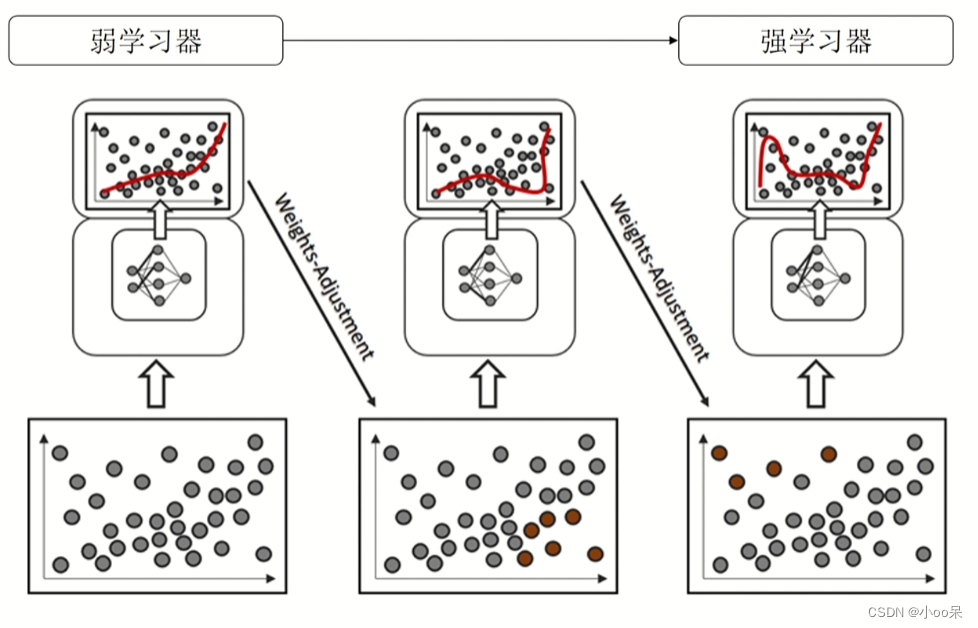
(2)顺序集成
顺序集成方法中的弱学习器是按照一定的顺序依次产生的,后续的学习器会基于之前学习器的表现以及训练过程中调整的数据分布来更新和优化。通过顺序地增加模型的复杂度,从而提高整个模型的性能。
如Boosting算法系列,包括AdaBoost、Gradient Boosting(梯度提升)和XGBoost(极端梯度增强)LightGBM等,其中后续模型是在纠正前序模型错误的基础上进行训练的,逐步迭代形成强大的预测系统。
(3)堆叠模型
① 堆叠模型的概念
堆叠(Stacking)模型可以理解成,混合了并行集成于顺序集成的一种方法。它的核心思想是:使用一个新的模型,称为元学习器(或者叫组合器),去学习如何最有效地合并各个弱学习器(也称为一级学习器)的输出。
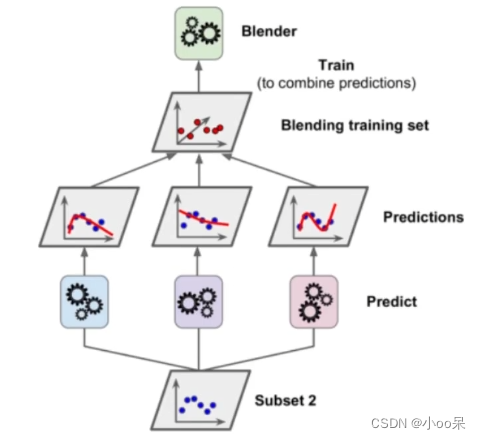
② 它的基本步骤
第一层训练:
- 首先,从原始数据集中选择一组不同的基础模型(可以是同质的,比如都是决策树,也可以是异质的,如包含决策树、神经网络、SVM等不同类型的模型)
- 使用全部或者交叉验证后的训练数据分别训练这些基础模型,并让它们对整个训练集进行预测
- 这些基础模型的预测结果被记录下来,组成“元特征”
第二层训练:
- 将第一层产生的元特征集合(即每个基础模型在所有训练样本上的预测结果)与原来的标签一起构成一个新的训练集
- 在这个新训练集上训练一个新的学习器,通常称之为元学习器或组合器(图中叫二级学习器)。这个元学习器的任务是学习如何最优地结合底层模型的预测结果,以达到最佳的整体预测效果。
预测阶段:
- 当新的数据实例需要被预测时,首先用第一层的所有基础模型进行预测,得到新的元特征向量
- 然后将该向量输入到第二层的元学习器中,得出最终的预测结果
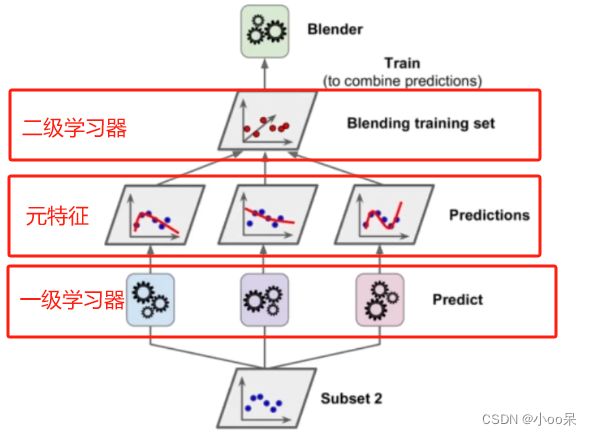
在了解完集成学习中的堆叠模型后,可以发现堆叠模型不光是有并行集成的思想还有顺序集成的部分,在堆叠模型中弱学习器(基础模型)的预测结果不是通过之前讲的三种集成策略(投票、平均、加权平均)来得到最终结果。 而是将预测结果变成输入,再用一个叫元学习器的模型来处理,这才得到最终结果。