Coordinate Attention(CVPR 2021)
paper:Coordinate Attention for Efficient Mobile Network Design
official implementation:GitHub - houqb/CoordAttention: Code for our CVPR2021 paper coordinate attention
背景
注意力机制,已经被广泛用于提高深度神经网络的性能,但它们在移动网络中的应用明显落后于大型网络,这主要是因为大多数注意力机制带来的计算开销移动网络负担不起。考虑到移动网络的计算能力有限,到目前为止,移动网络最流行的注意力机制仍然是Squeeze-and-Excitation(SE)attention。但SE只考虑了通道间信息的编码,而忽略了位置信息的重要性,这对在视觉任务中捕获目标结构至关重要。后续的工作如BAM和CBAM试图利用位置信息,通过减少张量的通道维度,然后利用卷积计算空间注意力。但卷积只能捕获局部关系,无法建模对视觉任务至关重要的长距离依赖long-range dependencies。
本文的创新点
本文提出了一种新的有效的注意力机制Coordinate Attention,将位置信息嵌入到通道注意力中,使移动网络能够关注更大的区域范围,同时避免产生显著的计算开销。为了缓解2D全局池化造成的位置信息丢失,我们将通道注意力分解为两个并行的一维特征编码过程,从而有效的将位置坐标信息整合到生成的特征图中。具体来说,我们的方法利用两个一维全局池化操作,分别沿着垂直和水平方向将输入特征聚合到两个独立的方向感知的direction-aware特征图中。这两个嵌入了特定方向信息的特征图随后被分别编码成两个attention map,每个attention map都沿着一个空间方向捕获输入特征图的long-range dependency。因此,位置信息可以保存在生成的attention map中。然后将两个attention map与输入特征图相乘,以强调感兴趣的表示。
本文提出的Coordinate Attention有以下三个优点:
- 它不仅捕获cross-channel信息,还捕获direction-aware和position-aware信息,有助于模型定位和识别感兴趣对象。
- 该方法灵活、轻量,可以很容易到嵌入到经典移动网络的building block中,例如MobileNet v2的inverted residual block和MobileNeXt的sandglass block。
- 作为一个预训练模型,coordinate attention可以为移动网络的下游任务带来显著的性能提升,特别是对于密集预测的任务如语义分割。
方法介绍
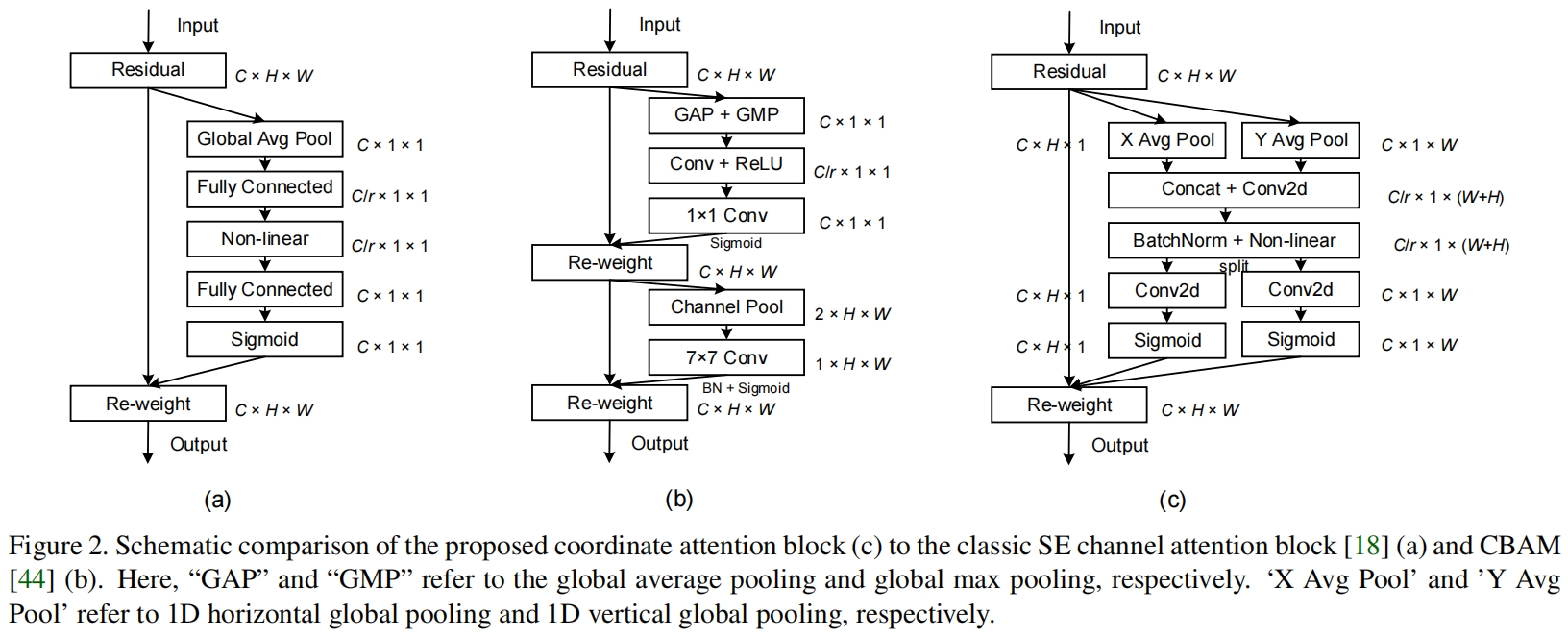
Coordinate Information Embedding
全局池化通常用于通道注意力,对全局信息进行编码。但它将全局信息压缩到一个通道descriptor中,很难保留位置信息,而位置信息对于在视觉任务中捕获空间结构至关重要。为了使注意力模块能够通过精确的位置信息捕获空间上的长距离交互关系,我们将2D的全局池化分解成两个1D的特征编码操作。具体来说,给定输入 \(X\),我们使用两个pooling kernel \((H,1),(1,W)\) 分别沿水平和垂直方向对每个通道进行编码。因此第 \(c\) 个通道高度 \(h\) 处的输出为
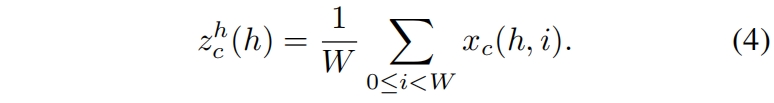
同样,第 \(c\) 个通道宽度 \(w\) 处的输出为
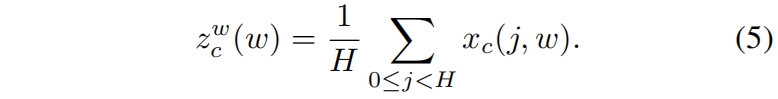
上述两个转换分别沿两个空间方向聚合特征,生成一对direction-aware的特征图。这和SE中生成单个特征向量的squeeze操作不同。这两种转换使得我们的attention block可以沿一个方向捕获long-range dependency,同时沿另一个方向保存精确的位置信息,有助于网络更精确的定位感兴趣对象。
Coordinate Attention Generation
如上所述,式(4)(5)具有全局感受野同时编码了精确的位置信息。为了利用得到的表示,我们提出了第二个转换,coordinate attention generation。对于式(4)(5)的输出特征图,首先将两者拼接,然后经过一个1x1卷积 \(F_{1}\),如下
![]()
其中 \([\cdot,\cdot]\) 表示沿空间维度的concatenation操作,\(\delta \) 是一个非线性激活函数,\(\mathbf{f}\in \mathbb{R}^{C/r\times(H+W)}\) 是沿水平和垂直方向编码了空间信息的中间特征图。\(r\) 是用来控制block size的reduction ratio。然后我们沿空间维度将 \(\mathbf{f}\) split成两个独立的张量 \(\mathbf{f}^{h}\in \mathbb{R}^{C/r\times H}\) 和 \(\mathbf{f}^{w}\in \mathbb{R}^{C/r\times W}\)。另外两个1x1卷积 \(F_h\) 和 \(F_{w}\) 分别用来将 \(\mathbf{f}^{h}\) 和 \(\mathbf{f}^{w}\) 的通道数转换为和输入 \(X\) 一样
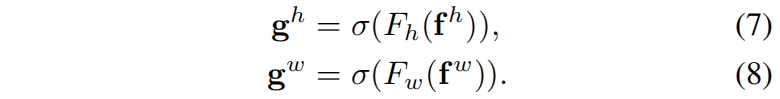
其中 \(\sigma\) 是sigmoid函数。输出 \(\mathbf{g}^h \) 和 \(\mathbf{g}^w\) 扩展后作为注意力的权重。最终,coordinate attention block的输出如下
![]()
实验结果
表6展示了采用SSDLite检测模型,backbone采用轻量模型MobileNet系列,数据集为COCO,不同注意力机制的性能。可以看出,CA取得了最优的结果。
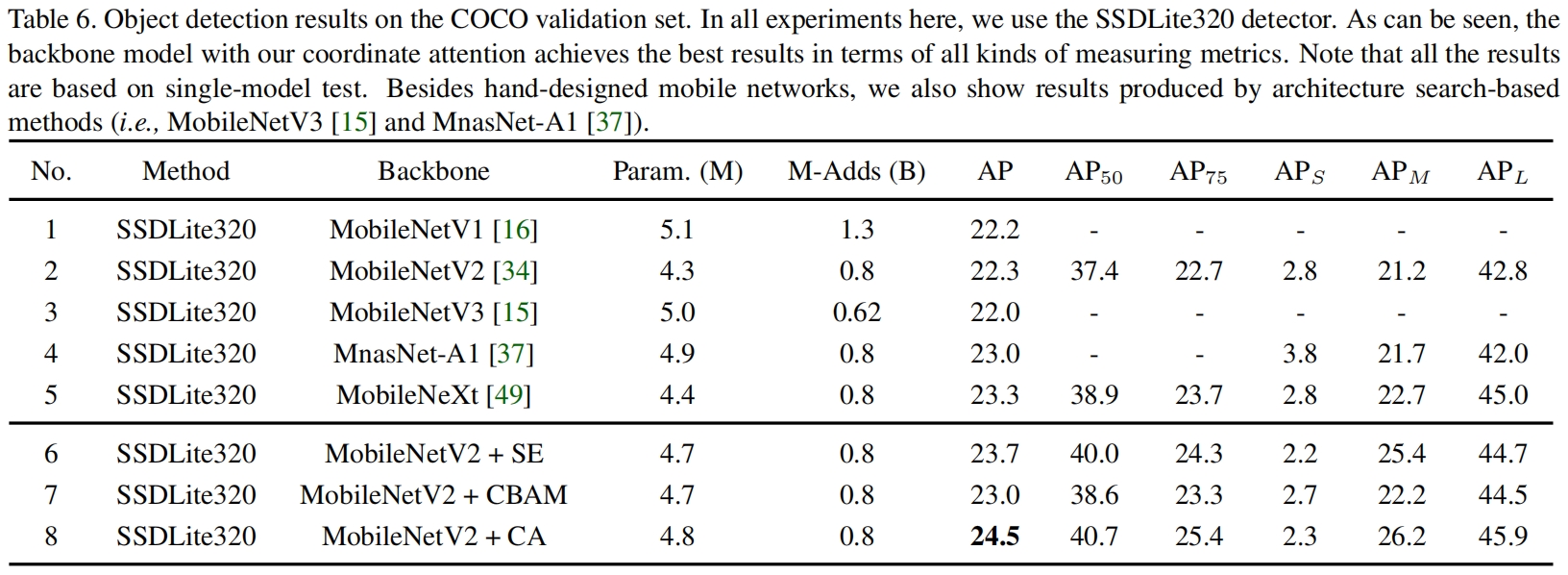
表7是在Pascal VOC数据集上的结果,CA也取得了最优的结果。
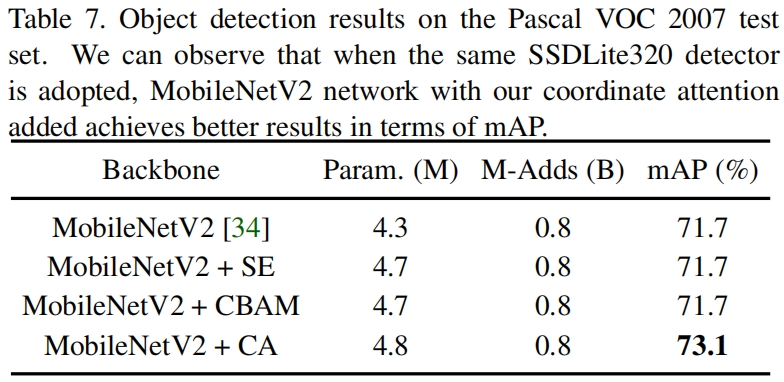
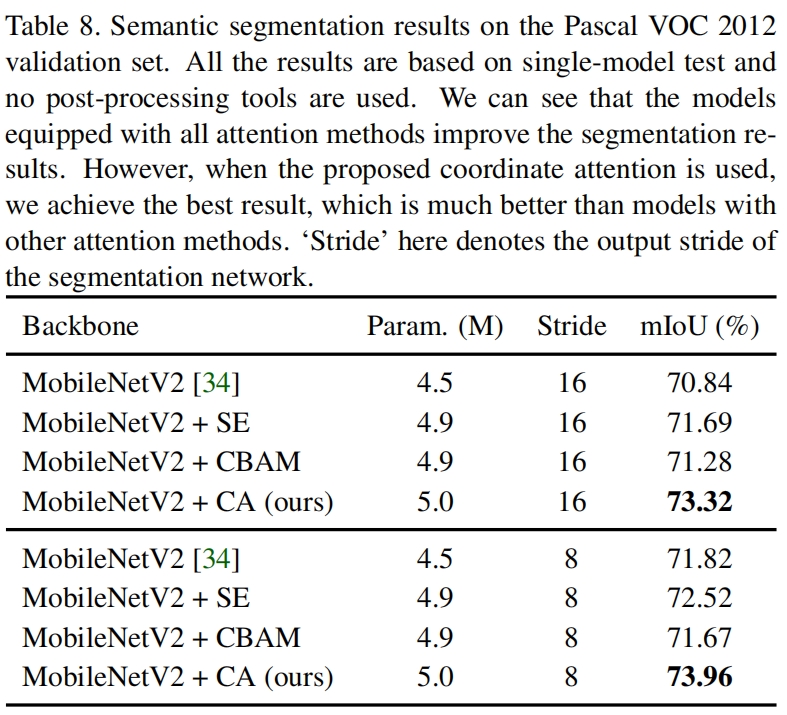
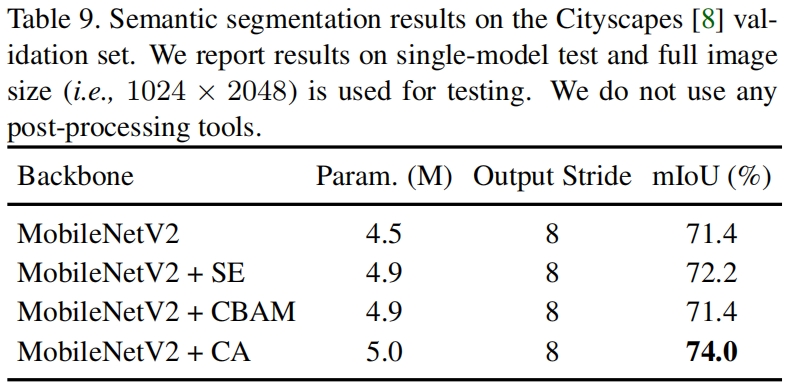
表8、9分别是在Pascal VOC和Cityscapes数据集上语义分割模型的效果,CA同样带来了显著的性能提升。
代码
import torch
import torch.nn as nn
import math
import torch.nn.functional as Fclass h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)class CoordAtt(nn.Module):def __init__(self, inp, oup, reduction=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn,c,h,w = x.size()x_h = self.pool_h(x)x_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)y = self.conv1(y)y = self.bn1(y)y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out