TensorFlow2实战-系列教程5:猫狗识别任务数据增强实例
🧡💛💚TensorFlow2实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Jupyter Notebook中进行
本篇文章配套的代码资源已经上传
1、猫狗识别任务
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = './data/cats_and_dogs'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(64, 64, 3)),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(64, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(128, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')
])model.compile(loss='binary_crossentropy',optimizer=Adam(lr=1e-4),metrics=['acc'])
依次是导包、指定数据路径、构建模型、配置训练器等,这些都与前面TensorFlow2实战-系列教程3:猫狗识别1完全一致
2、数据增强
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir, target_size=(64, 64), batch_size=20,class_mode='binary')validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(64, 64),batch_size=20,class_mode='binary')history = model.fit_generator(train_generator,steps_per_epoch=100, # 2000 images = batch_size * stepsepochs=100,validation_data=validation_generator,validation_steps=50, # 1000 images = batch_size * stepsverbose=2)
train_datagen:
- 这里将rescale重新缩放、旋转、平移变换、剪切变换、缩放、水平翻转、以临近方式填充等多种方式对训练数据进行数据增强
- shear_range=0.2 表示图像将在 -0.2 到 +0.2 弧度的范围内随机剪切
test_datagen:
- 验证数据,没有进行数据增强,这里只进行了归一化操作
train_generator:
- 从
train_dir目录加载训练图像,并应用前面定义的数据增强 target_size=(64, 64):调整图像大小为 64x64 像素batch_size=20:每批次处理 20 张图像class_mode='binary':因为是二分类任务。
validation_generator:
- 从
validation_dir目录加载验证图像,只应用缩放
history:
- (
fit_generator方法在 TensorFlow 2.2 之后已经被弃用,建议使用fit方法替代) - 开始训练
validation_data=validation_generator:指定验证数据生成器verbose=2:用于控制训练过程中输出的详细程度
3、预测效果展示
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'b', label='Training Loss')
plt.plot(epochs, val_loss, 'r', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()plt.show()

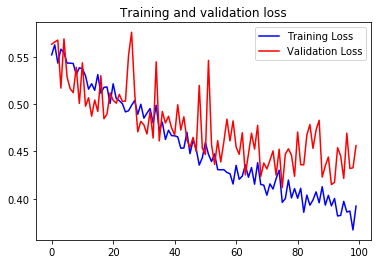
很显然经过数据增强后的模型表现对比原本效果有显著提升
3、加入Dropout
Dropout就是指定比例,对这一层随机杀死一下神经元,这里我们只需要在构建网络的时候在全连接层加上一层Dropout就可以了:
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = './data/cats_and_dogs'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(64, 64, 3)),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(64, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Conv2D(128, (3,3), activation='relu'),tf.keras.layers.MaxPooling2D(2,2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dropout(0.5),tf.keras.layers.Dense(1, activation='sigmoid')
])model.compile(loss='binary_crossentropy',optimizer=Adam(lr=1e-4),metrics=['acc'])
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir, target_size=(64, 64), batch_size=20,class_mode='binary')validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(64, 64),batch_size=20,class_mode='binary')history = model.fit_generator(train_generator,steps_per_epoch=100, # 2000 images = batch_size * stepsepochs=100,validation_data=validation_generator,validation_steps=50, # 1000 images = batch_size * stepsverbose=2)
Epoch 100/100
100/100 - 3s - loss: 0.4145 - acc: 0.8145 - val_loss: 0.4269 - val_acc: 0.7830 - 3s/epoch - 33ms/step
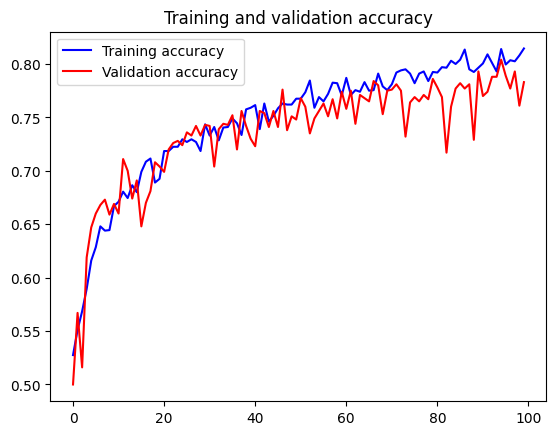
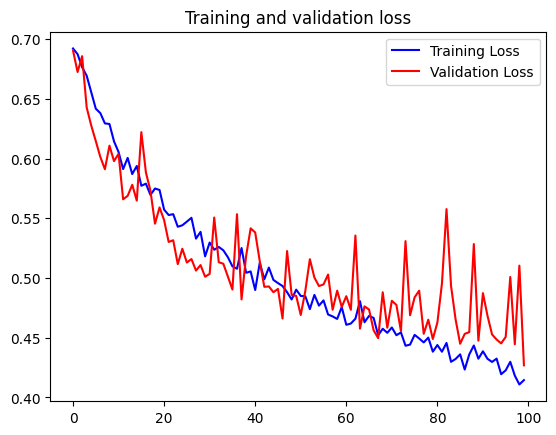
这效果又提升了一点