10MARL深度强化学习 Value Decomposition in Common-Reward Games
文章目录
- 前言
- 1、价值分解的研究现状
- 2、Individual-Global-Max Property
- 3、Linear and Monotonic Value Decomposition
- 3.1线性值分解
- 3.2 单调值分解
前言
中心化价值函数能够缓解一些多智能体强化学习当中的问题,如非平稳性、局部可观测、信用分配与均衡选择等问题,然而存在很难直接学习价值函数等问题,特别是动作价值函数难以学习,原因是联合动作空间随智能体个数呈指数增长的问题,因此本文章学习如何有效的学习价值函数且最大化共同和奖励过程
1、价值分解的研究现状
价值函数如何分解才能更好的学习已经具有很长的研究历史,通过多智能体在交互过程中并非所有智能体互相之间都存在交互过程这一观点,提出了coordination graph,稀疏的协作图能够近似联合动作函数作为交互智能体的价值和,能够更高效的评估价值,例子如下:
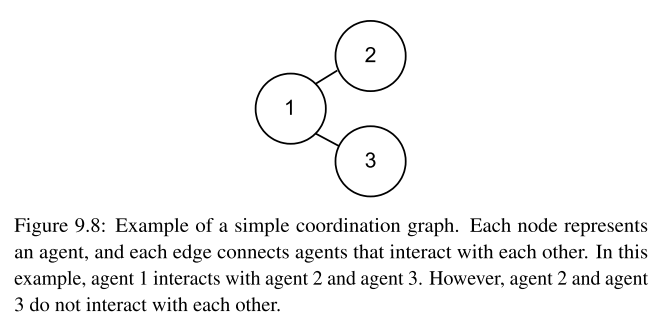
在共同和奖励过程,已经有很多成功的价值分解算法应用到价值函数的学习中,价值分解算法能够将价值函数分解为更简单的函数,在共同和奖励过程能够更高效的学习,中心动作价值函数能够表示为如下(共同奖励过程):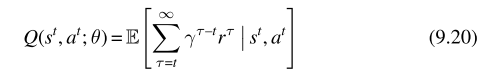
2、Individual-Global-Max Property
最简单的分解Q函数的方法便是每个智能体单独学习效用函数,只与其历史观测序列与动作有关,这些效用函数采用相同的结构如下所示:
之所以称为效用函数是这些函数并不会去学习如何近似自身的期望回报,而是将所有智能体的效用函数联合优化近似中心动作价值函数并且满足individual-global-max(IGM)性质
为了定义IGM性质,引入中心化动作价值函数与效用函数的贪婪动作,如下所示: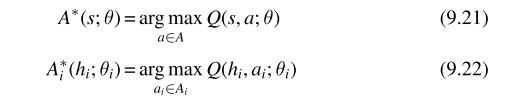
其中 Q ( s , a ; θ ) Q(s,a;\theta) Q(s,a;θ)表示中心动作价值函数、 Q ( h i , a i ; θ i ) Q(h_{i},a_{i};\theta_{i}) Q(hi,ai;θi)表示智能体i的效用函数
IGM性质满足以下关系:
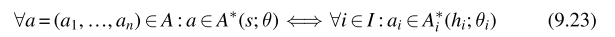
解释:如果联合动作相对于中心动作价值函数是贪婪的,那么相对于效用函数来说每个智能体i在联合动作中自身的动作也是贪婪的,也就是说如果智能体i相对于自身的效用函数选择贪婪动作,那么相对于分解中心动作价值函数,单个贪婪动作组成的联合动作也是贪婪的
在满足IGM的条件下,每个智能体能够根据自身的效用函数选择贪婪动作,那么所有的智能体能够一起选择贪婪的联合动作,效用函数除了能够简单的分解中心动作价值函数之外,还能够评估每个智能体在共同奖励过程中的贡献,这样来看,价值分解还能够在一定程度上减轻信用分配问题
3、Linear and Monotonic Value Decomposition
3.1线性值分解
满足IGM性质是假设共同奖励过程满足线性分解,每个智能体单独的奖励等于整体的奖励
r t = r ‾ 1 t + ⋯ + r ‾ n t r^{t}=\overline{r}_{1}^{t}+\cdots+\overline{r}_{n}^{t} rt=r1t+⋯+rnt
在改假设的基础之上,中心动作价值函数能够分解为如下:

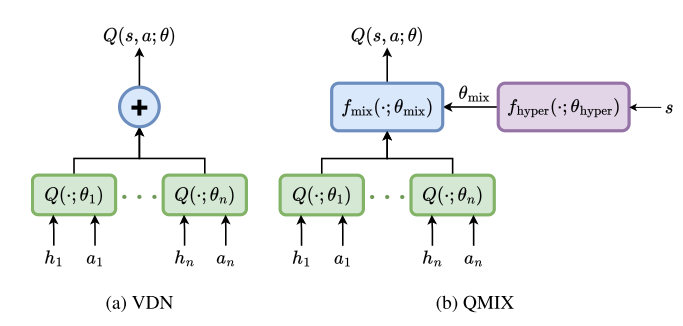
基于线性的分解方法提出VDN算法,通过维护包含所有智能体经验的回收池以及采用所有智能体联合优化得到近似中心化价值函数,其损失函数如下:
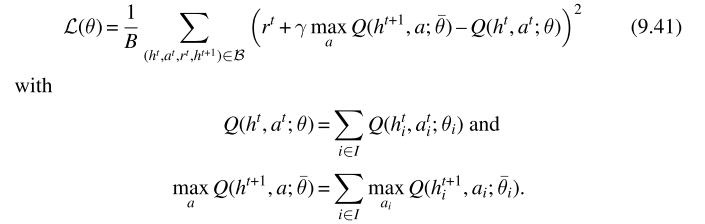
3.2 单调值分解
在一些情况下,每个智能体的贡献在非线性的情况下具有更好的表现,线性分解无法起到作用
在满足IGM的前提下,还需要满足中心化动作价值函数相对于每个智能体的效用函数的导数为正,如下图所示:
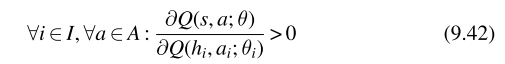
那就意味着每个智能体采取动作后效用函数增加,那么采取相对应联合动作后中心价值函数也会增加
QMIX网络采用DQN作为每个智能体的效用函数,同时定义了一个混合网络用于聚合所有智能体的效用网络近似中心化的动作价值函数
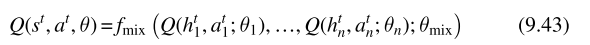
在实际应用中,mix网络对于输入的权重均为正,通常mixing函数的参数通过额外的超参数网络获得,该网络用所有的状态作为输入,输出mixing网络的参数,为了保证mixing网络参数为正,超参网络采用绝对值函数作为激活函数,联合优化损失函数如下:

中心动作价值函数能够用如下的等式简单表达
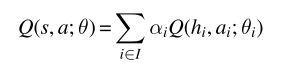
其中的权重系数均大于等于0,代表对应智能体的贡献,若系数为1,则代表线性分解
**一些值得注意的点:**首先所有的智能体的效用网络参数是共享的、智能体通过onehot编码进行区别、智能体效用网络能够建模成RNN网络、每个episode会存储所有的经验,在其结束后进行更新