使用openai-whisper实现语音转文字
使用openai-whisper实现语音转文字
1 安装依赖
1.1 Windows下安装ffmpeg
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。
# ffmpeg官网
https://ffmpeg.org/# ffmpeg下载地址
https://ffmpeg.org/download.html# 点击下载后会进入github,地址如下
https://github.com/BtbN/FFmpeg-Builds/releases
在官网上选择windows版本
推荐使用ffmpeg-n5.1.4-win64-gpl-5.1.zip 和 ffmpeg-n6.0.1-win64-gpl-6.0.zip这两个版本,因为ffmpeg 5.1.4 和 ffmpeg 6.0.1版本是最新稳定版。
# Auto-Build 2023-11-30的地址
https://github.com/BtbN/FFmpeg-Builds/releases/tag/autobuild-2023-11-30-12-55# ffmpeg-n5.1.4-win64-gpl-5.1.zip的地址
https://github.com/BtbN/FFmpeg-Builds/releases/download/autobuild-2023-11-30-12-55/ffmpeg-n5.1.4-win64-gpl-5.1.zip# ffmpeg-n6.0.1-win64-gpl-6.0.zip的地址
https://github.com/BtbN/FFmpeg-Builds/releases/download/autobuild-2023-11-30-12-55/ffmpeg-n6.0.1-win64-gpl-6.0.zip
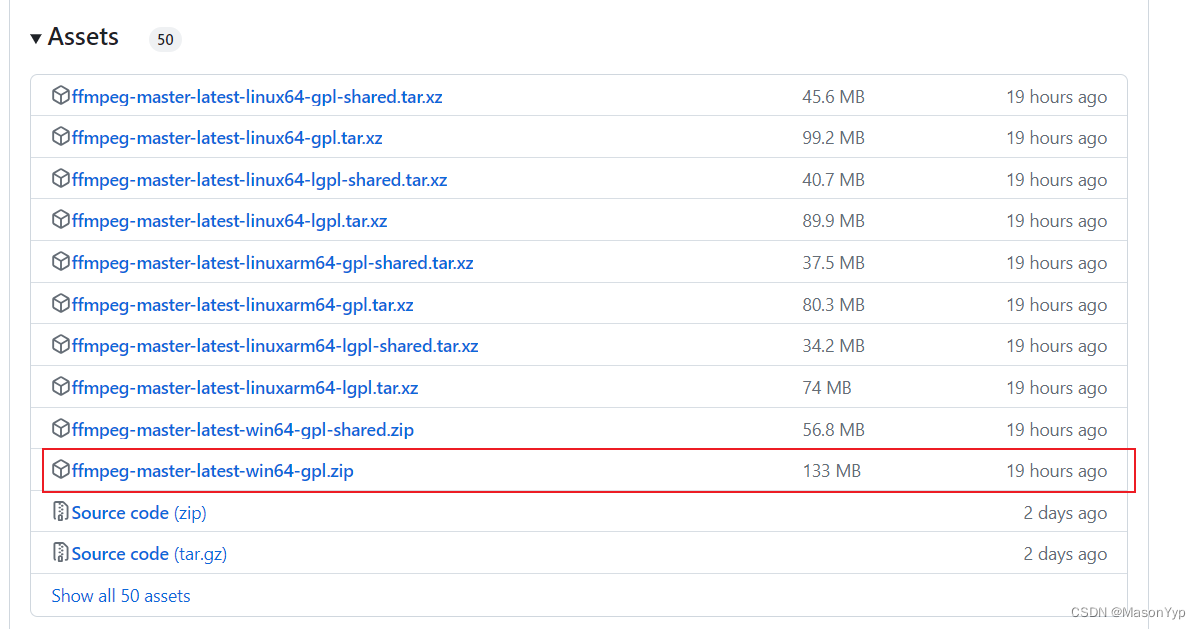
在GitHub上可以选择最新版本,选择ffmpeg-master-latest-win64-gpl.zip;
⚠️ 如果python程序出现“FileNotFoundError: [WinError 2] 系统找不到指定的文件。”错误时,可能是ffmpeg版本的问题。
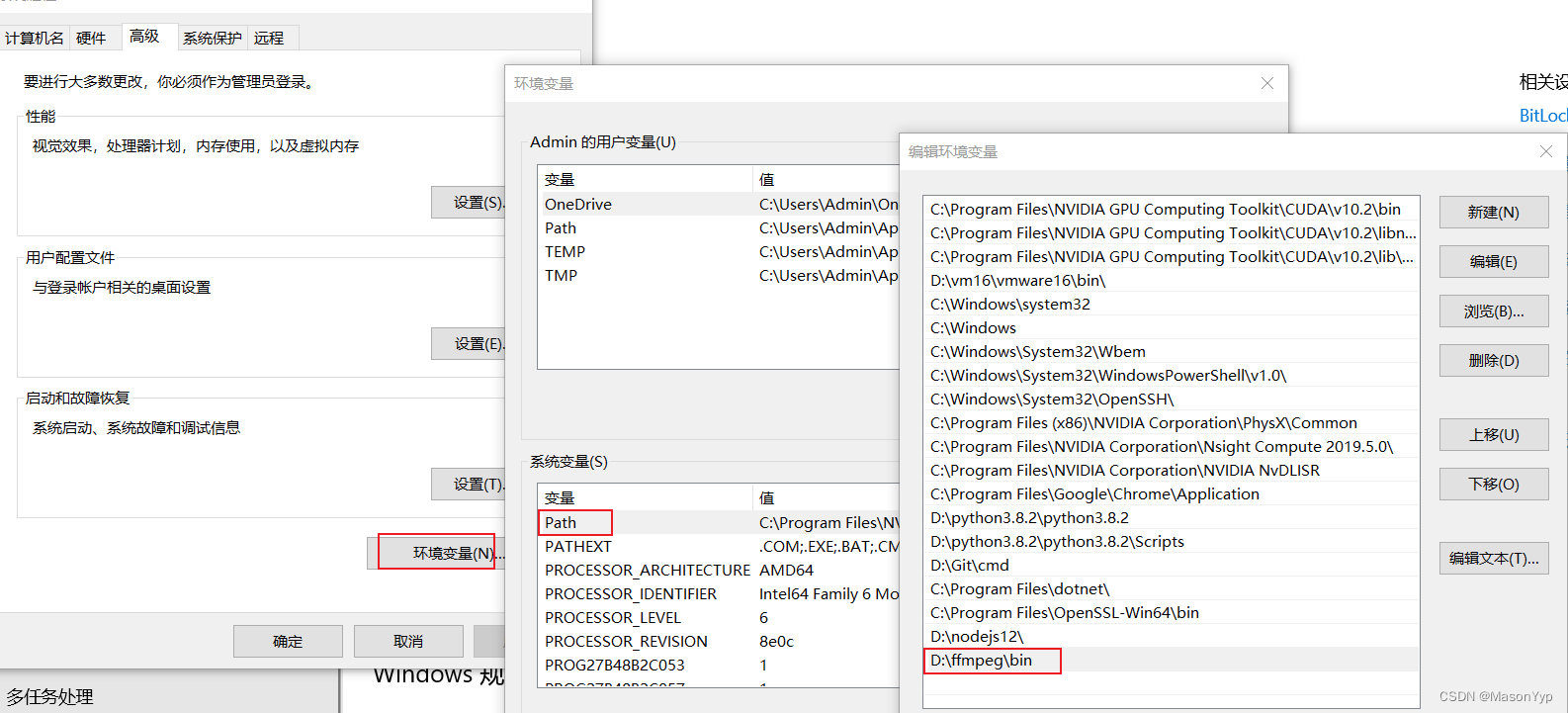
将ffmpeg-master-latest-win64-gpl.zip 解压到D盘,名字修改为ffmpeg, 将目录 D:\ffmpeg\bin 添加到环境变量中。
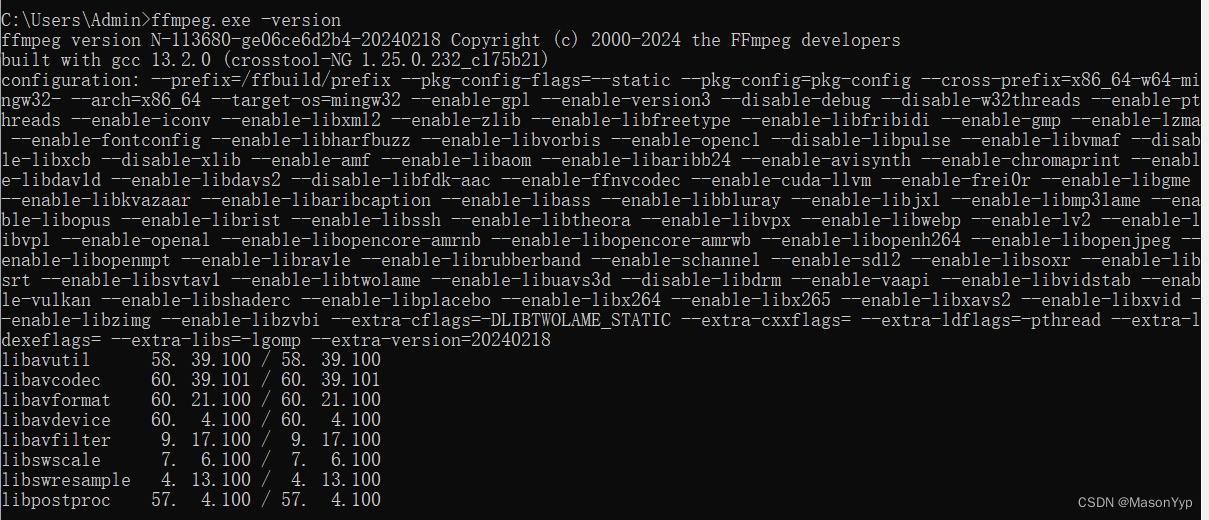
在dos页面查看版本号中输入:ffmpeg.exe -version,出现下面的信息表示安装成功。
1.2 安装openai-whispe
# whispe地址
https://github.com/openai/whisper# 安装openai-whisper
pip install openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装pydub切割音频,防止音频太长
pip install pydub -i https://pypi.tuna.tsinghua.edu.cn/simple
下载语音,可以直接在浏览器中打开,再下载
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
2 使用openai-whispe
2.1 工程目录
2.2 main.py
import whisper
model = whisper.load_model(name="tiny", download_root="./model")# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(".//data//zh.wav")
audio = whisper.pad_or_trim(audio)# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)# print the recognized text
print(result.text)
输出结果:
Detected language: zh
我認為跑步最重要的就是給我帶來了身體健康