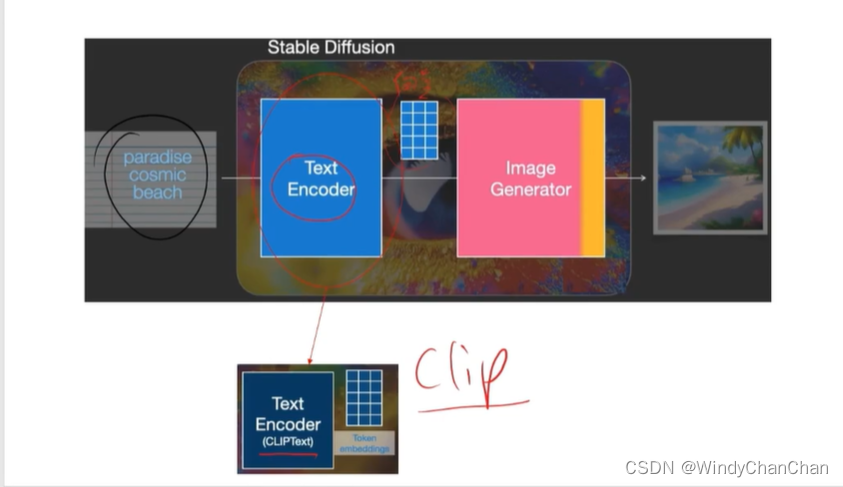
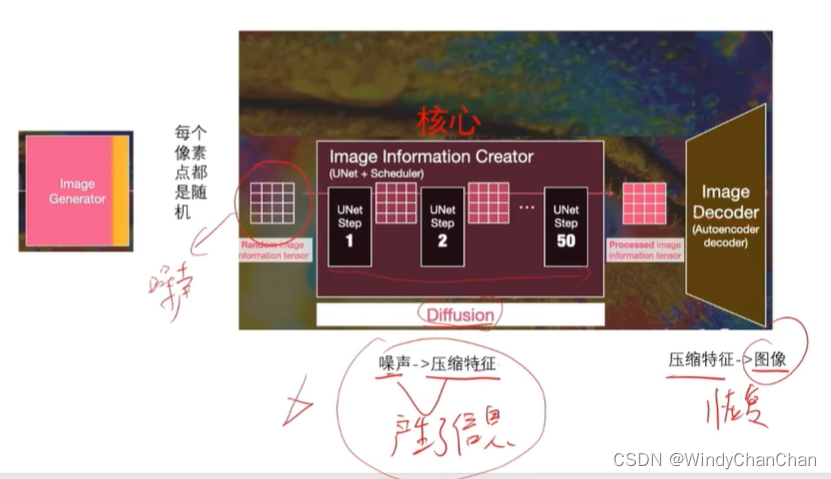
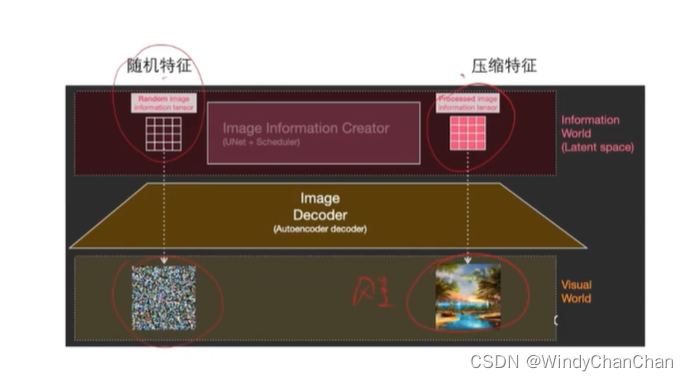
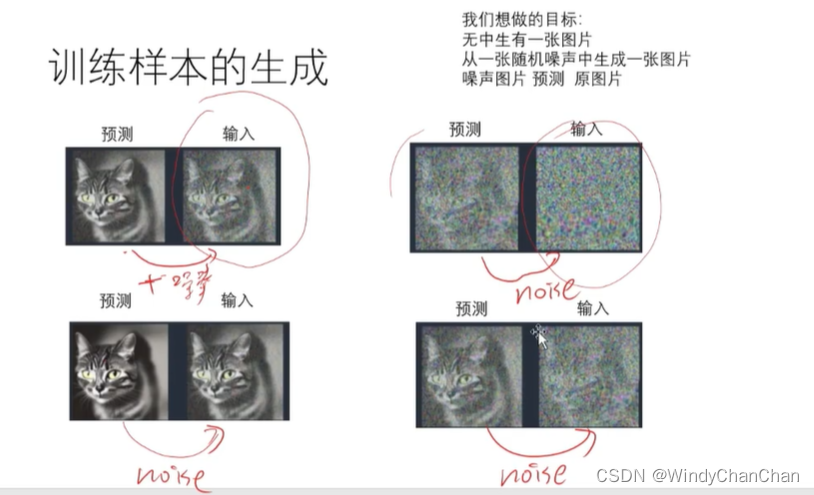
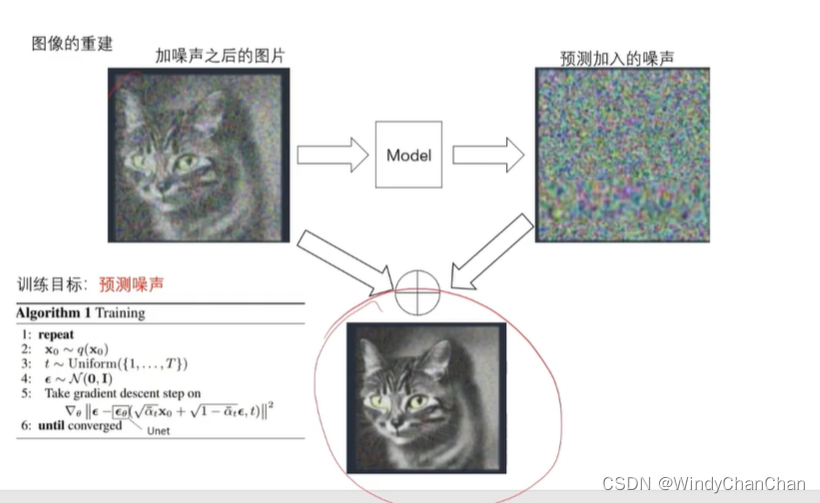
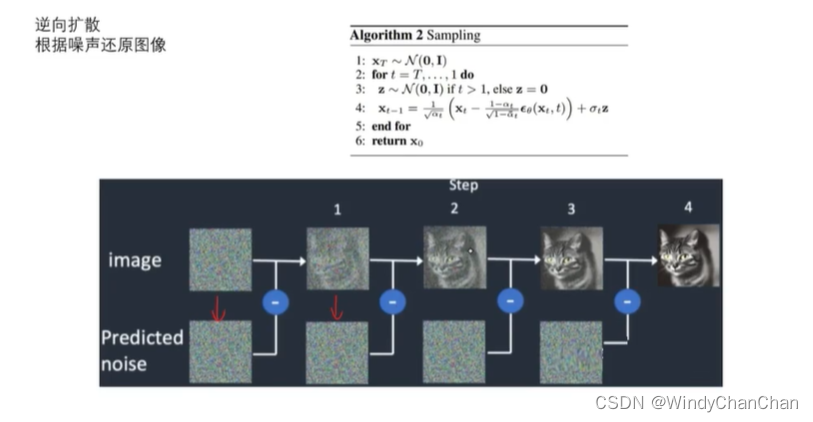
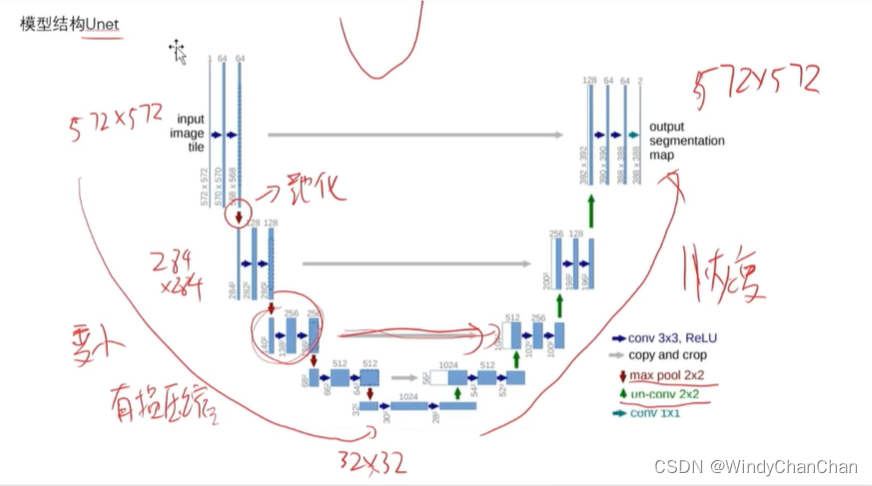
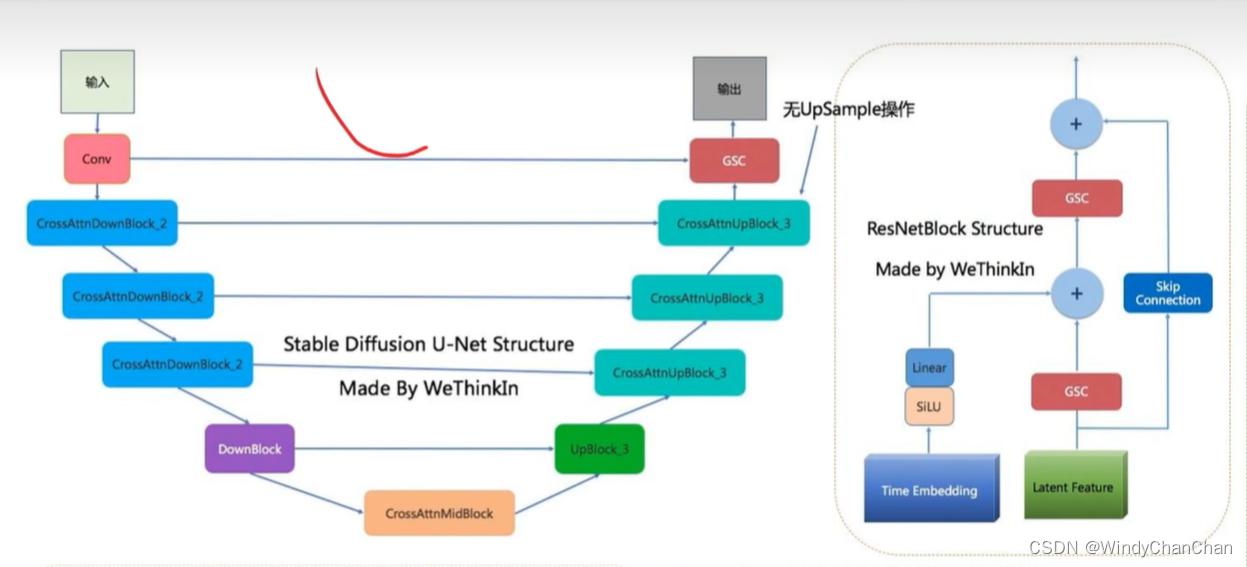
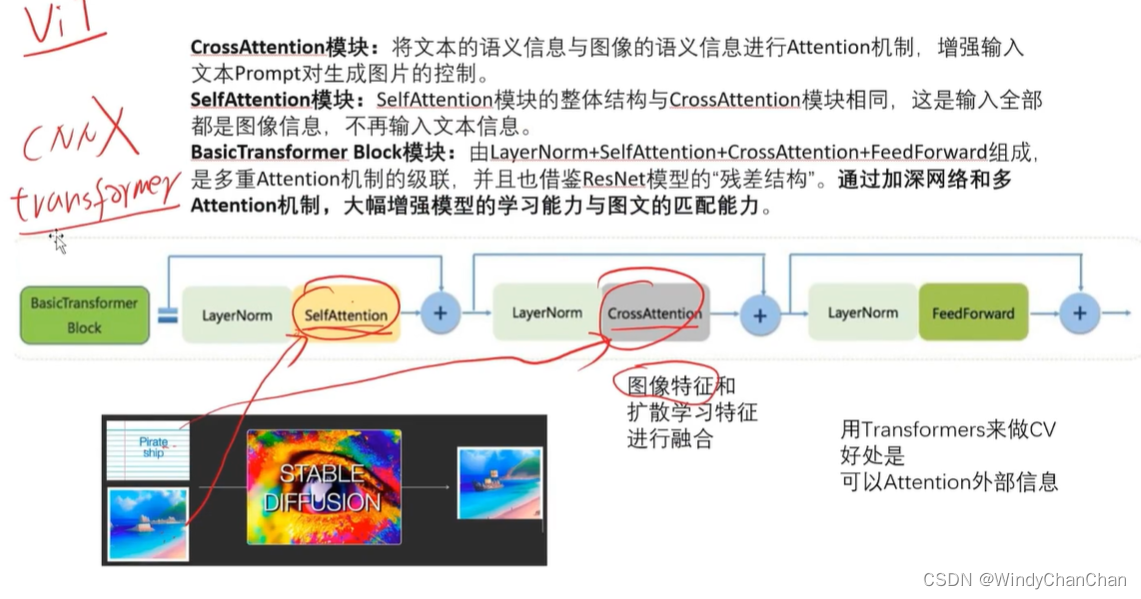
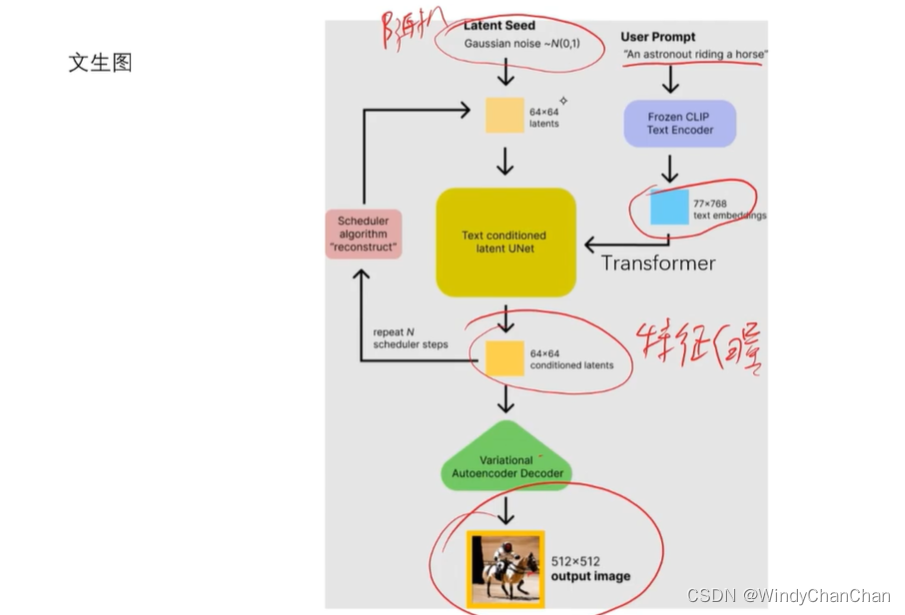
当前位置: 首页 > news >正文 Stable Diffusion 详解 news 2025/9/14 21:28:27 整体目标 文本生成图片;文本+图片生成图片 网络结构 CLIP的文本编码器和图片生成器组成图像生成器,输入是噪声经过UNet得到图像特征,最后解码得到图像 前向扩散 模型直接预测图片难度比较大,所有让模型预测噪音然后输入-噪音可得到原图 逆向扩散 预测模型UNet 改进后的UNet 代码讲解 参考链接 查看全文 http://www.lryc.cn/news/318355.html 相关文章: Go函数全景:从基础到高阶的深度探索 探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(一) MySQL 数据库 下载地址 国内阿里云站点 【25届秋招备战C++】算法篇-贪心算法(Greedy) scrcpy远程投屏控制Android 找机厅 洛谷 BFS 软件无线电系列——模拟无线电、数字无线电、软件无线电 XSS_lab(level11-level18) 【git】常用操作 蓝桥杯第十一届电子类单片机组程序设计 Java中文乱码问题解析与解决方案 AIGC笔记--Maya提取和修改FBX动作文件 【刷题训练】LeetCode125. 验证回文串 optee默认安全配置 Arcgis新建位置分配求解最佳商店位置 【C++初阶】C++入门(上) Vue.js+SpringBoot开发校园疫情防控管理系统 客服销冠偷偷用的提效神器!无广很实用 蓝桥杯刷题|02入门真题 Jenkins cron定时构建触发器 【编程向导】JavaScript-创建对象一期讲解 【MySQL性能优化】- 一文了解MVCC机制 性能测试-Redis 浅析C++的指针与引用 【消息队列开发】 实现消息删除逻辑 【golang】28、用 httptest 做 web server 的 controller 的单测 296.【华为OD机试】污染水域 (图的多源BFS—JavaPythonC++JS实现) C语言——动态内存分配 瑞_23种设计模式_策略模式 使用 OpenAI 的 text-embedding 构建知识向量库并进行相似搜索
整体目标 文本生成图片;文本+图片生成图片 网络结构 CLIP的文本编码器和图片生成器组成图像生成器,输入是噪声经过UNet得到图像特征,最后解码得到图像 前向扩散 模型直接预测图片难度比较大,所有让模型预测噪音然后输入-噪音可得到原图 逆向扩散 预测模型UNet 改进后的UNet 代码讲解 参考链接 查看全文 http://www.lryc.cn/news/318355.html 相关文章: Go函数全景:从基础到高阶的深度探索 探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(一) MySQL 数据库 下载地址 国内阿里云站点 【25届秋招备战C++】算法篇-贪心算法(Greedy) scrcpy远程投屏控制Android 找机厅 洛谷 BFS 软件无线电系列——模拟无线电、数字无线电、软件无线电 XSS_lab(level11-level18) 【git】常用操作 蓝桥杯第十一届电子类单片机组程序设计 Java中文乱码问题解析与解决方案 AIGC笔记--Maya提取和修改FBX动作文件 【刷题训练】LeetCode125. 验证回文串 optee默认安全配置 Arcgis新建位置分配求解最佳商店位置 【C++初阶】C++入门(上) Vue.js+SpringBoot开发校园疫情防控管理系统 客服销冠偷偷用的提效神器!无广很实用 蓝桥杯刷题|02入门真题 Jenkins cron定时构建触发器 【编程向导】JavaScript-创建对象一期讲解 【MySQL性能优化】- 一文了解MVCC机制 性能测试-Redis 浅析C++的指针与引用 【消息队列开发】 实现消息删除逻辑 【golang】28、用 httptest 做 web server 的 controller 的单测 296.【华为OD机试】污染水域 (图的多源BFS—JavaPythonC++JS实现) C语言——动态内存分配 瑞_23种设计模式_策略模式 使用 OpenAI 的 text-embedding 构建知识向量库并进行相似搜索