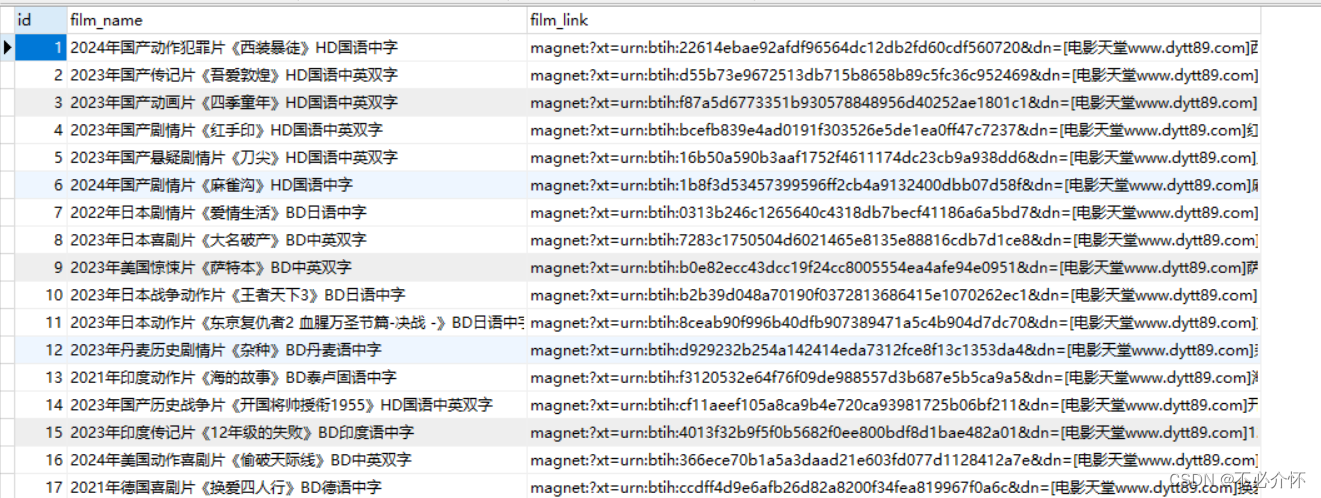
Pymysql将爬取到的信息存储到数据库中
爬取平台为电影天堂
获取到的数据仅为测试学习而用
爬取内容为电影名和电影的下载地址
创建表时需要建立三个字段即可
import urllib.request
import re
import pymysqldef film_exists(film_name, film_link):"""判断插入的数据是否已经存在"""sql = "select id from movie_link where film_name=%s and film_link=%s limit 1"result_num = my_cur.execute(sql, [film_name, film_link])# 使用sql语句查询获取到的电影名和下载地址,如果查询到有一条数据就表示数据已经存在,返回Trueif result_num:return Trueelse:return Falsedef create_date_table():"""创建数据库和数据表"""# 查看数据库是否存在,存在不创建,继续创建数据表。不存在创建,并创建表。exits = my_cur.execute("SHOW DATABASES LIKE 'movie_db';")if not exits:my_cur.execute("create database movie_db charset=utf8;")print("数据库建立成功")my_cur.execute("use movie_db;")my_cur.execute("""create table if not exists movie_link(id int(11) primary key auto_increment,film_name varchar(255) not null,film_link varchar(255) not null)charset=utf8;""")print("数据表建立成功")else:print("数据库已经存在,继续创建数据表")my_cur.execute("use movie_db;")my_cur.execute("""create table if not exists movie_link(id int(11) primary key auto_increment,film_name varchar(255) not null,film_link varchar(255) not null)charset=utf8;""")print("数据表建立成功")def add_films(film_name, film_link):"""向数据表中插入数据"""sql = "insert into movie_link values (null,%s,%s);"result_insert = my_cur.execute(sql, [film_name, film_link])# 如果插入成功返回值应该为影响的行数,不为零就代表插入成功if result_insert:print("插入成功:", film_name)def down_view():# 打开网页respon_data = urllib.request.urlopen("https://dy2018.com/0/")# 解码respon_decode = respon_data.read().decode("gbk")# 正则表达式获取下载页面网址films_data = re.findall(r"<a href=\"(.*)\" class=\"ulink\" title=\"(.*)\">", respon_decode)# 创建字典存储当前页的电影名和下载页面网址films_dict = {}count = 1# 将电影名和下载页网址从列表中拆包for films_url, films_name in films_data:# 拼接下载页面网站films_url = "https://www.dy2018.com/" + films_url# 打开下载页面respon_films_data = urllib.request.urlopen(films_url)# 解码respon_deown = respon_films_data.read().decode("gbk")# 使用正则提取下载地址down_url = re.search(r">(magnet:.*\.mp4)</a>", respon_deown)# 将电影名和下载地址存入字典films_dict[films_name] = down_url.group(1)print("已爬取第%s个资源" % count)count += 1return films_dictdef main():# 爬取信息并用字典介接收down_dict = down_view()# 创建数据库和数据表create_date_table()my_cur.execute("use movie_db;")# 将字典中的数据遍历取出,进行判断、添加for film_name, film_link in down_dict.items():if film_exists(film_name, film_link):print("电影[%s]保存失败" % film_name)continueadd_films(film_name, film_link)if __name__ == '__main__':# 建立连接my_sql = pymysql.connect(host="localhost", user="root", password="123456")# 创建游标对象my_cur = my_sql.cursor()main()# 一定要提交,否则数据不会被保存my_sql.commit()my_cur.close()my_sql.close()
将数据库中的数据当作固定页面返回
import socket
import pymysqldef request_headler(new_client_socket, ip_port):request_data = new_client_socket.recv(1024).decode()# 接收客户端浏览器发送的请求# 判断协议是否为空if not request_data:print("%s用户已下线" % str(ip_port))new_client_socket.close()return# 拼接响应的报文# 响应行respon_line = "HTTP/1.1 200 OK\r\n"# 响应头respon_header = "Server:Python\r\n"respon_header += "Content-Type:text/html; charset=utf-8\r\n"# 响应空行respon_blank = "\r\n"# 响应主体respon_body=""result = my_cur.execute("select * from movie_link;")result_data = my_cur.fetchall()for data in result_data:respon_body += ("%s、%s <a href=%s>%s</a><br>" % (data[0], data[1], data[2],data[2]))# 发送响应报文respon_data = (respon_line + respon_header + respon_blank + respon_body).encode()new_client_socket.send(respon_data)def main():# 创建套接字tcp_sderver_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 设置端口重用、tcp_sderver_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 绑定端口tcp_sderver_socket.bind(("", 8080))# 设置监听,让套接字由主动变为被动接收tcp_sderver_socket.listen(128)# 接受客户端的请求 定义函数request_handler()while True:new_client_socket, ip_port = tcp_sderver_socket.accept()print("新用户%s来了" % str(ip_port))request_headler(new_client_socket, ip_port)# 关闭操作if __name__ == "__main__":my_db = pymysql.connect(host="localhost", user="root", password="123456", database="movie_db")my_cur = my_db.cursor()main()my_cur.close()my_db.close()