Redis系列-数据结构篇
数据结构
string(字符串)
redis的字符串是动态字符串,类似于ArrayList,采用预分配冗余空间的方式减少内存的频繁分配。
struct SDS<T>{
T capacity;
T len;
byte flags;
byte[] content;
}当字符串比较短时,T可以是byte和short来表示(能省点空间),一个简单的SDS至少占用3字节
struct SDS<T>{
int8 capacity;
int8 len;
int8 flags;
byte[] content;
}embstr和raw
当字符串比较短时,存储形式embstr;当字符串比较长时,存储形式raw。
暂时无法在文档外展示此内容
struct RedisObject {
int4 type; //4bits
int4 encoding; //4bits
int24 lru; //24bits,对象的热度
int32 refcount; //32bits,记录对象的引用计数,当lru为0时,对象会被销毁
void *ptr; //64bits
}每个对象除了内容以外,RedisObject本身也占用1/2+1/2+3+4+8 = 16字节
如图所示,embstr存储时会把数据结构redisObject和数据SDS挨边存储;raw存储时数据结构RedisObject和SDS时分开存储,通过ptr指针指向SDS的内存地址。
所以一个简单的字符串最少占用3字节+16字节= 19字节
而redis使用的内存分配器jemalloc,tcmalloc分配内存时的单位都是1/4/8/16/32/64,所以假设内存分配给分配了64字节的空间,那么最多给字符串内容的空间只有44字节 = 64 - 3 - 16 - 1(最后一个1是因为字符串需要以null结尾,占一个子节)
扩容
预分配空间大小:capacity
实际字符串长度:len
创建字符串时,len和capacity是一样的长度
当字符串长度小于1M时,扩容都是加倍现有的空间,即
if(len<1024*1024 && len+appendLen>=capacity){capacity = 2*capacity;
}
当字符串长度大于1M时,每次扩容比当前多1M空间
if(len>1024*1024 && len+appendLen>=capacity){capacity = capacity + 1024*1024;
}
常用操作
set,get,mset,mget,expire,setnx,incr
mset name1 aa name2 bb name3 cc
mget name1 name2 name3
expire name1 5. #5秒后过期
incr age 1
incr age by 5。 #signed long的最大最小值之间
位图
位图来自于字符串的另一种表示,我们知道字符串实际是存储byte数组,redis以此可以单独设置某key第n位为0还是1。通过位图,我们可以节省更多的内存,当然需要配合适当的场景使用
常用操作
零存整取
setbit key index 0/1
get key
整存整取(即字符串)
set key value
get key
整存零取
set key value
getbit key index
零存零取
setbit key value
getbit key index
bitcount:用来统计指定范围内1的个数
bitcount key 0 1 前两个字符(0~1)中1的个数
bitpos:用来查找指定范围内出现的第一个0或1
bitpos key 1 第一个1位
bitpos key 0 第一个0位
bitpos key 1 start end 在start~end范围的字节内,第一个0位
list(列表)
相当于java里面的LinkedList,可以在头部(Left)和尾部(Right)插入/删除
两元素之间使用双向链表连接,可以支持向前向后遍历
encoding:ziplist,quicklist
满足
create if not exists
drop if no elements
常用操作
rpush books python java golang
llen books
lpop books
rpop books
lpush books newBook
lindex books 1 #获取books列表中第2位元素
ltrim books 0 1 #区间内的元素保留,特别的如果后面元素=-1,表示结尾。同理-2表示倒数第二个
lrange books 0 1 #相当于sublist,特别的如果后面元素=-1,表示结尾。同理-2表示倒数第二个
与java中linkedList不同有2
如果redis list中元素比较少时,使用ziplist存储,
如果redis list中元素比较多时,使用ziplist+linkedList存储,即每个“元素”实际上是一个ziplist
问题:为什么redis list中的“元素”是ziplist,不是简单的元素
redis是基于内存的操作,所以对内存的使用要求很苛刻。尽其所能对使用的内存进行优化。如果redis list中元素存储的是简单的元素,那么仅仅元素间的两个指针就占了不少空间,特别是当元素本身占用空间很少时。
为什么元素是ziplist呢?
首先ziplist本身是一个聚集型的列表,通过连续存储以及快速定位,能够提高在ziplist内遍历的效率。同时ziplist内部可以选择压缩深度,也能极大的减少使用的空间
压缩链表
struct ziplist{int32 zlbytes; //整个压缩链表占用字节数int32 zltail_offset; //最后一个元素距离压缩列表起始位置的偏移量int16 zllength; //元素个数T[] entries; //元素集合int8 zlend; //压缩链表结束节点,OxFF}struct entry{int prevlen; //前一个entry的字节长度int encoding; //元素类型编码optional byte[] content; //元素内容}往ziplist里面追加元素
因为ziplist是紧凑型的数据结构,意味着每追加一个元素都需要调用realloc扩展内存,取决于内存分配算法和ziplist当前的内存大小,可能会重新扩展全新的内存,并把原有的拷贝过来,也可能在原来的位置直接扩展
快速链表
无法复制加载中的内容
每个ziplist存储超过8KB就会新起一个ziplist
redis可以选择对quicklist中的每个ziplist进行压缩,以压缩深度表示。默认是压缩深度为0。如果压缩深度等于1,那么收尾两个ziplist不压缩,其他的都压缩。如果压缩深度等于2,那么链表头两个和链表尾两个都不压缩,其他都压缩。
hash(字典)
满足
create if not exists
drop if no elements
与java中的HashMap很相近。都是数组加链表的形式。
encoding:ziplist,hashtable
不同有三:
redis的hash的value只能是字符串,所以需要在业务系统中将其做序列化和反序列化。
redis hash的rehash与HashMap的rehash也不一样。HashMap是一次性将元素进行rehash,如果元素比较多,可能会有卡顿的情况。redis hash中的rehash是渐进式的,发起rehash之后,会通过定时任务或者hash操作指令,渐进式的将旧的hash表的内容拷贝到新hash表中。
redis hash可以对对象的具体属性进行操作,比如
hset books borrowTime 111111
hincr books borrowTime 5
常用操作
hset,hget,hgetall,hmset,hincr,hincrby
set(集合)
满足
create if not exists
drop if no elements
相当于Java里面的HashSet,所有key对应的value都只用一个NULL。且内部的键值是无序的,唯一的
若set中存在某元素,则再次set时,返回0,可以以此判断是否存在元素
encoding:inset,dict(rehash时,通过COW的思维来做)
typedef struct intset {uint32_t encoding; // 编码方式,后面会详细解释uint32_t length; // 集合中元素的个数,也就是contents数组的长度int8_t contents[]; // 保存元素的数组
} intset;


常用操作
sadd,spop,smembers,sismember,scard(count)
如果set中的元素都是整数并且数据量比较小时,redis会选择使用inset进行数据的存储
struct inset{int32 encoding;int32 length;int content;}encoding会有int16,int32,int64三种类型。可以向上扩,不能向下缩。(存储的内容都是整数,并不会占用很大空间,但如果向下缩,就需要额外的内存分配以及原有的内存回收,得不偿失)
zset(有序列表)
满足
create if not exists
drop if no elements
类似于java中SortedSet和HashMap的集合体,一方面可以保证唯一性,另一方面可以为每一个元素添加score,并以此作为排序依据
内部实现是一种叫做“跳跃列表”的数据结构
encoding:ziplist,skiplist
常用操作
zadd books 9.0 “think in java”zrange books 0 -1 相当于sublist,并且按照score正序列出zrevrange books 0 -1 相当于sublist,并且按照score倒序列出zcard books 相当于countzscore books “think in java” 获取指定value的scorezrank books “think in java” 按score排序后,当前value的排名zrangebyscore books 0 8.91 在区间之内的所有valuezrangebyscore books -inf 8.91 withscore 在区间之内所有的value+scorezrem books “think in java” 删除value(可以通过这个命令来确保只有一个线程抢到队列(zset)中的)跳跃列表
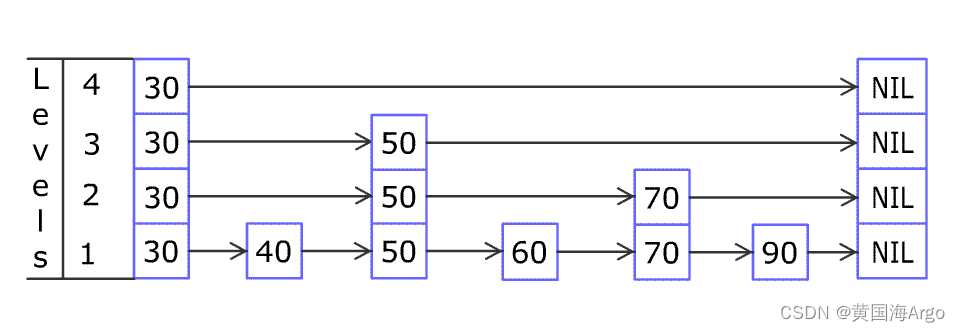
其中每根柱子代表一个元素,每个元素可能有多个层级,最左边是表头,它的高度是当前列表最高高度。当要寻找某一个值的时候,从表头最高层开始按照箭头找,只到最底层的节点。表头的score是Double.MIN_VALUE用来垫底
插入元素时,需要按照查找的逻辑找到最底部的节点,然后插入节点,接着会采用随机策略决定新节点有多少层。第一层的概率是100%,第二层的概率是50%,第三层的概率是25%,以此类推,最高可以有64层