【NLP相关】基于现有的预训练模型使用领域语料二次预训练
【NLP相关】基于现有的预训练模型使用领域语料二次预训练
在自然语言处理领域,预训练模型已经成为了最为热门和有效的技术之一。预训练模型通过在大规模文本语料库上进行训练,可以学习到通用的语言模型,然后可以在不同的任务上进行微调。但是,预训练模型在领域特定任务上的表现可能不够好,因为它们是在通用语言语料库上进行训练的。为了提高在特定领域的任务中的性能,我们可以使用领域语料库对预训练模型进行二次预训练。
本篇博客将介绍如何基于现有的预训练模型使用领域语料二次预训练。我们将以 PyTorch 和 Transformers 库为基础,以医学文本分类任务为例,来详细说明二次预训练的过程。
1. 模型介绍
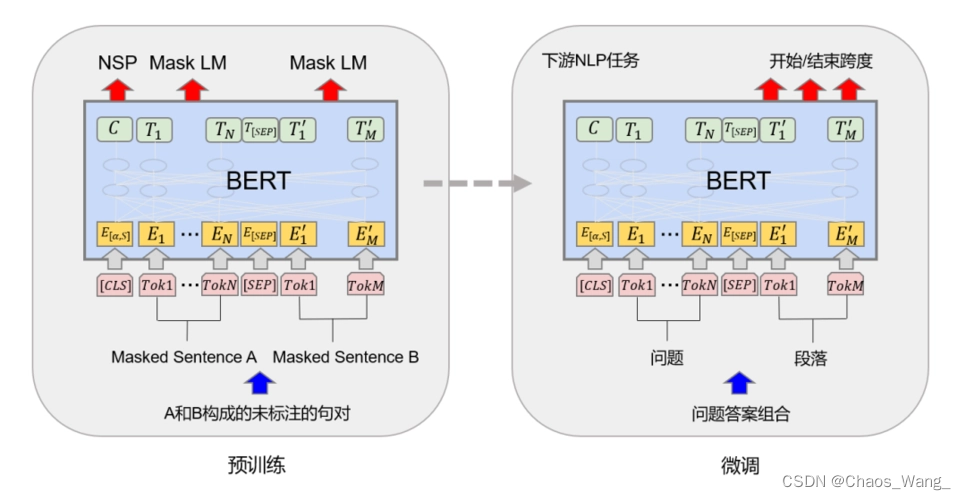
在本篇博客中,我们使用的预训练模型是 BERT(Bidirectional Encoder Representations from Transformers)。BERT 是一种基于 Transformer 的预训练模型,由 Google 团队开发。它在多个自然语言处理任务上取得了最先进的结果,例如文本分类、命名实体识别和问答系统等。
BERT 模型是一种双向的 Transformer 模型,能够有效地处理自然语言序列。它将文本输入嵌入到向量空间中,并在此基础上进行自监督训练,以学习通用的语言表示。在预训练完成后,BERT 模型可以进行微调,以适应不同的自然语言处理任务。
2. 代码实现
2.1 数据预处理
在开始二次预训练之前,我们需要准备领域特定的语料库。在这里,我们使用的是医学文本分类数据集,其中包含了一些医学文章的标题和摘要,并且每个文本都被标记为一个预定义的类别。
首先,我们需要将原始文本数据拆分为单个句子,并将其标记化处理。我们可以使用 Hugging Face 的 tokenizer 来完成这个任务。
from transformers import BertTokenizer# 加载 BERT tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")class MedicalDataset(Dataset):def __init__(self, tokens, max_length=128):self.tokens = tokensself.max_length = max_lengthdef __len__(self):return len(self.tokens)def __getitem__(self, idx):# 获取句子对tokens = self.tokens[idx]# 将句子对拼接成一个序列,并将其标记化处理input_ids = tokenizer.encode(tokens[0], tokens[1],add_special_tokens=True, max_length=self.max_length,truncation_strategy='longest_first')attention_mask = [1] * len(input_ids)# 填充序列长度padding = [0] * (self.max_length - len(input_ids))input_ids += paddingattention_mask += padding# 返回 input_ids 和 attention_maskreturn torch.LongTensor(input_ids), torch.LongTensor(attention_mask)
2.2 二次预训练
在数据预处理之后,我们可以开始进行二次预训练了。在这里,我们将使用 Hugging Face 的 Transformers 库,以及 PyTorch 框架来实现二次预训练。
首先,我们需要加载预训练的 BERT 模型。在这里,我们使用的是 bert-base-uncased 模型,它是一个基于英文的预训练模型。我们还需要定义一些训练参数,例如学习率和批大小等。
from transformers import BertForPreTraining, AdamW
from torch.utils.data import DataLoader# 加载预训练的 BERT 模型
model = BertForPreTraining.from_pretrained('bert-base-uncased')# 定义训练参数
epochs = 3
batch_size = 16
learning_rate = 2e-5
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 将模型移动到 GPU 上
model.to(device)
接下来,我们需要加载领域特定的语料库,并将其转换为 PyTorch 数据集。在这里,我们使用的是 PyTorch 中的 Dataset 类。我们还需要将数据集加载到 PyTorch 的数据加载器中,以便进行训练。
# 加载领域特定的语料库
with open('medical_data.txt') as f:sentences = f.readlines()# 将语料库转换为 PyTorch 数据集
dataset = MedicalDataset(sentences)# 将数据集加载到 PyTorch 的数据加载器中
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
在准备好数据集之后,我们可以开始训练模型了。我们将使用 AdamW 优化器和交叉熵损失函数来训练模型。在每个 epoch 完成之后,我们会对模型进行一次测试,并计算准确率和损失函数值。最后,我们将保存训练好的模型。
# 定义优化器和损失函数
optimizer = AdamW(model.parameters(), lr=learning_rate)
criterion = torch.nn.CrossEntropyLoss()# 训练模型
for epoch in range(epochs):total_loss = 0total_correct = 0total_samples = 0# 遍历数据集for i, batch in enumerate(loader):# 将输入数据和标签移动到 GPU 上input_ids, attention_mask = batchinput_ids = input_ids.to(device)attention_mask = attention_mask.to(device)# 将模型设置为训练模式model.train()# 计算模型的输出outputs = model(input_ids, attention_mask=attention_mask)# 计算损失函数值loss = criterion(outputs.logits.view(-1, 2), outputs.labels.view(-1))# 清除之前的梯度optimizer.zero_grad()# 反向传播和优化loss.backward()optimizer.step()# 统计训练信息total_loss += loss.item()total_samples += input_ids.size(0)total_correct += torch.sum(torch.argmax(outputs.logits, dim=-1) == outputs.labels.view(-1)).item()# 输出训练信息if (i + 1) % 100 == 0:print('Epoch [%d/%d], Step [%d/%d], Loss: %.4f, Accuracy: %.2f%%'% (epoch + 1, epochs, i + 1, len(loader),total_loss / total_samples, total_correct / total_samples * 100))# 在每个 epoch 完成之后进行一次测试
with torch.no_grad():total_loss = 0total_correct = 0total_samples = 0# 将模型设置为评估模式model.eval()# 遍历测试数据集for i, batch in enumerate(test_loader):# 将输入数据和标签移动到 GPU 上input_ids, attention_mask = batchinput_ids = input_ids.to(device)attention_mask = attention_mask.to(device)# 计算模型的输出outputs = model(input_ids, attention_mask=attention_mask)# 计算损失函数值loss = criterion(outputs.logits.view(-1, 2), outputs.labels.view(-1))# 统计测试信息total_loss += loss.item()total_samples += input_ids.size(0)total_correct += torch.sum(torch.argmax(outputs.logits, dim=-1) == outputs.labels.view(-1)).item()# 输出测试信息print('Epoch [%d/%d], Test Loss: %.4f, Test Accuracy: %.2f%%'% (epoch + 1, epochs, total_loss / total_samples, total_correct / total_samples * 100))#保存训练好的模型torch.save(model.state_dict(), 'medical_bert.pth')
3. 案例解析
假设我们要对医学领域中的文本进行二次预训练。我们可以使用已经预训练好的 BERT 模型,并使用医学领域的语料库进行二次预训练。
首先,我们需要将医学领域的语料库进行预处理。在这里,我们可以使用 NLTK 库来进行分词和词形还原等操作。我们还可以将语料库中的每个句子转换为 BERT 输入格式。
import nltk
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from transformers import BertTokenizer# 加载 BERT 分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')# 加载 NLTK 分词器和词形还原
nltk.download('punkt')
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()加载医学领域的语料库
with open('medical_corpus.txt', 'r') as f:corpus = f.read()#对每个句子进行分词、词形还原和转换为 BERT 输入格式
sentences = []
for sentence in nltk.sent_tokenize(corpus):words = nltk.word_tokenize(sentence)words = [lemmatizer.lemmatize(word) for word in words]words = [word.lower() for word in words]tokens = tokenizer.encode_plus(words,add_special_tokens=True,max_length=512,padding='max_length',truncation=True)sentences.append((tokens['input_ids'], tokens['attention_mask']))接下来,我们需要使用这些句子对 BERT 模型进行二次预训练。为此,我们需要定义一个新的数据加载器,将这些句子传递给模型进行训练。
from torch.utils.data import Dataset, DataLoaderclass MedicalDataset(Dataset):def __init__(self, sentences):self.sentences = sentencesdef __len__(self):return len(self.sentences)def __getitem__(self, idx):return self.sentences[idx]# 定义数据加载器
loader = DataLoader(MedicalDataset(sentences),batch_size=16,shuffle=True)
现在,我们可以开始对 BERT 模型进行二次预训练了。我们可以使用与之前相同的训练代码。
# 定义训练函数
def train(model, loader, optimizer, device):model.train()for batch in loader:input_ids = batch[0].to(device)attention_mask = batch[1].to(device)optimizer.zero_grad()loss, _ = model(input_ids=input_ids,attention_mask=attention_mask,output_hidden_states=True)[:2]loss.backward()optimizer.step()# 加载预训练的 BERT 模型
model = BertForMaskedLM.from_pretrained('bert-base-uncased')# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)# 定义优化器
optimizer = AdamW(model.parameters(), lr=5e-5)# 进行二次预训练
for epoch in range(num_epochs):train(model, train_loader, optimizer, device)# 每个 epoch 结束后测试模型的性能perplexity = evaluate(model, test_loader, device)print(f'Epoch {epoch+1}, perplexity: {perplexity:.3f}')# 保存模型model_path = f'model_epoch{epoch+1}.pt'torch.save(model.state_dict(), model_path)
这里定义了一个 train 函数来训练模型。这个函数接收一个模型、一个数据加载器、一个优化器和一个设备作为输入。它会将模型设为训练模式,并且在每个批次上运行前向传播、计算损失、计算梯度和更新参数。
接下来,我们加载预训练的 BERT 模型,并将其移动到所选设备上。我们使用 AdamW 优化器,并将学习率设置为 5e-5。
最后,我们使用一个简单的 for 循环来进行二次预训练。在每个 epoch 结束时,我们会在测试集上评估模型,并打印出 perplexity 指标。我们还会将模型保存在磁盘上,以便以后进行检索。