*MYSQL--索引--内部原理
MYSQL的索引根据功能,主要有三大类型:
1.HASH索引
2.二叉树
3.BTREE索引
一:HASH索引
1.内部原理:
在设置了某列为索引列之后,并且开始或者将要在相应索引列创建数据的时候,系统通过某种算法 F(X) 自动计算出来一个十六进制的哈希值,这个哈希值能够对应相应的字段值 所以,在之后如果使用HASH查询的时候,可以直接通过计算索引值在刚开始创建时所得的哈希值,通过这个哈希值再对应相应的索引值,达到直接搜索的目的,而不是再全表搜索,大大提高了搜索效率
2.优点:
通过字段值计算出相应的HASH值,定位数据,搜索数据非常的快,但是也要注意一点,不同的字段时可能够有相同的哈希值的,即一个哈希值可能够对应了多个字段,这被称为哈希冲突,但即使如此也大大缩小了查找的范围,一定程度上也提高了查找的效率
3.缺点:
没有办法进行范围查找,因为通过哈希值进行查找所得的都是具体的结果,并且其中的值都是无序的,无法进行大小的比较
二:二叉树
1.内部原理:
类似于树的形状,最上面是根节点,每一个节点最多只有两个分叉,往左为左子树,右边是右子树,同样的,往左边的一个点,或者是往右边的也是一个根节点,根节点往左均为左子树,往右均为右子树.

2.优点:
了解了左子树与右子树的概念之后,对与跟节点来说,其左子树都是小于它的数字,右边的数都是大于它的数字.从而使得查询速度更快一些
3.缺点:
1>因为这种特性,也可能会出现一些其他的情况,比如类似于链接的结构,从1-->2-->3... 这种特殊的不平衡,会使得其查询跟平常的全表查询相当,并没有用到二叉树查询
2>同样的,这种二叉树查询也无法进行范围性的查询,需要回旋,反复的进行寻找,所以无法进行范围查询
三:BTREE
BTREE查询有两种,分别是:B-TREE 以及B+TREE两种
1.B-TREE:
可以先设置节点的多少,比方说MAX.DEGREE=3的时候,就代表一个节点最多只能够有2个数据,如果再多会将中间的值 向上提取 出来,再添加数据,根据数据的大小,再进行重复的操作,从而形成一个类似于树的形状

(图为以3为最大节点的B-TREE图像)
2.B+TREE:
B+TREE索引实际上跟B-TREE索引的大概原理是一样的,但是有一点,B+TREE索引在使用的时候,比如说设置节点最大值为3,插入0001,0002,再进行插入的时候,会将中间的'映射',向上提取出来,而操作原本的数据,并不将原本的数据向上提取,而是提取了'映射'.
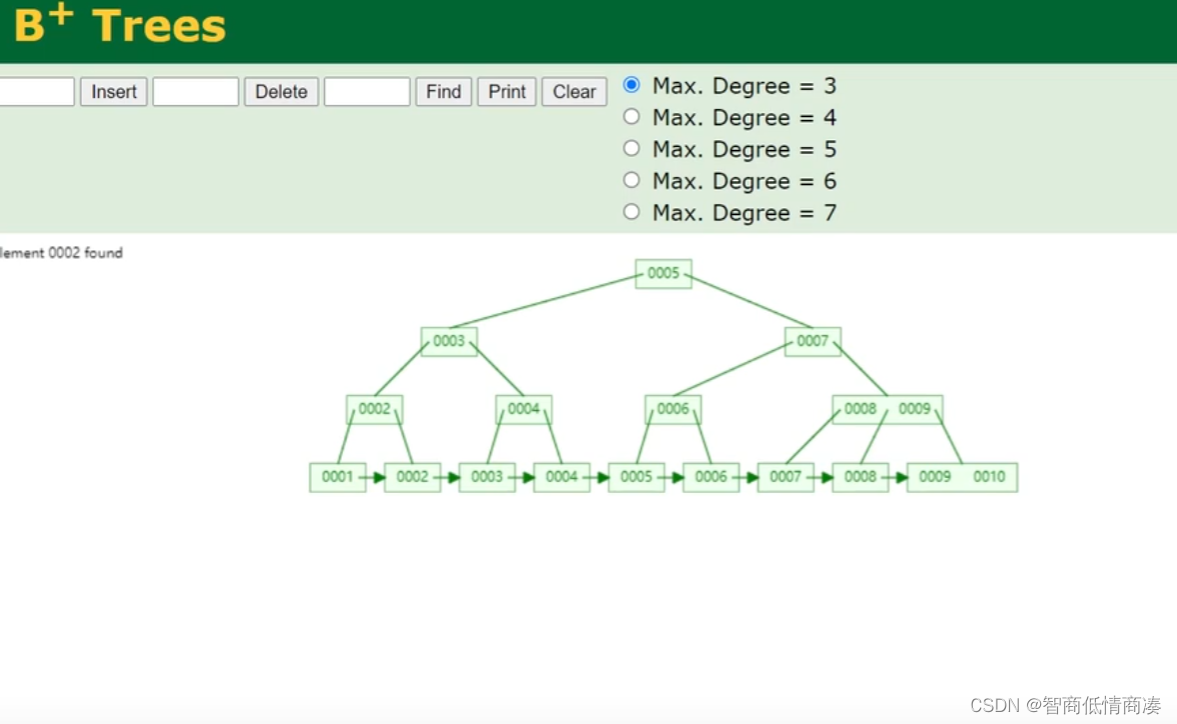
(图为以3为最大节点的B+TREE图像)
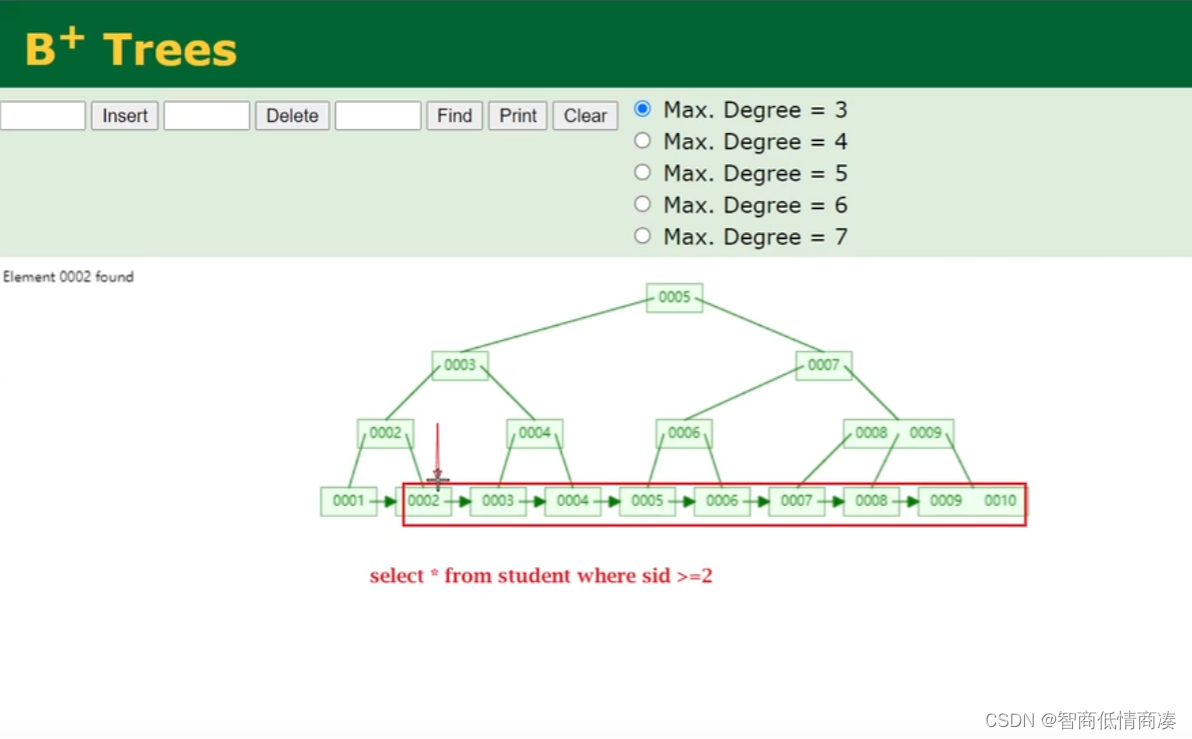
TIPS:值得注意的一点是,通过这一保存原本数据的特性,我们就能够使用B+TREE索引进行范围查找了,也大大节省了磁盘扫描的时间
 四.BTREE索引对于存储引擎的应用:
四.BTREE索引对于存储引擎的应用:
1.MylSAM存储引擎:
MylSAM存储引擎使用的是:B+TREE索引,例如,查询某个具体的值的时候,MylSAM先看索引列的值,根据指针判断其大小,之后再向下,左子树或者是右子树进行寻找,直到查询到某个需要的叶节点,叶节点的DATA存放的是数据记录的一个地址值,之后再通过地址值进行寻找,获得相应的结果

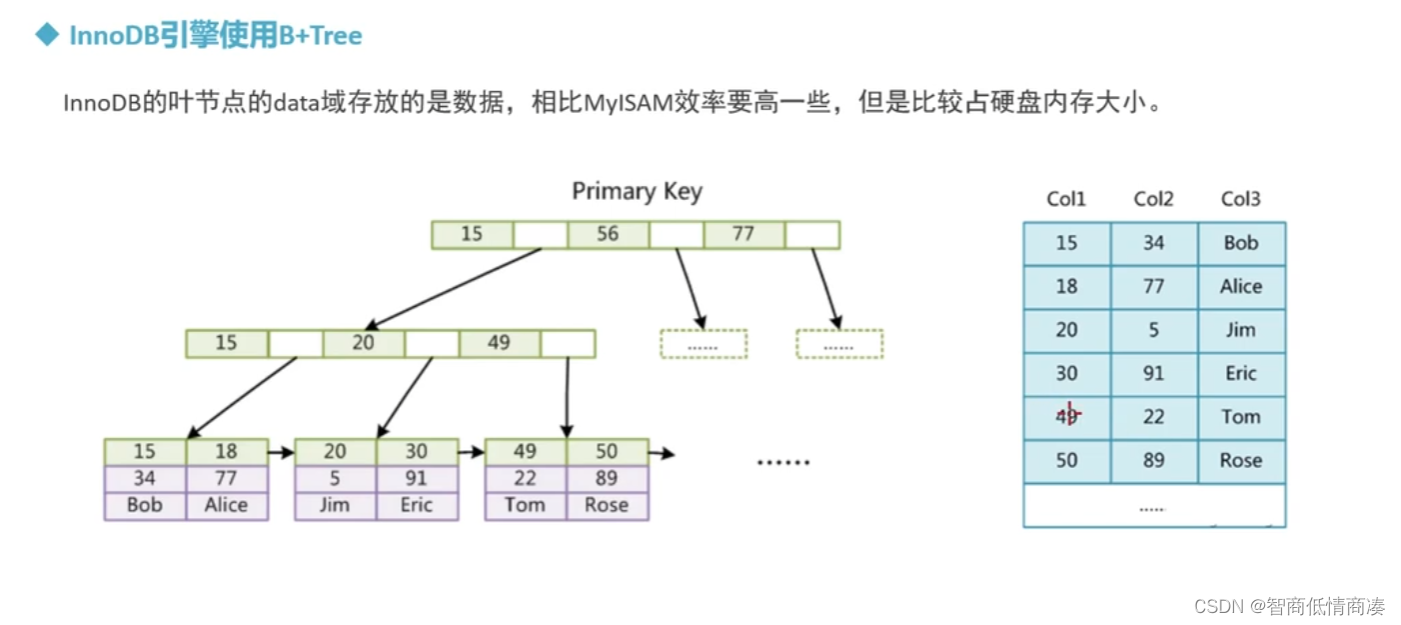
2.InnoDB引擎:
依旧是根据B+TREE建立的引擎,大部分跟MYLSQM有些不一样的一点就是,
InnoDB的叶节点的DATA存储的是数据!!!而不再是一个地址值,也就是说可以直接得到相应的值,索引效率要比MYLSAM高一些,但是直接对于地址值的存放,也使得比较'吃'硬盘内存的大小.
OVER!感谢观看