1.2 数据模型 数据库系统概论
目录
1.2.1 两类数据模型
1.2.2 概念模型
1.信息世界中的基本概念
(1)实体
(2)属性
(3)码
(4)实体型
(5)实体集
(6)联系
2.两个实体型之间的联系
1.一对一联系(1:1)
2.一对多联系(1:n)
3.多对多联系(m:n)
1.2.3 数据模型的组成要素
1.数据结构
2.数据操作
3. 数据的完整性约束条件
1.2.4 常用的数据模型
1.2.5 层次模型
1.2.6 网状模型
1.2.7 关系模型
术语
数据模型是对现实世界数据特征的抽象。数据模型就是现实世界的模拟。一个数据模型应满足三方面的要求:1.能比较真实地模拟现实世界。2.容易为人理解。3.便于在计算机上实现。数据模型是数据库系统的核心和基础。
1.2.1 两类数据模型
数据模型分为两类(两个不同的层次):1.概念模型(信息模型) 按用户的观点来对数据和信息建模,用于数据库设计。2.逻辑模型和物理模型 逻辑模型主要包括网状模型、层次模型、关系模型、面向对象数据模型、对象关系数据模型、半结构化数据模型等。是按计算机系统的观点对数据建模,用于DBMS的实现。物理模型是对数据最底层的抽象,用于描述数据在系统内部的表示方法和存取方法。
客观对象的抽象过程--两步抽象:1.现实世界中的客观对象抽象为概念模型 2.把概念模型转换为某一数据库管理系统支持的数据模型。
1.2.2 概念模型
概念模型实际上是现实世界到机器世界的一个中间层次。概念模型用于信息世界的建模,是现实世界到信息世界的第一层抽象,是数据库实际人员进行数据库设计的有力工具,也是数据库设计人员和用户之间进行交流的语言。
概念模型一方面应该具有较强的语义表达能力,能够方便、直接地表达应用中的各种语义知识,另一方面它还应该简单、清晰、易于用户理解。
1.信息世界中的基本概念
(1)实体
客观存在并可相互区别的事物称为实体。可以是具体的人、事、物或抽象的概念或联系。
(2)属性
实体所具有的某一特性称为属性。一个实体可以由若干属性来刻画。
(3)码
唯一标识实体的属性集称为码。
(4)实体型
具有相同属性的实体必然具有共同的特征和性质。用实体名及其属性名集合来抽象和刻画同类实体称为实体型。
(5)实体集
同一类型实体的集合称为实体集。
(6)联系
现实世界中,事物内部以及事物之间的联系在信息世界中反映为实体内部的联系和实体之间的联系。(ps:实体内部之间的联系:指组成实体的各属性之间的联系,实体之间的联系:指不同实体集之间的联系)
2.两个实体型之间的联系
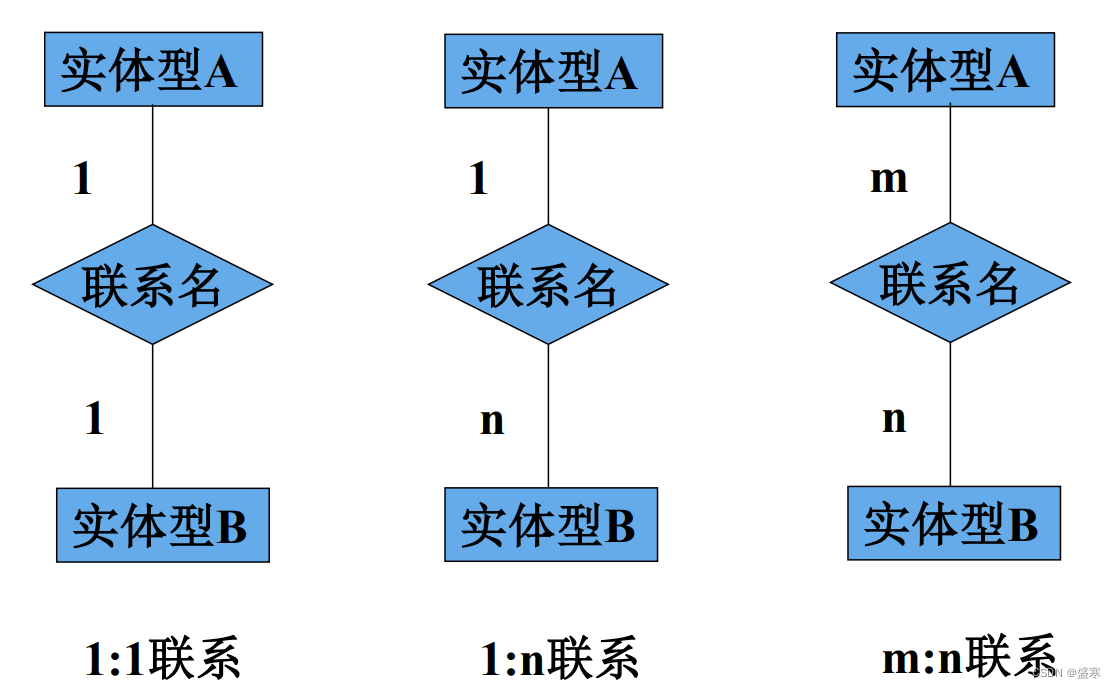
实体之间有一对一,一对多和多对多等多种类型。如下图:
1.一对一联系(1:1)
定义:如果对于实体集A中的每一个实体,实体集 B中至多有一个(也可以没有)实体与之联系, 反之亦然,则称实体集A与实体集B具有一对一联系,记为1:1。
2.一对多联系(1:n)
定义:如果对于实体集A中的每一个实体,实 体集B中有n个实体(n≥0)与之联系,反之, 对于实体集B中的每一个实体,实体集A中 至多只有一个实体与之联系,则称实体集A 与实体集B有一对多联系,记为1:n。
3.多对多联系(m:n)
定义:如果对于实体集A中的每一个实体,实体 集B中有n个实体(n≥0)与之联系,反之, 对于实体集B中的每一个实体,实体集A中 也有m个实体(m≥0)与之联系,则称实体 集A与实体B具有多对多联系,记为m:n。
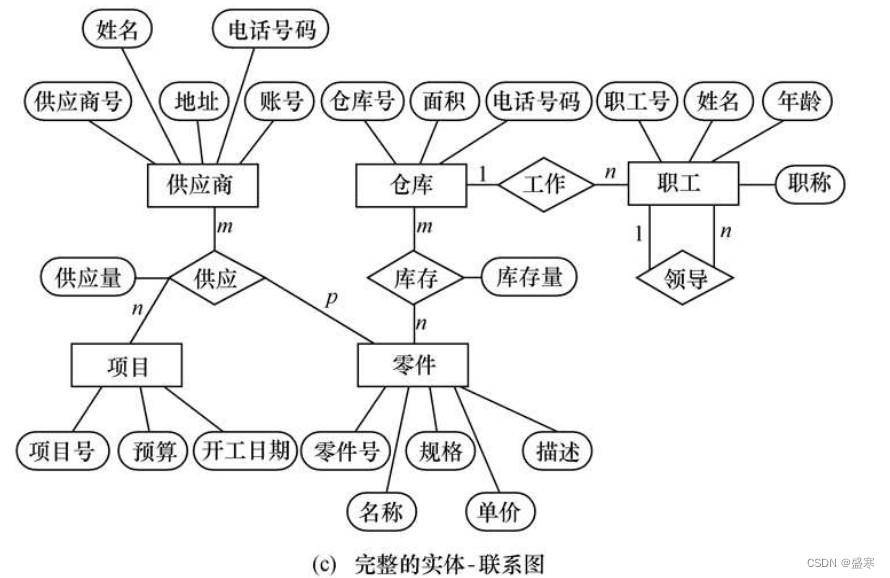
实体-联系方法,是概念模型的一种表示方法。例如:
1.2.3 数据模型的组成要素
数据模型: 严格定义的一组概念的集合。能精确地描述系统的静态特性、动态特性和完整性约束条件。
组成三要素:1.数据结构(描述系统的静态特性)2.数据操作(描述系统的动态特性)3.数据的完整性约束条件。
1.数据结构
数据结构:描述数据库的组成对象,以及对象之间的联系。
描述内容:1. 与对象的类型、内容、性质有关。2. 与数据之间联系有关的对象。
按照数据结构的类型命名数据模型:层次结构—层次模型、网状结构-网状模型、关系结构—关系模型。
数据结构是对系统静态特性的描述。
2.数据操作
数据操作:对数据库中各种对象(型)的实例(值)允许执行的操作的集合, 包括操作及有关的操作规则。
数据操作的类型:查询,更新。
数据模型对操作的定义:操作的确切含义、操作符号、操作规则;实现操作的语言。
数据操作是对系统动态特性的描述。
3. 数据的完整性约束条件
数据的完整性约束条件是一组完整性规则的集合。
完整性规则:给定的数据模型中数据及其联系所具有的制约和依存规则。用以限定符合数据模型的数据库状态以及状态的变化,以保证数据的正确、有效和相容。
数据模型应反映和规定必须遵守的基本的、通用的完整性约束条件。提供定义完整性约束条件的机制,以反映具体应用所涉及的数据必须遵守的特定的语义约束条件。
1.2.4 常用的数据模型
格式化模型(层次模型(Hierarchical Model);网状模型(Network Model))关系模型(Relational Model);面向对象数据模型(Object Oriented Data Model); 对象关系数据模型(Object Relational Data Model); 半结构化数据模型(Semistruture Data Model)……
基本层次联系
在格式化模型中实体用记录表示,实体的属性对应记录的数据项 (或字段)。实体之间的联系在格式化模型中转换成记录之间的两两联系,是格式化模型中数据结构的单位。
定义:是指两个记录以及它们之间的一对多(包括一对一)的联系。
1.2.5 层次模型
层次模型是数据库系统中最早出现的数据模型。典型代表是IBM公司的IMS(Information Management System)数据库管理系统。用树形结构来表示各类实体以及实体间的联系。
表示方法:实体型:用记录类型描述,每个结点表示一个记录类型(实体)。属性:用字段描述,每个记录类型包含若干个字段。联系:用结点之间的连线表示记录类型(实体)之间的一对多的父 子联系。
满足下面两个条件的基本层次联系的集合为层次模型: 1. 有且只有一个结点没有双亲结点,这个结点称为根结点 2. 根以外的其它结点有且只有一个双亲结点。
层次模型的特点:1.结点的双亲是唯一的 2.只能直接处理一对多的实体联系 3.每个记录类型可以定义一个 排序字段,也称为码字段 4.任何记录值只有按其路径查看时,才能显出它的全部意义。5.没有一个子女记录值能够脱离双亲记录值而独立存在。
层次模型的数据操纵:查询,插入,删除,更新。
层次模型的完整性约束条件:1.无相应的双亲结点值就不能插入子女结点值 2.如果删除双亲结点值,则相应的子女结点值也被同时删除 3.更新操作时,应更新所有相应记录,以保证数据的一致。
层次模型的优点:1.层次模型的数据结构比较简单清晰 2. 查询效率高,性能优于关系模型,不低于网状模型 3. 层次数据模型提供了良好的完整性支持。
层次模型的缺点:1.结点之间的多对多联系表示不自然 2.对插入和删除操作的限制多,应用程序的编写比较复杂 3. 查询子女结点必须通过双亲结点 4.层次命令趋于程序化。
1.2.6 网状模型
网状数据库系统采用网状结构来表示各类实体以及实体间的联系。
定义:满足下面两个条件的基本层次联系的集合: 1. 允许一个以上的结点无双亲; 2. 一个结点可以有多于一个的双亲。
特点:1.允许多个结点没有双亲结点 2.允许结点有多个双亲结点 3.允许两个结点之间有多种联系(复合联系) 4.可以更直接地描述现实世界。
网状模型中子女结点与双亲结点的联系可以不唯一。要为每个联系命名,并指出与该联系有关的双亲记录和子女记录。
网状模型没有如层次模型那样严格的完整性约束条件,实际的网状数据库系统(如DBTG)对数据操纵加了一些限制,提供了一定的完整性约束:1.支持码的概念:唯一标识记录的数据项的集合 ,取唯一的值; 2.保证一个联系中双亲记录与子女记录之间是一对多联系 3.可以支持双亲记录和子女记录之间某些约束条件。
优点:能够更为直接地描述现实世界,如一个结点可以有多个双亲 ;具有良好的性能,存取效率较高。
缺点:结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于最终用户掌握 ;DDL、DML语言复杂,用户不容易使用 ;记录之间联系是通过存取路径实现的,用户必须了解系统结构的细节(加重了程序员的负担)。
1.2.7 关系模型
关系数据库系统采用关系模型作为数据的组织方式。计算机厂商新推出的数据库管理系统几乎都支持关系模型。
在用户观点下,关系模型中数据的逻辑结构是一张二维表, 它由行和列组成。
术语
关系 一个关系对应通常说的一张表
元组 表中的一行即为一个元组
属性 表中的一列即为一个属性,给每一个属性起一个名称即属性名
主码 也称码键。表中的某个属性组,它可以唯一确定一个元组。
域 是一组具有相同数据类型的值的集合。属性的取值范围 来自某个域。
分量 元组中的一个属性值。
关系模式 对关系的描述:关系名(属性1,属性2,…,属性n)
关系必须是规范化的,满足一定的规范条件,最基本的规范条件:关系的每一个分量必须是一个不可分的数据项, 不允许表中还有表.
关系模型的操纵:查询,插入,删除,更新。
存取路径对用户隐蔽,用户只要指出“干什么” ,不必详细说明“怎么干”(提高数据的独立性,提高用户的生产率)
关系的完整性约束条件:1.实体完整性 2.参照完整性 3.用户定义的完整性
优点:建立在严格的数学概念(关系)的基础上;概念单一 ,实体和各类联系都用关系来表示 ,对数据的检索结果也是关系 ;关系模型的存取路径对用户透明 ,具有更高的数据独立性,更好的安全保密性 ,简化了程序员的工作和数据库开发建立的工作。
缺点:存取路径对用户透明,查询效率往往不如格式化数据模型 ;为提高性能,必须对用户的查询请求进行优化,增加了开发数据库管理系统的难度。