QLC SSD:LDPC纠错算法的优化方案
随着NAND TLC和QLC出现,LDPC也在不断的优化研究,提升纠错能力。小编看到有一篇来自Microchip发布的比较详细的LDPC研究数据,根据自己的理解分析解读给大家,如有错误,请留言指正!
文档中测试LDPC(Low-Density Parity-Check)码是为了评估其在不同配置下对数据错误的有效纠正能力,并优化现代NAND设备所需的错误纠正解决方案。实验针对两种不同的码率(Code Rate, CR)进行了测试:一种为0.919,另一种为0.871,这两种码率下的数据块分别有不同的数据和校验位组合。
-
FEC(Forward Error Correction)块是一种数据结构,其中不仅包含用户实际要存储或传输的数据部分,还包含了用于错误检测和纠正的LDPC(Low-Density Parity-Check)校验位。在NAND闪存等存储技术中,通过添加这些校验信息可以提高数据的可靠性和鲁棒性。
-
码率(Code Rate, CR)是一个关键参数,它定义了有效数据量与整个编码块大小之间的比率。具体而言,CR等于数据大小除以(数据大小加上校验位大小)。例如,如果一个FEC块中有4352字节数据和384字节的LDPC校验位,则其码率为0.919,这意味着该编码方案中大约92%的空间被用来存储有效数据,而剩余8%的空间用于提供错误修正能力。
-
Bit-Error Rate(BER)描述的是在一个数据块内,每一个比特发生错误的概率是相同的。也就是说,在进行错误模拟时,每比特都独立且具有相同概率地发生错误。
-
Error Rate(Err)则是在一组数据块中,确保每个数据块内部含有相同数量的错误比特,这是一种不同的错误插入模型,关注的是整体错误分布的均衡性,而非单个比特的独立性。
-
Frame-Error Rate(FER)则是指经过LDPC译码后,一个FEC块出现错误的概率,即未能正确解码的FEC块所占的比例。它是衡量纠错编码系统性能的一个重要指标,理想情况下,FER应该尽可能低,以确保数据传输或存储过程中的高可靠性。
对于4k字节的数据块,实验采用了以下几种配置:
-
4352字节数据,4736字节数据和校验位,CR为0.919;
-
4352字节数据,4992字节数据和校验位,CR为0.871。
同样,对于16k字节的数据块,其大小恰好是4k字节块的四倍,并且也有相应的测试配置:
-
17408字节数据,18952字节数据和校验位,CR仍为0.919;
-
17408字节数据,19968字节数据和校验位,CR保持在0.871。
实验使用了一种通用的最小和解码算法对这些LDPC码词进行了解码,并对比了不同码率、不同数据块大小下的帧错误率(FER)与比特错误率(BER)的关系。
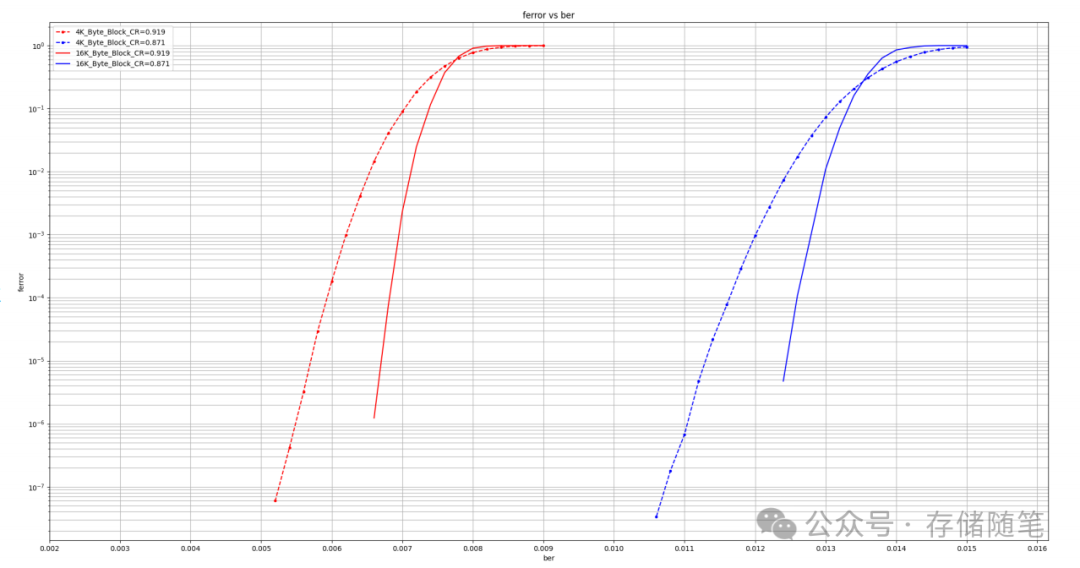
从LDPC FER与BER对比的图表(红色曲线代表CR为0.919,蓝色曲线代表CR为0.871,虚线表示4k字节块,实线表示16k字节块)中可以看出:
-
16k字节块的“瀑布曲线”更为陡峭,表明在同等BER水平下,16k字节块的FER表现更好,即需要更高的BER才会导致解码失败,意味着较大的数据块在采用相同LDPC编码时能更有效地抵抗随机比特错误。

此外,为了公平比较不同大小数据块的FER,将4k字节块的结果转换为等效于16k字节的FER值,通过公式16keq = 1-(1-FER)^4进行调整,结果显示在特定BER下(如BER=1e-4),16k等效FER的表现比原始4k字节块约提升了15%。
BER 4k Byte Error PDF 是关于4k字节数据块在不同比特错误率(Bit Error Rate, BER)下的错误分布概率密度函数(Probability Density Function, PDF)的图表。这个图表详细描述了在给定BER水平下,4k字节数据块中错误比特数目的概率分布状况。
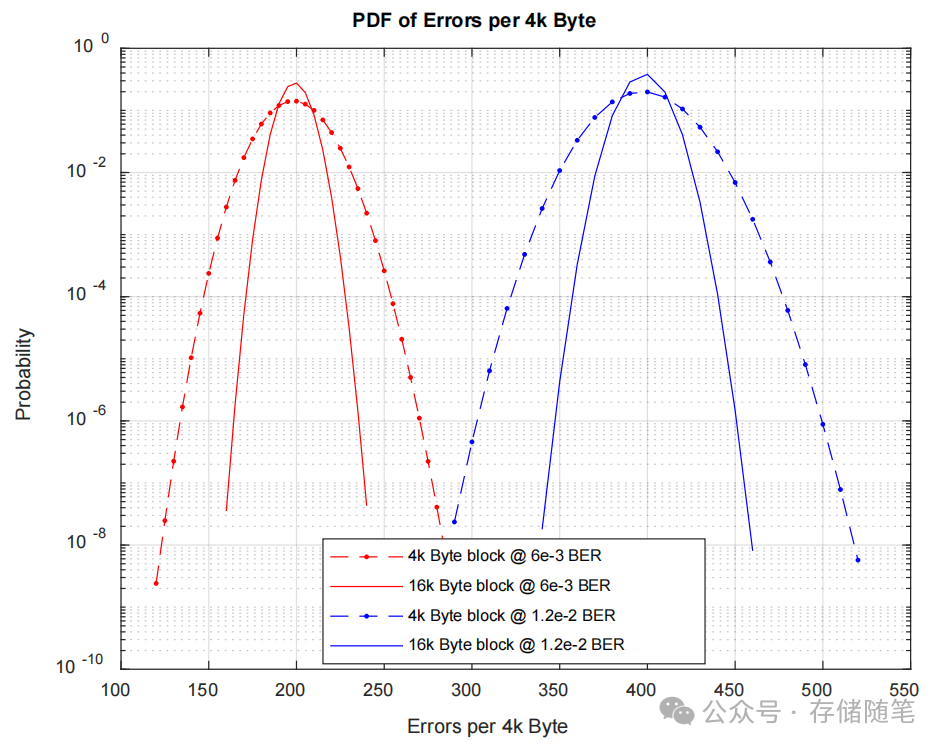
BER模型表明,在分析每块数据时,其内部错误遵循高斯分布(Gaussian distribution),即随着BER的增加,错误数目的分布宽度也随之扩大。这意味着在较高的BER值下,数据块中可能会遇到更多数量的错误比特,分布范围更广。此外,对于16k字节的数据块,即便在相同的BER条件下,它们的错误分布更为紧密,即错误数目落在某特定区间的概率更高,这是因为在较大的数据块中,即使总体错误率不变,单个比特出错的概率会因为数据块内比特总数的增加而变得更加均匀分布。
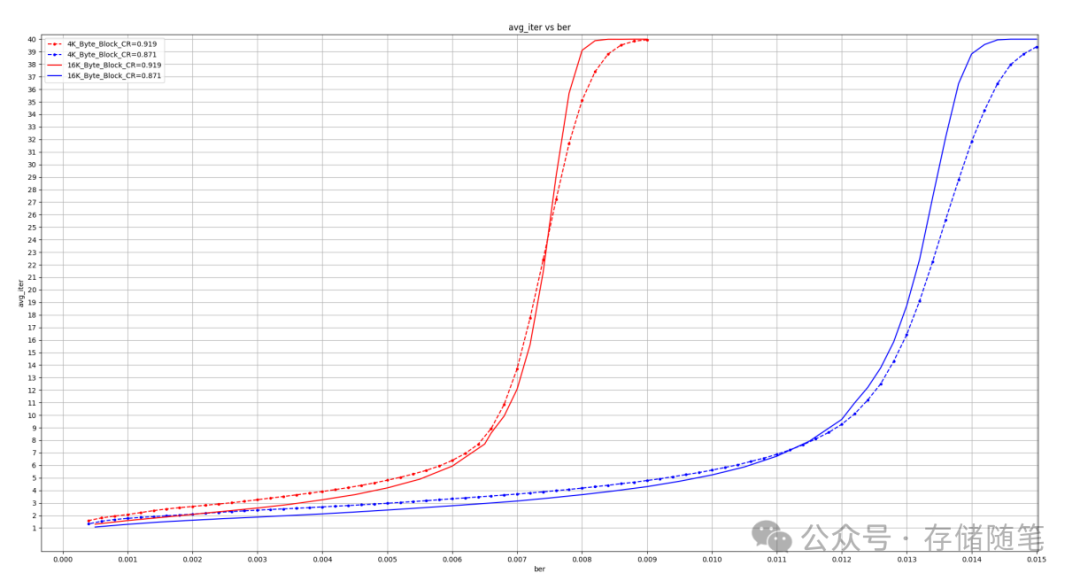
下图不同码率对应的不同数据块大小的平均迭代次数随BER变化的曲线,可以帮助我们观察并量化不同条件下的纠错效率。在选择最优LDPC编码方案时,除了考虑平均迭代次数外,还需要满足其他性能要求,比如软触发率阈值,通常设定在FER(Frame Error Rate)为1e-2到1e-6之间。最优解决方案应当是在满足FER要求的同时,具有最低的平均迭代次数,从而实现最大的数据传输或存储吞吐量。
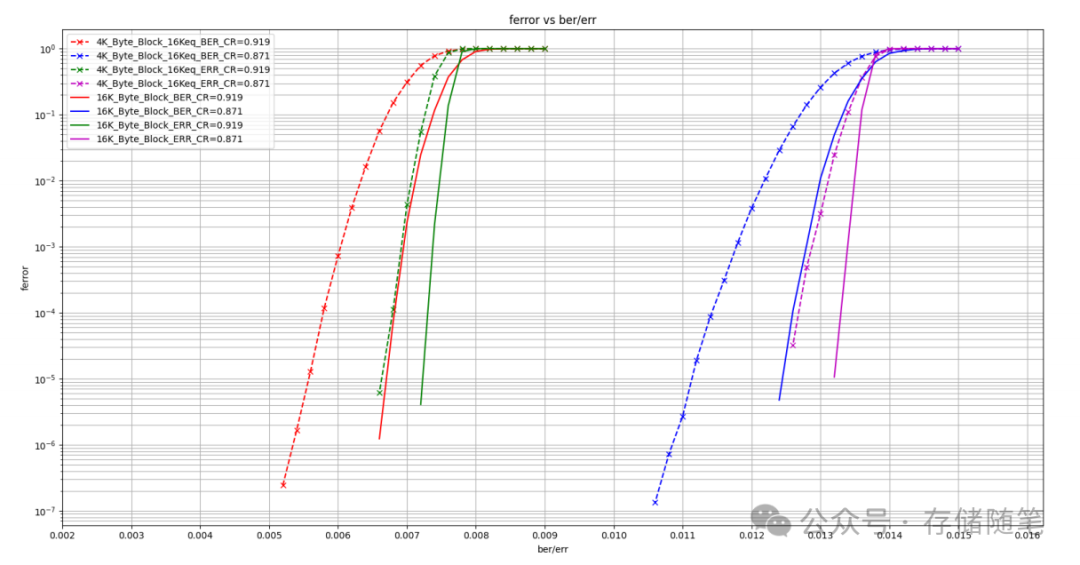
“LDPC FER vs. Err (Scaled)”图表显示:
-
在BER指标下,尤其是在BER较高区域,16k字节和4k字节数据块的性能差异较大。
-
但在统一错误率模型下,相较于按照BER标准评价时的情况,4k字节和16k字节数据块在处理相同数量错误比特时的性能差距有所缩小,这表明在某些应用场景下,特别是在存在均匀分布错误的情况下,16k字节数据块可能并不会因为其尺寸增大而带来明显的纠错劣势。同时这也体现出LDPC编码在处理不同类型的错误模式时具有较强的适应性和灵活性。
根据提供的样本NAND闪存错误分布的分析,揭示了实际NAND闪存设备中错误出现的统计特性。Y轴表示错误发生的概率,X轴表示错误率。每个数据块中的错误数量等于错误率乘以数据块大小。典型特征是大多数数据块的错误率都很低,但有一小部分数据块存在较高的错误率ÿ