在windows环境下安装hadoop
Hadoop是一个分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。但这个架构是基于java语言开发的,所以要先进行jdk的安装,如果电脑已经配置过jdk或者是曾经运行成功过java文件,那就可以跳过第一步。
一.JDK安装
## Hadoop支持的 Java 版本- Apache Hadoop 3.3 及更高版本支持 Java 8 和 Java 11(仅限运行时)- 请使用 Java 8 编译 Hadoop。不支持使用 Java 11 编译 Hadoop: [HADOOP-16795](https://issues.apache.org/jira/browse/HADOOP-16795)-Java 11 编译支持**OPEN** [](https://issues.apache.org/jira/browse/HADOOP-16795) - 从 3.0.x 到 3.2.x 的 Apache Hadoop 现在仅支持 Java 8 - 从 2.7.x 到 2.10.x 的 Apache Hadoop 支持 Java 7 和 8
所以我们安装jdk8来运行Hadoop,最好去官网进行下载:https://www.oracle.com/java/technologies/downloads/#jre8-windows
自己看自己电脑的配置选择
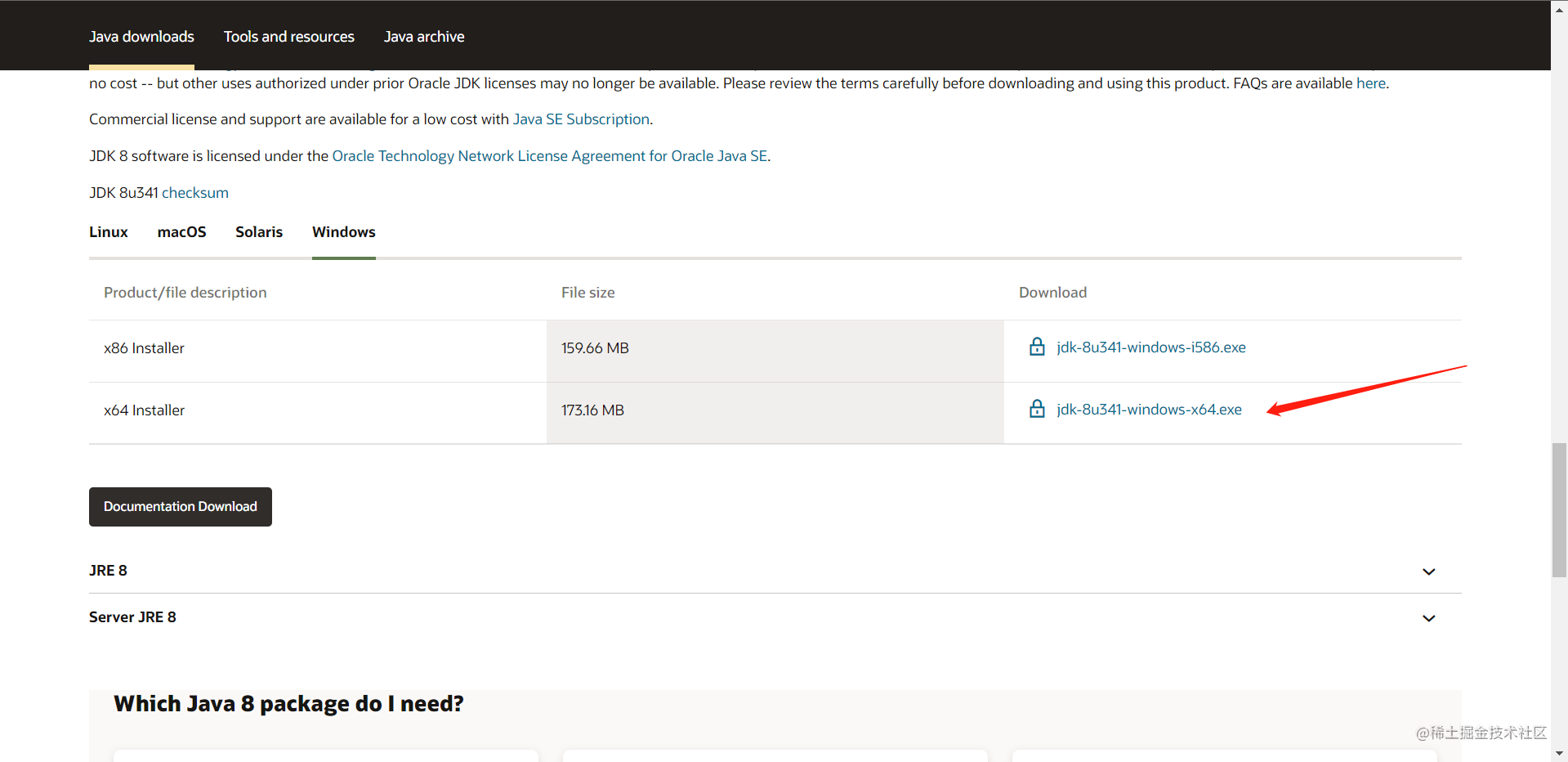
我是64位就下载这个,32位的下载上面一个。运行安装程序即可,不需要配置环境变量。
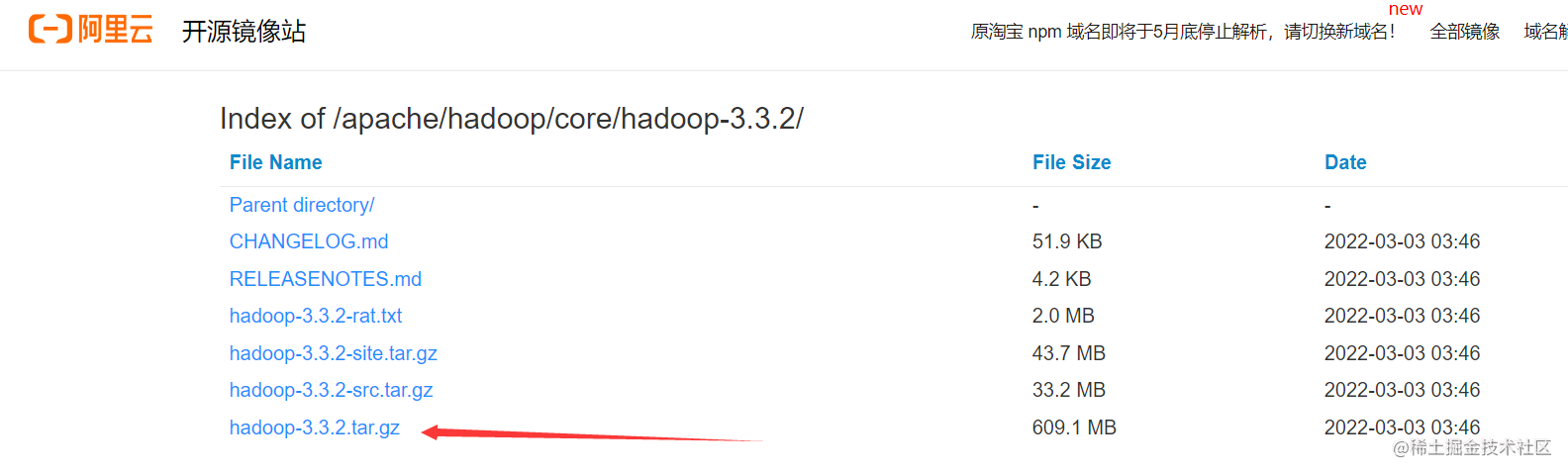
二.Hadoop安装
可以去阿里云开源镜像站下载快点
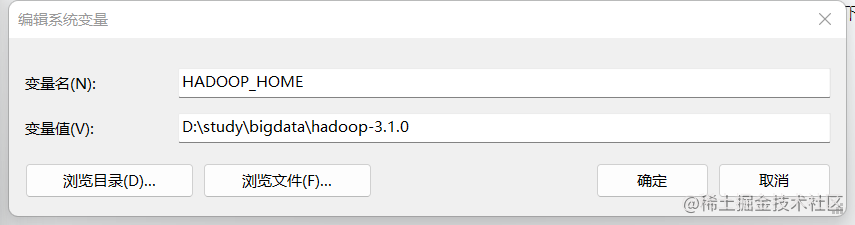
windows的环境变量配置
设置->系统->系统信息->高级系统设置(也可以用win11的搜索编辑系统环境变量)
在下面的系统变量处新建:
HADOOP_HOME
值为(你解压缩hadoop所在路径)
D:\study\bigdata\hadoop-3.1.0
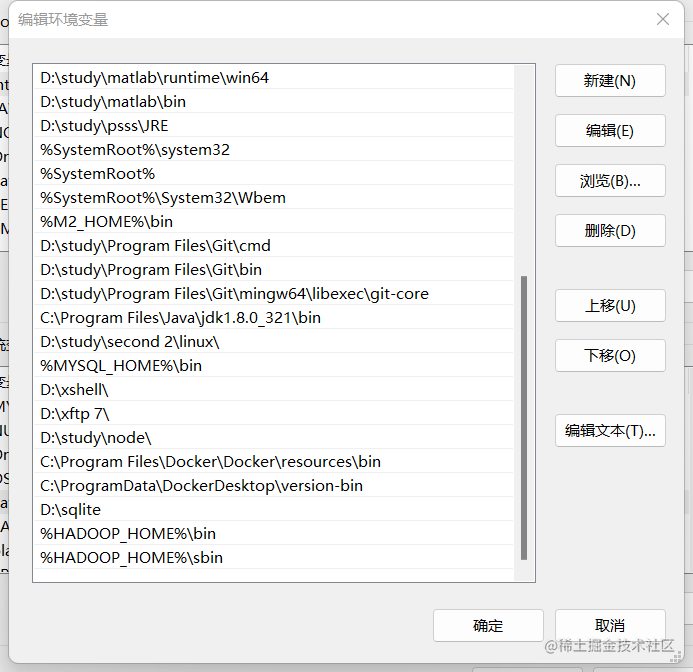
然后在系统变量的Path下新建两个变量
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
hadoop文件配置
在D:\study\bigdata\hadoop-3.1.0 (即你放hadoop的路径下)
去\etc\hadoop目录找到hadoop-env.cmd这个文件,右键编辑,然后搜索(或者Ctrl+F)搜索JAVA_HOME找到set JAVA_HOME这一项,将其修改为jdk8的安装路径:
set JAVA_HOME=C:\PROGRA~1\Java\jdk-8
为什么要使用PROGRA~1来代替Program Files,因为这是其dos文件名模式下的缩写,直接使用Program Files会报错,里面包含一个空格
然后去cmd查看是否安装成功,没有报错说明配置已经成功了。
hadoop -version
从这里开始出现bug的话,发现没有安装成功,没有出现配置信息的话,那就继续往下看。如果成功跳到三.启动测试
1.先进入D:\study\bigdata\hadoop-3.1.0\etc这个目录(对应的是你放hadoop的目录)
2.修改core-site.xml这个文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:900</value>
</property>
</configuration>
2.修改mapred-site.xml文件
<!-- 2. Edit mapred-site.xml and copy this property in the cofiguration -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
4.修改hdfs-site.xml文件
<!-- Put site-specific property overrides in this file. -->
<!-- 3. Create a new folder named "data2020" in ../hadoop-3.1.0/ in the same
directory of etc folder -->
<!-- 4. Edit the file hdfs-site.xml and add below property in the configuration -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>D:\study\bigdata\hadoop-3.1.0\data2022\namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>D:\study\bigdata\hadoop-3.1.0\data2022\datanode</value>
</property>
</configuration>5.创建一个data目录在D:\study\bigdata\hadoop-3.1.0,我取名叫data2022
6.在5的data2022目录下创建4你的两个文件夹名字:namenode和datanode
7.依然在D:\study\bigdata\hadoop-3.1.0\etc这个目录下找到hadoop-env.sh这个文件,找到这里修改配置:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_321
export JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_321
8.找到hadoop-env.cmd文件,修改(7和8都是修改成自己的jdk路径)
@rem The java implementation to use. Required. set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_321
9.然后去这个网站下载如果要在windows下运行hadoop专门的bin文件夹,点赞私聊我也会私发给你这份文件夹。
三.启动测试
1.进入命令行窗口,格式化hadoop
hadoop namenode -format
2.然后去到D:\study\bigdata\hadoop-3.1.0\bin这个目录下,在地址栏输入cmd,再使用以下命令
start-dfs.cmd
这时候会跳出两个窗口不要关掉它们,然后继续下一步
3.继续输入以下命令:
start-yarn.cmd
又跳出两个窗口,也不要关掉,要不然会有错误出现
4.然后打开这个链接:http://localhost:9870/
5.以后你都要同时重复23就可以使用hadoop了
6.之后你就可以在刚刚的命令行窗口通过输入命令使用hadoop了
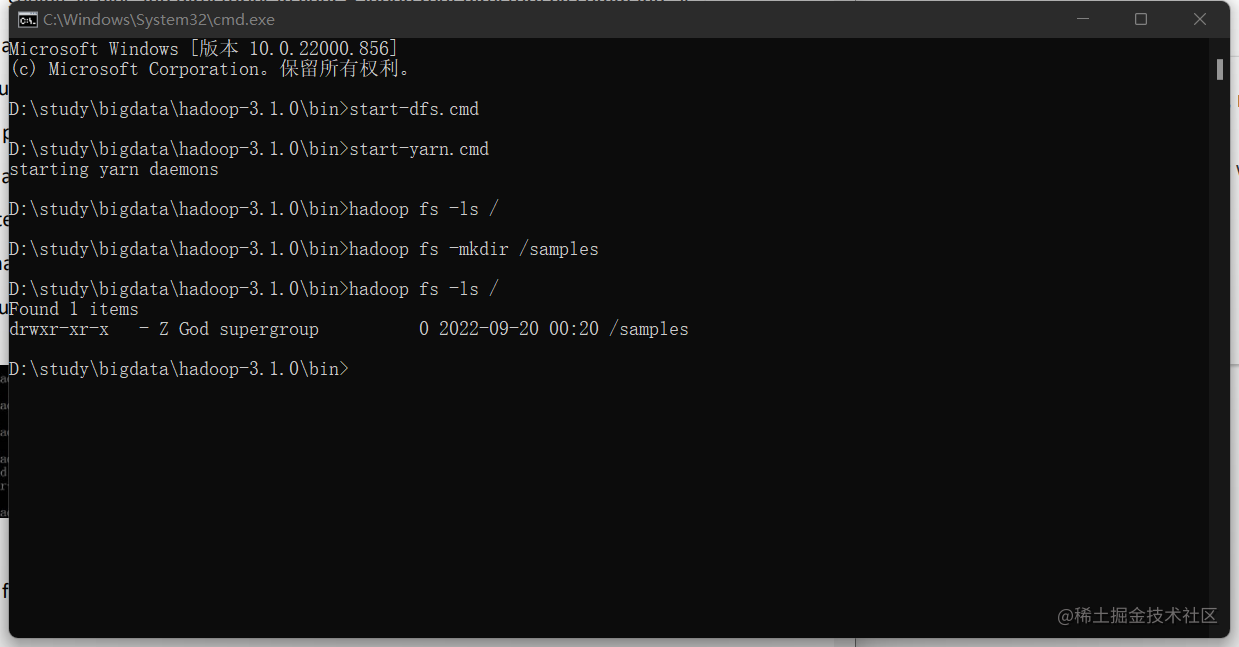
以上便是全流程。