主成分分析(PCA)Python
实际问题研究中,常常遇到多变量问题,变量越多,问题往往越复杂,且各个变量之间往往有联系。于是,我们想到能不能用较少的新变量代替原本较多的旧变量,且使这些较少的新变量尽可能多地保留原来变量所反映的信息。
比如说一件上衣,有身长、袖长、胸围、腰围等等十多个指标,将型号分这么多很麻烦,因此,厂家将十多项指标综合成3项指标,分别反映长度、胖瘦、特殊体型。
变量具有相关性,同时就意味着反映的信息有重叠性,主成分分析就是将重复的变量(关系紧密的变量)删去,建立尽可能少的、互相无关的新变量。
设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析法,也是数学上用来降维的一种方法。
通过PCA将n维原始特征映射到k维上(k<n),称这k维为主成分。
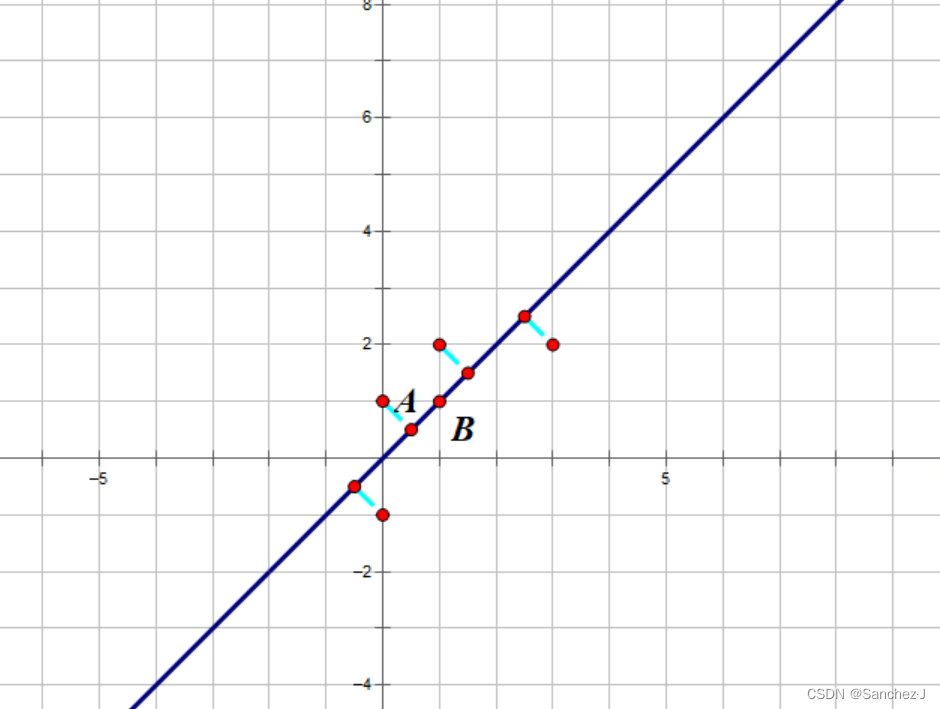
找新的维度实质上要使数据间的方差够大,即在新维度下坐标点足够分散、数据间有区分。本质上也就是在做基变换。
下图是一个例子,将5个点降维到一条直线上。
代数上,可以理解为m × n的原始样本X,与n×k阶的矩阵W做矩阵乘法,得到m×k阶低维矩阵Y。
分析思想
假设有n个样板,p个指标,则可以构成大小为n×p的样本矩阵X:
假设我们想找到新的一组变量,其满足
系数确定原则:
与
(
) 线性无关
是
线性组合中方差第k大者,称原变量指标的第k主成分
PCA计算步骤
- 标准化处理
- 计算标准化样本的协方差矩阵
- 计算R的特征值和特征向量(特征值从大到小排序)
- 计算主成分贡献率以及累计贡献率
- 贡献率
- 累计贡献率
- 写出主成分:一般取累计贡献率超过80%的特征值所对应的第1,2,...,m个主成分。其中第 i 个是
(
是第i个特征向量)
- 根据系数分析主成分代表的意义
Python代码
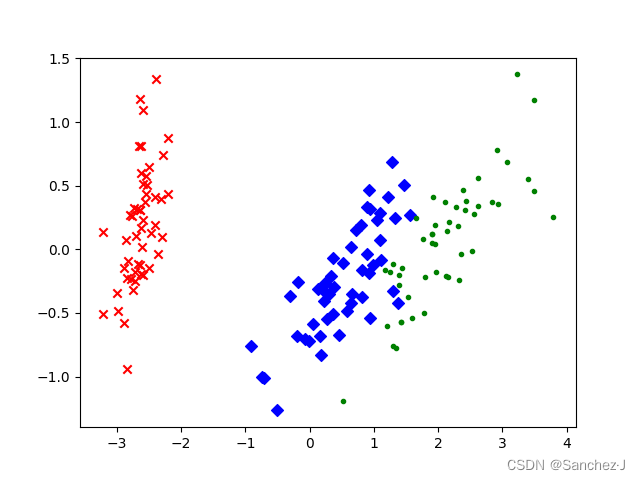
这段代码将Iris数据集降维到二维空间,并使用散点图展示不同类别的鸢尾花在降维后的空间中的分布情况。详见注释。
import matplotlib.pyplot as plt # 加载matplotlib用于数据的可视化
from sklearn.decomposition import PCA # 加载PCA算法包
from sklearn.datasets import load_iris # 从sklearn库中导入load_iris函数,用于加载Iris数据集。data = load_iris() # 使用load_iris函数加载Iris数据集。
y = data.target # 提取数据集的标签(目标变量),表示不同种类的鸢尾花。
x = data.data # 提取数据集的特征,表示鸢尾花的四个特征。
pca = PCA(n_components=2) # 加载PCA算法,设置降维后主成分数目为2
reduced_x = pca.fit_transform(x) # 对原始数据进行PCA降维,将数据转换为新的二维空间。
red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], []
# 初始化三个颜色类别(红色、蓝色、绿色)的坐标列表。
for i in range(len(reduced_x)): # 遍历降维后的数据if y[i] == 0: # 如果数据点属于第一类鸢尾花。red_x.append(reduced_x[i][0])red_y.append(reduced_x[i][1])# 将该点在降维后的第一个主成分的坐标添加到红色类别的x坐标列表中。# 将该点在降维后的第二个主成分的坐标添加到红色类别的y坐标列表中。elif y[i] == 1:blue_x.append(reduced_x[i][0])blue_y.append(reduced_x[i][1])else:green_x.append(reduced_x[i][0])green_y.append(reduced_x[i][1])
# 可视化
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()结果