matlab实现层次聚类与k-均值聚类算法
1. 原理
1.层次聚类:通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程并生成聚类树
2.k-means聚类:在数据集中根据一定策略选择K个点作为每个簇的初始中心,然后将数据划分到距离这K个点最近的簇中,重新计算每个簇的中心点,然后在重新进行划分,直到每次划分的结果保持不变。
2. 过程
1.层次聚类:
样本点:x1= [0,0]T, x2=[0,1]T, x3=[2,0]T , x4= [3,3]T , x5= [4,4]T
将样本点存储在c1.txt文本文件中如下:

图1 c1文件中样本数据
在matlab中载入文件
分别将原始数据中的两列提取出来作为x坐标与y坐标用于绘制样本的分布图像,其实现如下:

图2
接下来通过linkage(c1,'single','euclidean')语句调用linkage函数,将样本点以最短距离作为类间距离,距离计算采用欧几里得距离,得到一个矩阵,其前2列为两个类的标号,第三列为类间的最短距离,然后通过dendrogram函数可以绘制出层次聚类树状图

图3
以上操作后结果如下:
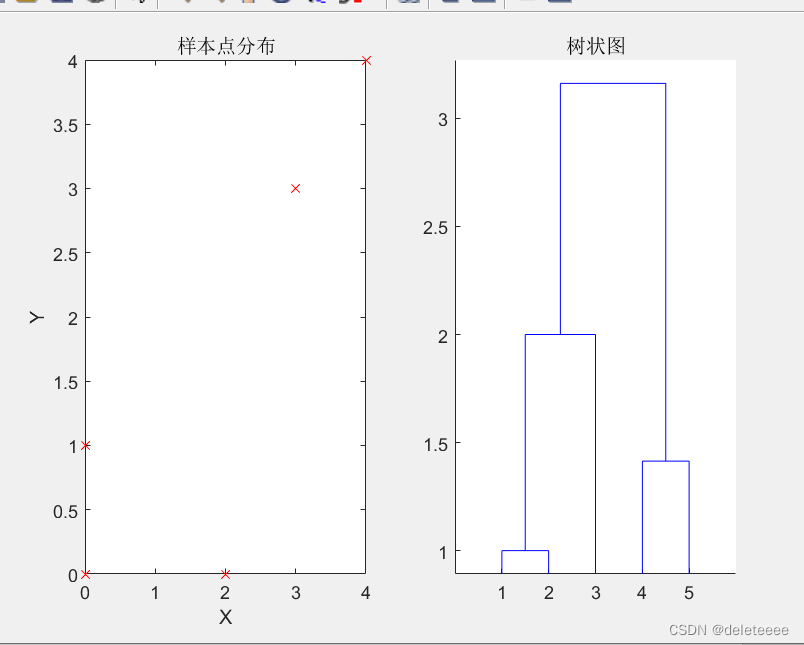
图4 样本分布及聚类树状图
接下来为了进行分类,可以通过分割的方法得到不同的簇,这里采用群数目分割方式进行分割,调用cluster函数,设置簇的数目最大为2,最后调整标号绘制分类后的图像
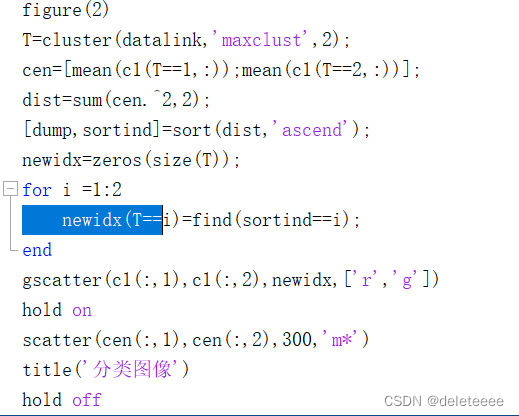
图5
结果如下:
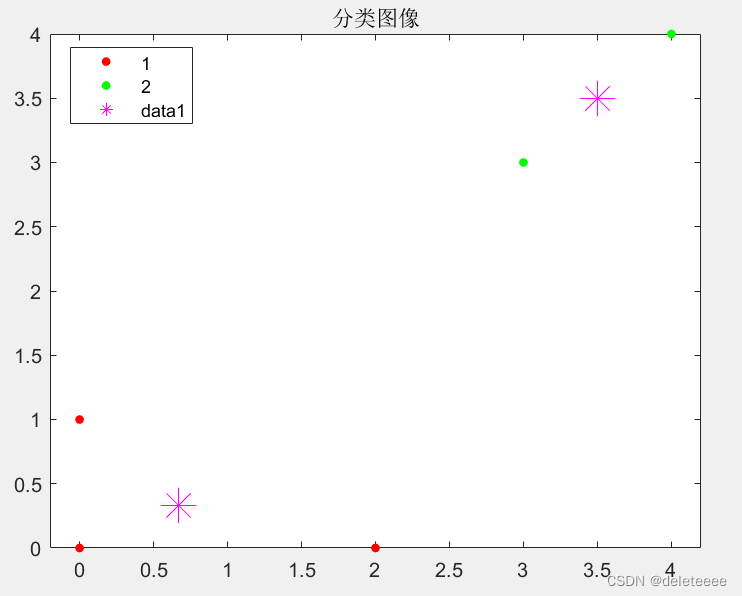
图6 分割后得到的结果
2.k-means聚类:
样本点:x1= [0,0]T, x2=[1,0]T, x3=[1,1]Tx4= [4,4]T, x5=[5,4]T, x6=[5,5]T
同样将样本点数据存储到kn1.txt文件中,如下图:
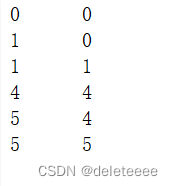
图7 kn1文件中样本数据
接下来开始进行聚类,实验设置簇的个数为2,通过kmeans函数对样本进行聚类,并且重复5次聚类,该函数可以返回簇的索引以及簇的中心点位置。

图8
然后调整标号绘制分类图像,结果如下:
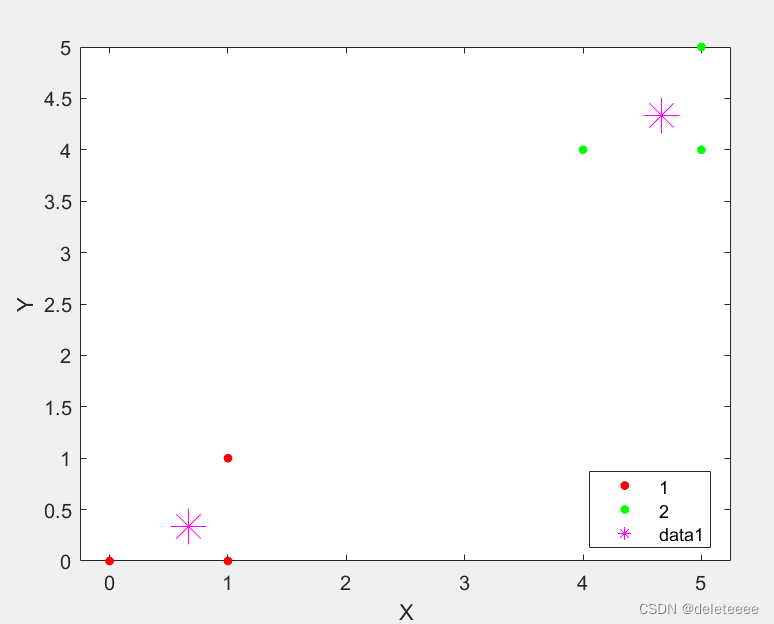
图9 kmeans 聚类结果
3. 结果与分析
1.层次聚类
通过树状图可以看出程序的聚类顺序为x1x2,x4x5,x1x2x3,x1x2x3x4x5,每两个簇之间的距离如下:
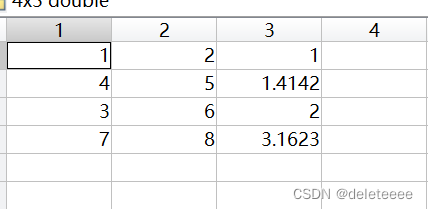
图10 聚类过程中簇间距离
其中前两列1至5代表x1到x5初始5个簇,6代表x1x2形成的簇,7代表x4x5形成的簇,8代表x1x2x3形成的簇
2.k-means聚类
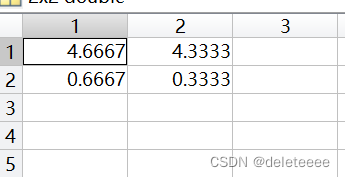
图11 聚类后两个簇的中心点坐标
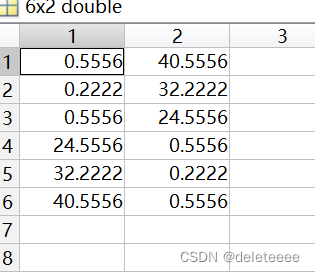
图12 每个点到每个簇心的距离
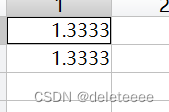
图13 簇内各点到中心距离之和