RAG 语义分块实践

每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
原文标题:Semantic chunking in practice
原文地址:https://medium.com/@boudhayan-dev/semantic-chunking-in-practice-23a8bc33d56d

回顾
2023年真是不平凡的一年!充实、丰富多彩,最重要的是,在软件开发领域取得了许多突破。
其中一个突破性进展是企业级成熟的 LLM (大型语言模型)的可用性,已经引起了行业的轰动,相信在 2024 年会有更大的发展。LLM 将成为主流,并将融入到软件和产品开发的各个方面。从商业人工智能到游戏,LLM 的影响将触及每一个领域。
是好是坏?只有时间才能证明。军备竞赛已经开始,没有回头路可走。
不过,从技术角度来看,LLM 是一个非常有趣的话题。我一直忙于了解 LLM 的最新运作情况。作为一名非数据科学家,这既让人望而生畏,又让人大开眼界。不同 LLM 的能力——多模态/单模态等,各种提示技术——ReAct、CoT(思维链)等,RAG——检索增强生成,微调……等等。我有幸参与了这些课题的研究。这些课题非常广泛,而且在不断发展。没有两个路障是相同的,而这正是让 LLM 之旅如此激动人心的原因。
本博客将讨论其中的一个障碍——分块。或者更确切地说,对文档的各个部分进行语义分块,以便(作为提示的一部分)反馈给 LLM 的数据对于提示的上下文来说更加精确和有意义。
让我们开始吧。
问题
考虑一下,你得到了一个包含一些文本和图像的文档,这些内容被组织成若干部分(也可能是嵌套的部分),就像一本书/小说/结构文档一样。
换句话说,您可能遇到过的任何结构化文件。
现在的问题是分割文档并提取各个部分内容,即保留块的语义含义。在你提出解决方案之前,这里有一些额外的限制(真实场景中的) —
-
如前所述,必须将分块映射到章节,即不能根据页码、字数/字符长度等随意创建分块。
-
文档没有目录或内容表。
-
不要假设各个部分的大小。有些部分可能只有几段,而有些可能延伸到数页。
-
不要假设文档中各个部分的起始/结束位置。它们可能在页面的开头/结尾,也可能不在。它们也可能很好地从页面的中间开始。
-
不要假设文档的字体大小/样式。我们需要支持所有类型的文档。
-
毋庸置疑,文档的大小超过了你可以用来解决这个问题的 (你会用吗?😛)的上下文大小(LLM 提示可以接受的最大标记数)。
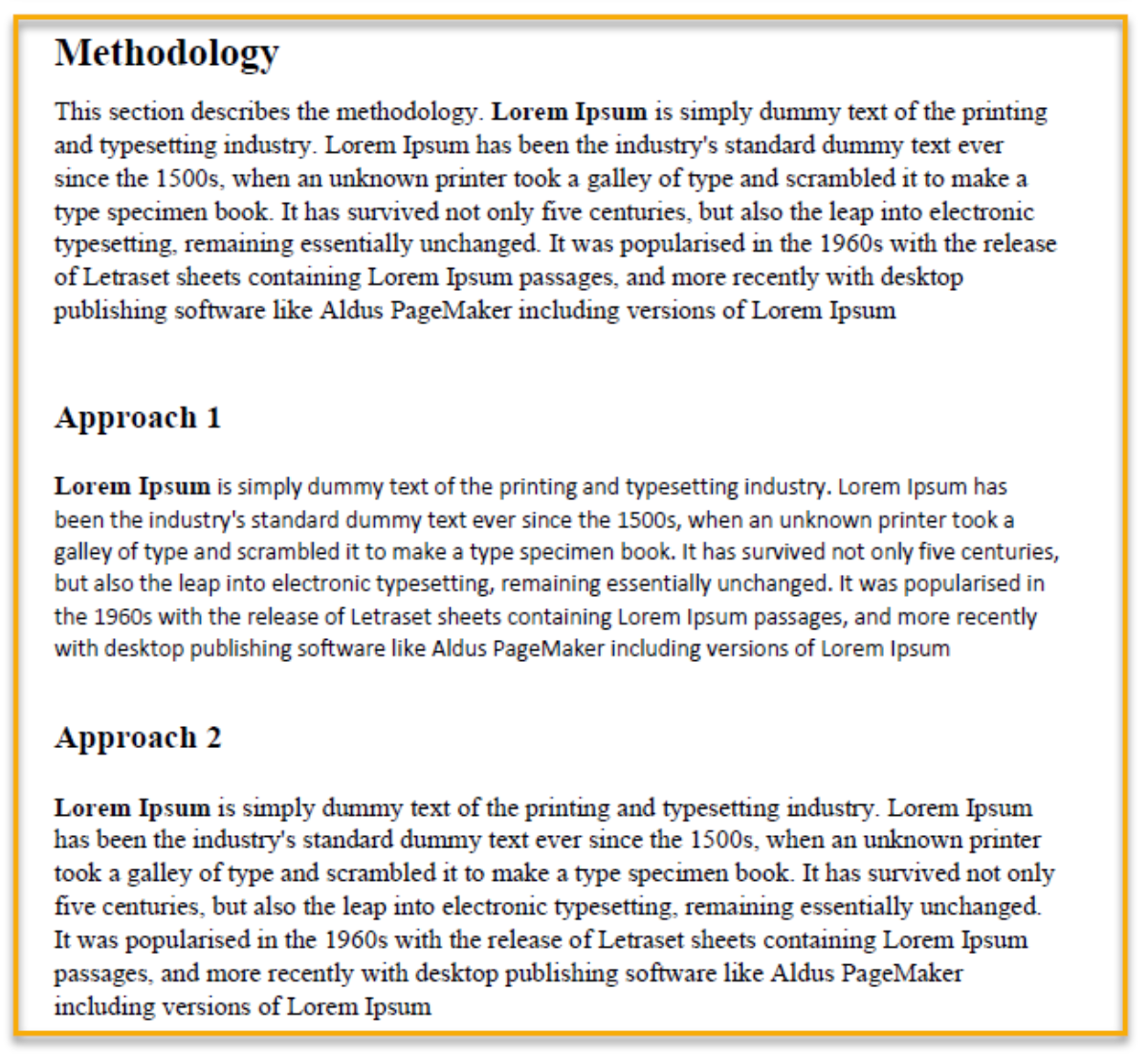
例如,考虑文档中的一页,如下所示 —

这是文件中的一页,显示了如下结构——
-
Prologue
-
Methodology
注:在方法论下的方法1和方法2我已经忽略了,因为它们的相对字体高度比方法论小,表明它们是子部分。然而,如果你按以下方式识别部分结构,也是正确的。例如 —
注:我忽略了 "Methodology "下的 "Approach 1 "和 “Approach 2”,因为它们的相对字体高度比 “Methodology” 小,表明它们是子章节。不过,如果你将各部分的结构确定如下,也是正确的。例如——
-
Prologue
-
Methodology
-
Approach 1
-
Approach 2
你想要识别的嵌套级别由你决定。你可以选择将子部分组合在一起作为一个主要部分(如示例1),也可以将它们呈现为单独的部分(如示例2)。重要的是首先要识别这些部分。
您可以自行确定嵌套的程度。您可以选择将子章节合并为一个主要章节(如例 1),也可以将它们作为单独的章节(如例 2)。重要的是首先要识别这些部分。
例 1

例 2


那么,考虑到上述限制,如何提取这些部分呢?
注:由于该文件的候选者数量庞大,预计准确率不会达到 100%。
设计
正如你所猜测的那样,解决方法并不简单。至少,不能用确定性算法来解决。我们所讨论的是从文档中自主检测和提取部分内容。如果这还不够困难的话,我们还打算让解决方案适用于任何类型的文档,例如所使用的字体、书写风格、内容格式等。
困难?当然,但并非不可能。 在 LLM 时代,绝对不是。
在尝试解决方案之前,我们先来看看以下几点。
观察 1 -> 对于任何结构良好的文档,各部分的大小都会遵循一种模式,即第一级部分的字体大小和样式相同,如 2X,下一级部分的字体大小可能较小,如 X,以此类推…但它们在整个文档中都是一致的。
观察 2 -> 章节页眉/标题通常均匀地分布在整个文档中。它们不会集中在文档的开头或结尾。因此,在整个文档中,遇到章节标题/页眉的机会很大。
观察 3 -> 与文件中的段落或非章节文本相比,章节标题/页眉较少。
观察 4 -> 与周围的文本块相比,章节标题/页眉一般比周围的文本大(字体大小),字符数也较少。
就是这样!只要我们能确定章节标题/页眉在文档中的位置,我们就能提取出随后两个章节之间的文本块,从而实现我们的目标。
为了将某一行识别为可能的章节标题/页眉,我们将使用 LLM(任何 LLM 都可以,本博客使用的是 GPT 3.5)。
还有什么比 LLM 更适合对给定文件进行上述推理呢?
现在,让我们来看看实现情况。
解决方案
让我们从添加依赖项开始。我们将使用 Java。为了解析文档,我们将使用 Apache PDFBox 库。
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.27</version>
</dependency>
现在,PDFBox 库中的默认 PDF 阅读器类将不提供我们感兴趣的元数据,即字体大小、行中的总字符数,以及具有相同元数据的相应行。为了记录这些元数据(为什么?稍后会解释),在我们通过文档时,我们将不得不创建一个自定义文本解析器来记录它们。
让我们创建一个可以捕捉字体元数据的模型。
@Data
public class DocumentLineItem {float positionX;float positionY;String content;int fontHeight;int totalCharacters;@Overridepublic String toString(){return this.content;}
}
现在,让我们来实现文本解析器。
public class TextParser extends PDFTextStripper {private static final Logger