深入理解ES的倒排索引
目录
数据写入过程
词项字典 term dictionary
倒排表 posting list
FOR算法
RBM算法
ArrayContainer
BitMapContainer
词项索引 term index
在Elasticsearch中,倒排索引的设计无疑是惊为天人的,下面看下倒排索引的结构。
倒排索引分为词项索引【term index】、词项字典【term dictionary】、倒排表【posting list】
数据写入过程
先看一个原始数据录入的过程,原始数据录入的过程包含切词、规范化、去重、字典化等这么几个步骤,
I am going to bejing这句话,
切词就是将这段英文按照空格进行字段切分,这个就是所谓的分词器的功能,中文也有自己的分词器,当然还可以自定义分词器
分完词以后就是规范化,规范化的过程就是去掉一些语气词,过去分词、现在分词转换成同义词,比如将going转换成go
去重很简单,就是去掉一些重复的词项
字典化就是将这个数据保存起来,用一个id做出对应的映射
词项字典 term dictionary
就是将一段话进行分词以后得到的结果,比如上面的话就会得到go 、bejing等基础信息,可以看到词项字典的数量是原始数据的很多倍
词项字典的数据结构是FST
在介绍FST之前,先介绍下prefix Tree,前缀树的优点是能充分的利用数据空间,比如abc,和abcd这两个词,底层可以共用abc,这样就能大大的节省数据存储占用的空间
但是前缀树有一个缺点就是比如fbcd,这个词的bcd和abcd的后四位是相同的,但是因为前缀树的特点,后四位不能充分利用
而FST是在前缀树的基础上做了改进,能够充分的利用相同的字符来存储,大大提升存储的效率。
倒排表 posting list
倒排表的数据结构是一个有序的数组,数组中记录的是当前词项对应原始数据的id,比如bejing这个词项有很多原始数据对应,id有1,3,5,7
倒排表有两种常见的压缩算法
FOR算法
FOR算法的全称是frame of reference,这个算法的流程大致如下
- 原始数据比如是[1,3,6,7]这样,可能很长,在java中一个int是占用4个字节,可能通过切分词以后,倒排表的数据占用空间比原始数据还要大
- 这个时候,因为数组是有序的,可以将数组的每一项都减去前一项来代替当前的值,比如[1,2,3,1]
- 可以看到,通过这个简单的变形,倒排表的数组中的数据都减小了
- 然后就可以通过更小的bit来表示一个int的数,比如我可以用3个bit来表示上面的每一个数,这样的数据占用空间就会小很多,极限的情况下数组是连续的,可以使用一个bit来表示一个int数,可以减少到原来的1/32
- 当然实际情况下,数组不一定是连续的,这个时候可能就会使用分组了,比如3,5,7我使用4个bit来表示,6787,35465,,44656使用14bit来表示,这样想比使用32bit可以节省不少空间
从网上找到一张图,可以很好的说明这个算法
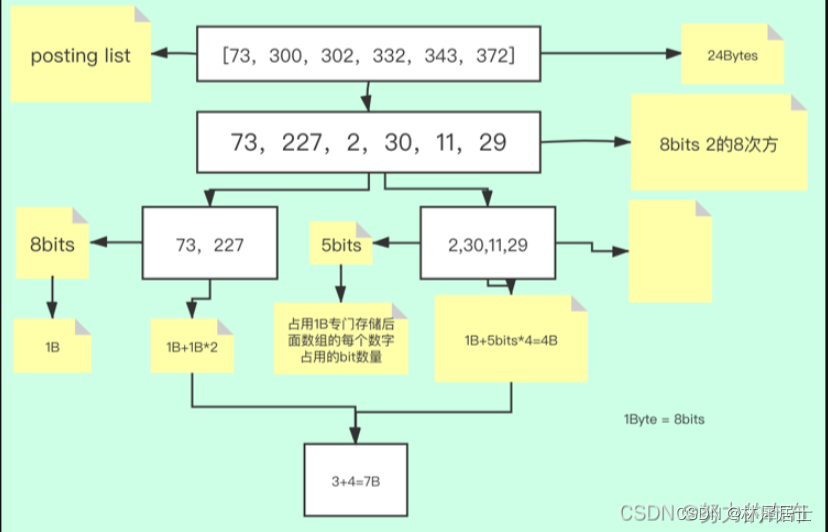
通过上面的案例可以发现,FOR算法的适用场景是,倒排表的数据排列比较稠密,即相邻元素之间的差值比较小,差值比较小,就可以使用更少的bit来表示一个int的数字了。
RBM算法
记住是RBM,不是RMB,不是RMB,不是RMB
RBM算法的全称是roaringBitMap
可以考虑倒排表中的元素大小是N,N的范围是【0,2^32-1】,因为int是32bit
那么将N/65536这个结果M是多少呢?他的余数K是多少呢
65536是2的16次幂,那么这个M的范围就是[0,65535],毫无疑问N的范围也是[0,65535]
可以看到M就是当前元素N的高16位,K就是当前元素N的低16位
那么,可以设置这样一个数据类型
short在java中是占用2个字节,也就是2*8=16bit,16位bit最大能表示就是65535
ArrayContainer
Map<short,List<Short>>
解释下这个数据结构
key存储的是当前N的的高16位,即M,然后将这个倒排表中所有高位都是M的其他元素的低16位K汇总,聚集成一个数组,因为有合并和压缩,很显然,这种数据结构能节省不少空间,实际占用的空间随着元素的个数成正比
BitMapContainer
Map<short,bitMap>
解释下这个数据结构,key一样的含义,就不说了,因为低16位的值的范围是[0,65535]不重复的,可以通过一个bit数组来表示,这个bit数组的长度是65535,当一个元素经过计算命中了,就将对应下标的bit数组的值改成1
可以看到通过这种方式,占用的空间是固定的,65536/8/1024等于8k
从网上扒来一张图,能很好的说明这两个容器的差异点
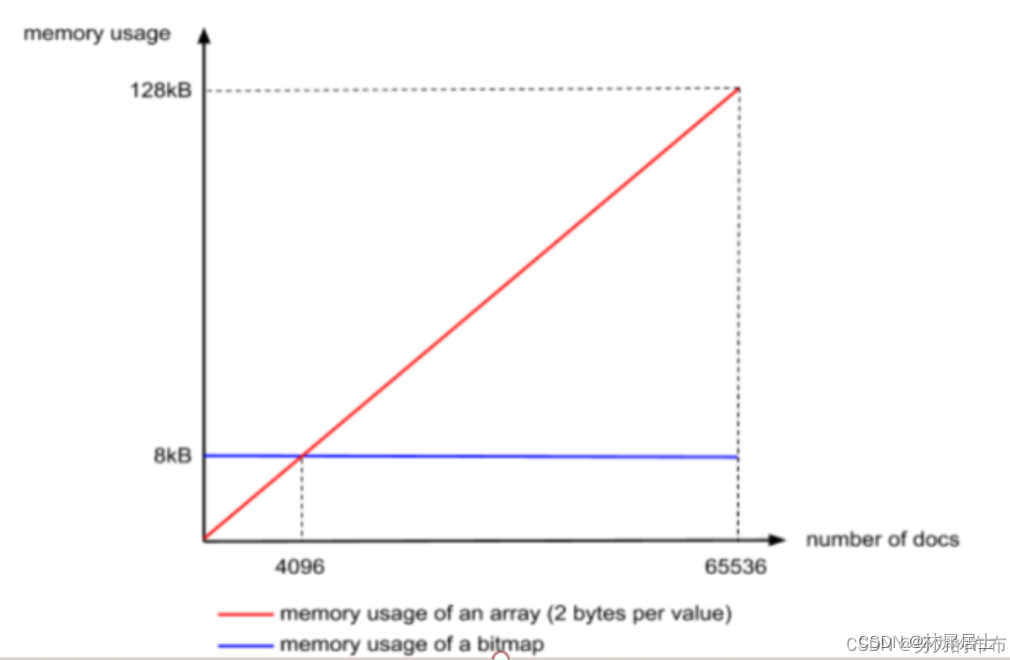
以上两个容器,当元素的个数在4096个的时候,达到了平衡,当大于4096个,使用bitMap这个数据结构更加合理,在元素的个数小于4096个时候,使用array这个数据结构更加合理。
这个算法使用的场景是,数组中的元素比较大,同时两个元素之间的间隔很大
词项索引 term index
词项索引的设计是为了更快的找到对应的词项字典