[学习笔记]刘知远团队大模型技术与交叉应用L3-Transformer_and_PLMs
RNN存在信息瓶颈的问题。
注意力机制的核心就是在decoder的每一步,都把encoder的所有向量提供给decoder模型。

具体的例子
先获得encoder隐向量的一个注意力分数。

注意力机制的各种变体
一:直接点积
二:中间乘以一个矩阵
三:Additive attention:使用一层前馈神经网络来获得注意力分数
…
Transformer概述

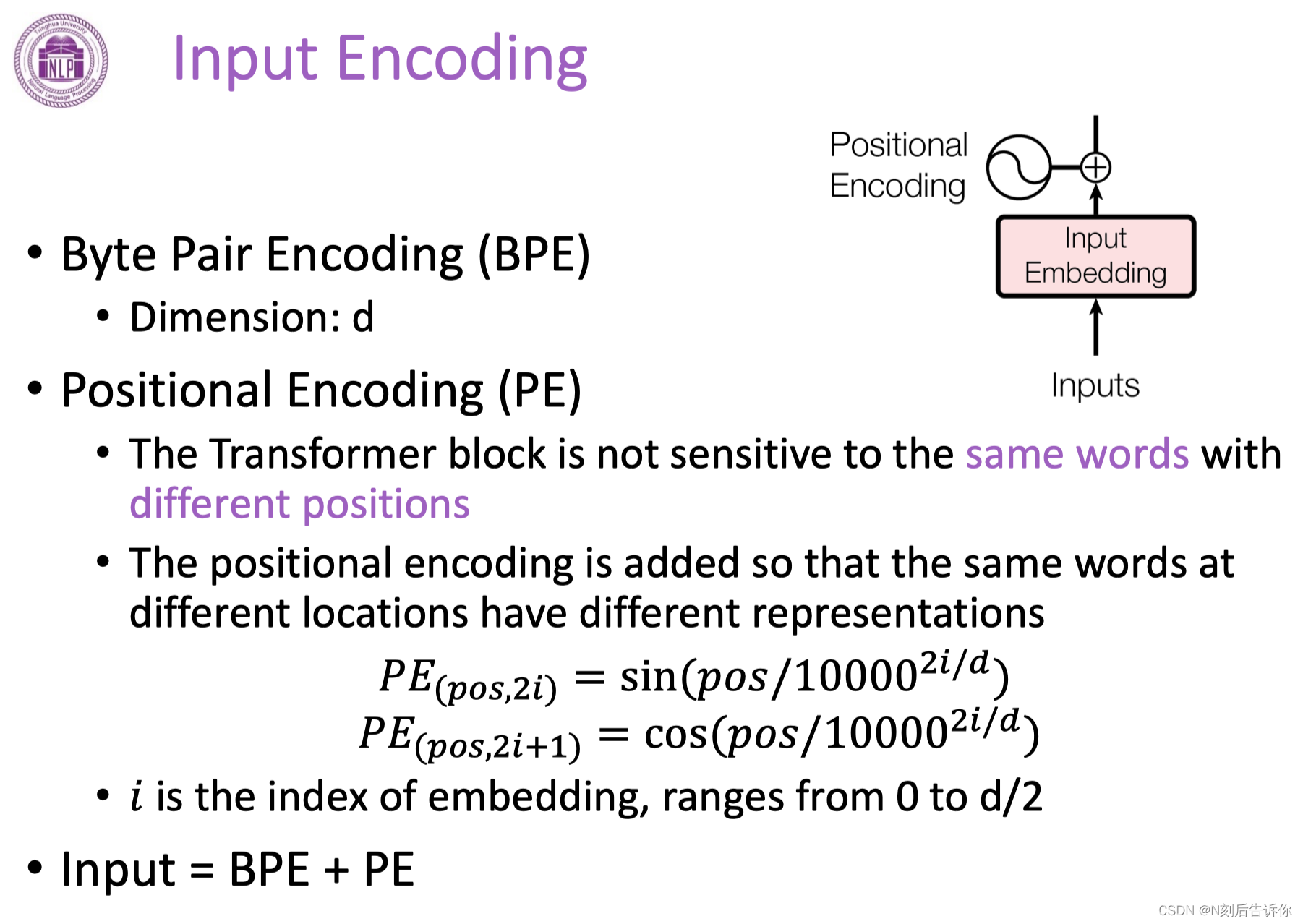
输入层
BPE(Byte Pair Encoding)

BPE提出主要是为了解决OOV的问题:会出现一些在词表中没有出现过的词。

位置编码Positional Encoding
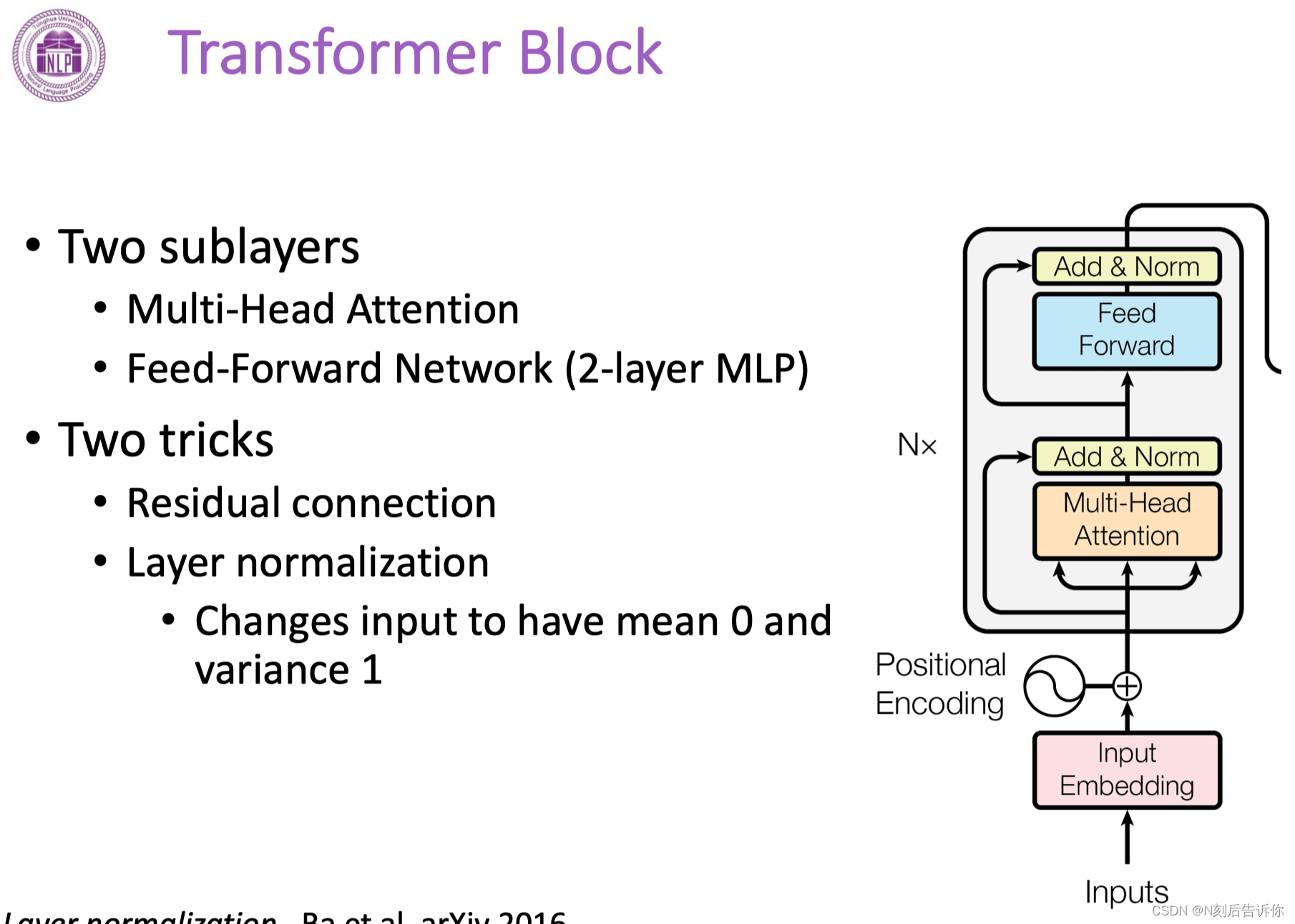
Transformer Block
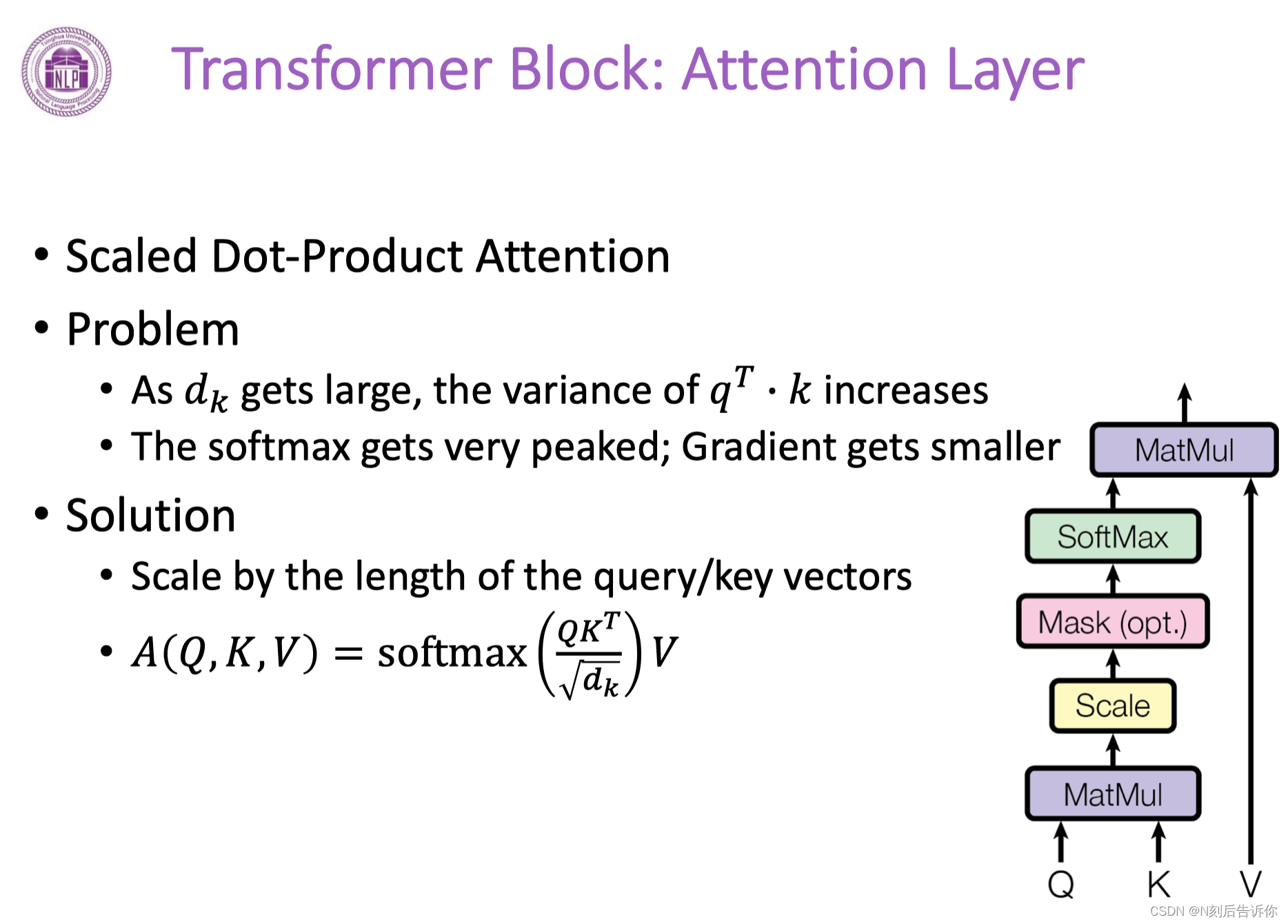
attention层

不进行scale,则方差会很大。则经过softmax后,有些部分会很尖锐,接近1。
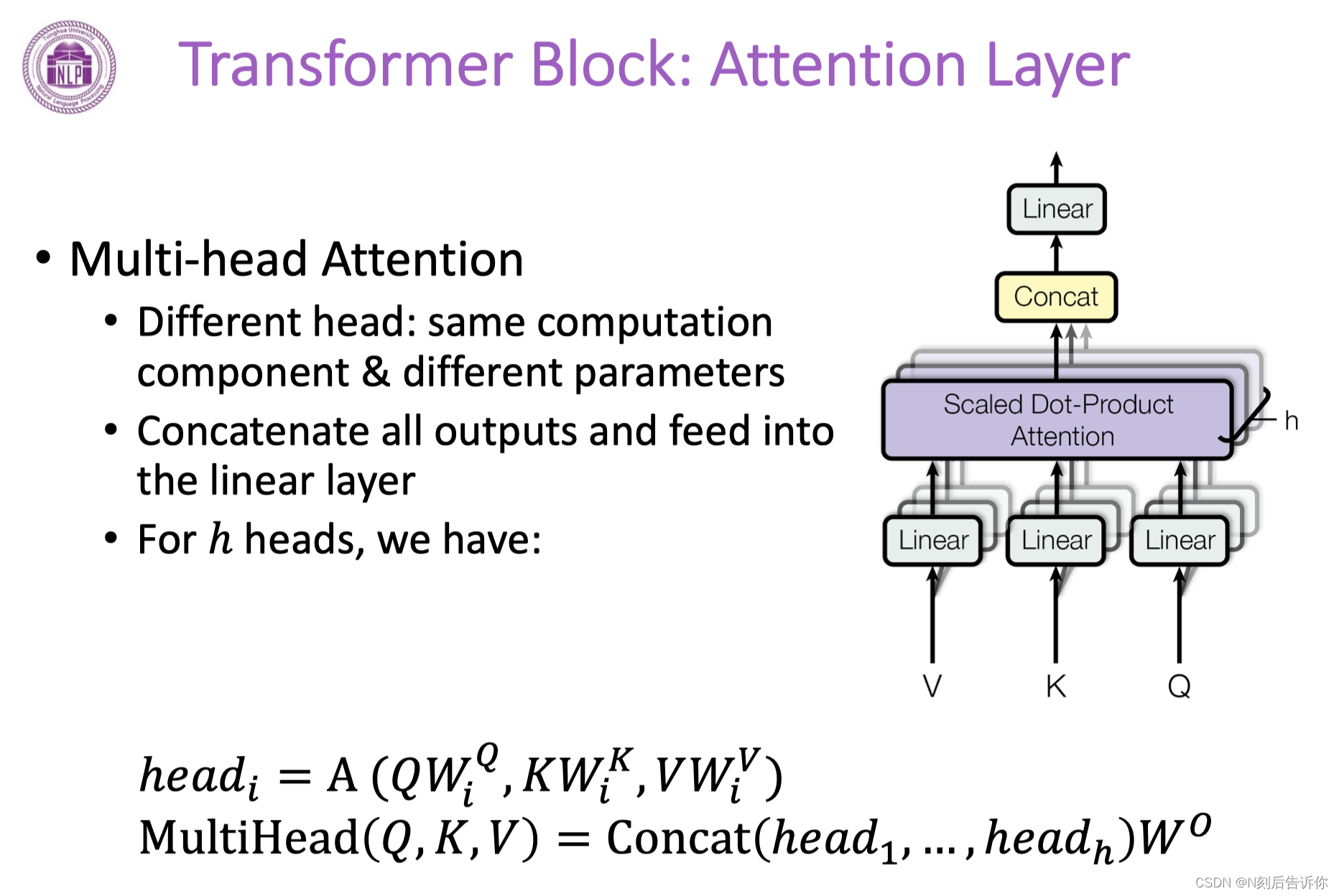
多头注意力机制
Transformer Decoder Block
mask保证了文本生成是顺序生成的。

其他Tricks

Transformer的优缺点
缺点:模型对参数敏感,优化困难;处理文本复杂度是文本长度的平方数量级。

预训练语言模型PLM
预训练语言模型学习到的知识可以非常容易地迁移到下游任务。
word2vec是第一个预训练语言模型。现在绝大多数语言模型都是基于Transformer了,如Bert。
PLMs的两种范式
1.feature提取器:预训练好模型后,feature固定。典型的如word2vec和Elmo
2.对整个模型的参数进行更新

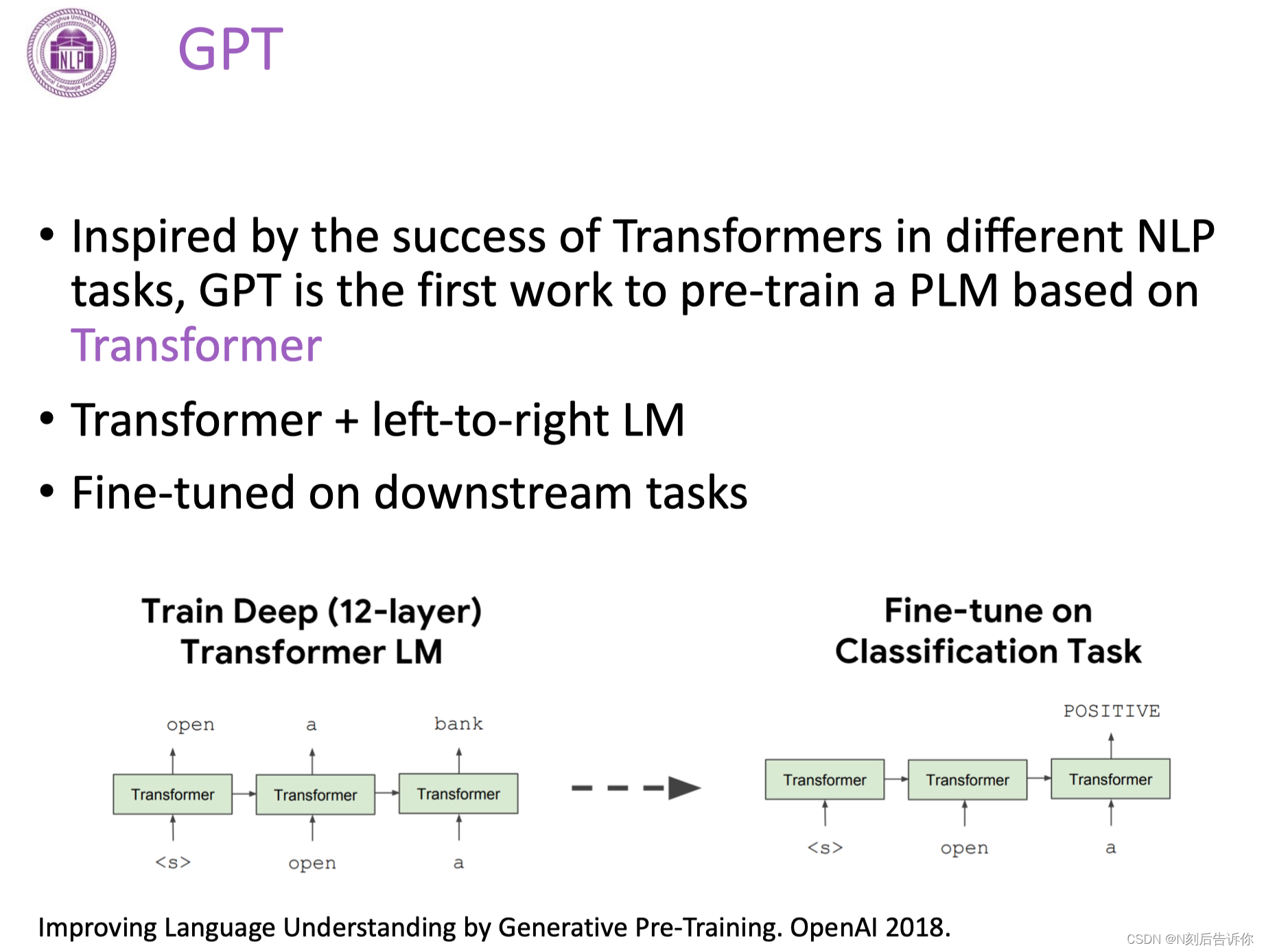
GPT
BERT
不同于GPT,BERT是双向的预训练模型。使用的是基于Mask的数据。
它的最主要的预训练任务是预测mask词。
还有一个是预测下一个句子。


PLMs after BERT
BERT的问题:
尽管BERT采用了一些策略,使mask可能替换成其他词或正确词。但是这并没有解决mask没有出现在下游任务。
预训练效率低。
窗口大小受限。

相关改进工作
RoBERTa指出bert并没有完全训练。它可以被训练得更加鲁棒。


MLM任务的应用
跨语言对齐

跨模态对齐

PLM前沿
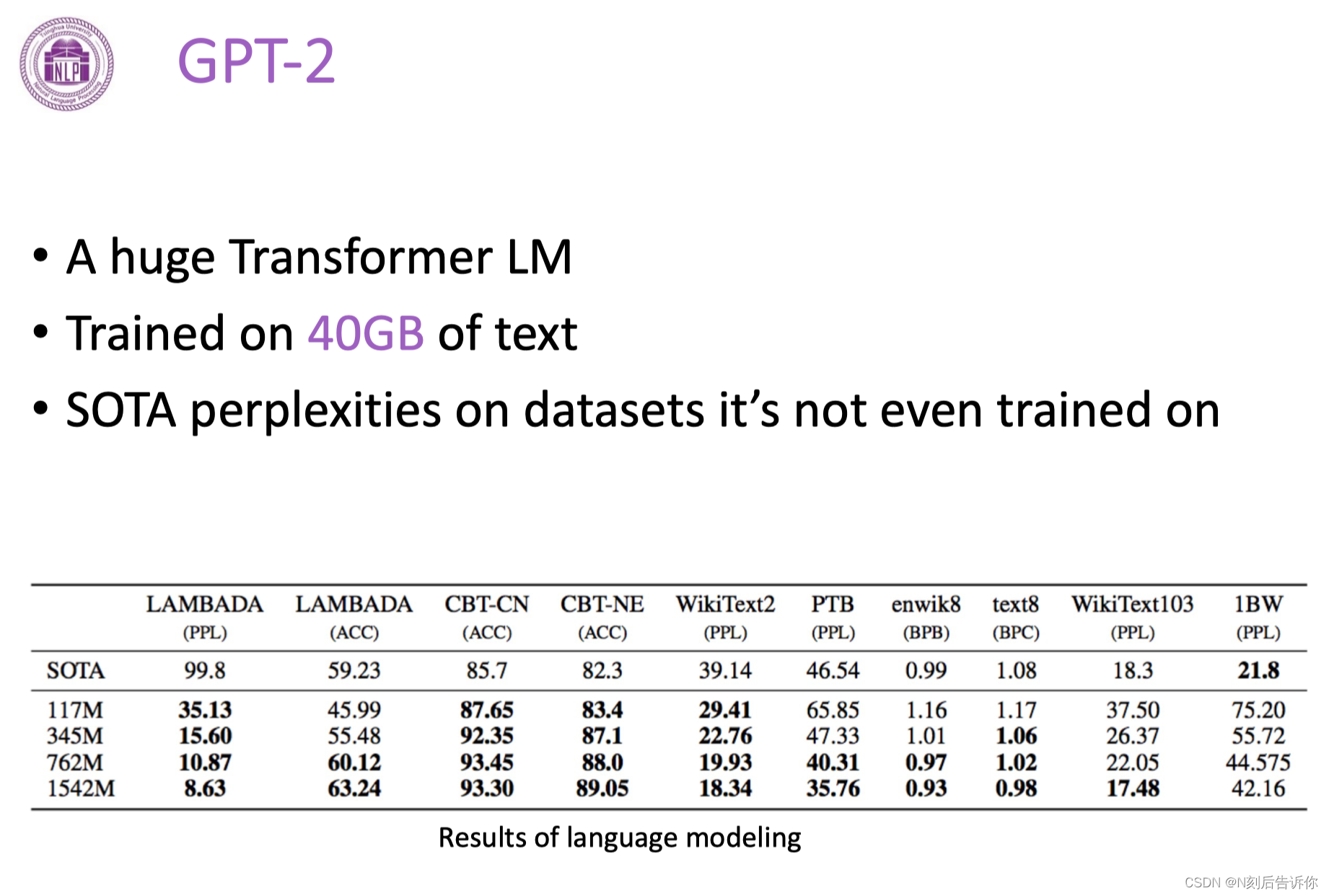
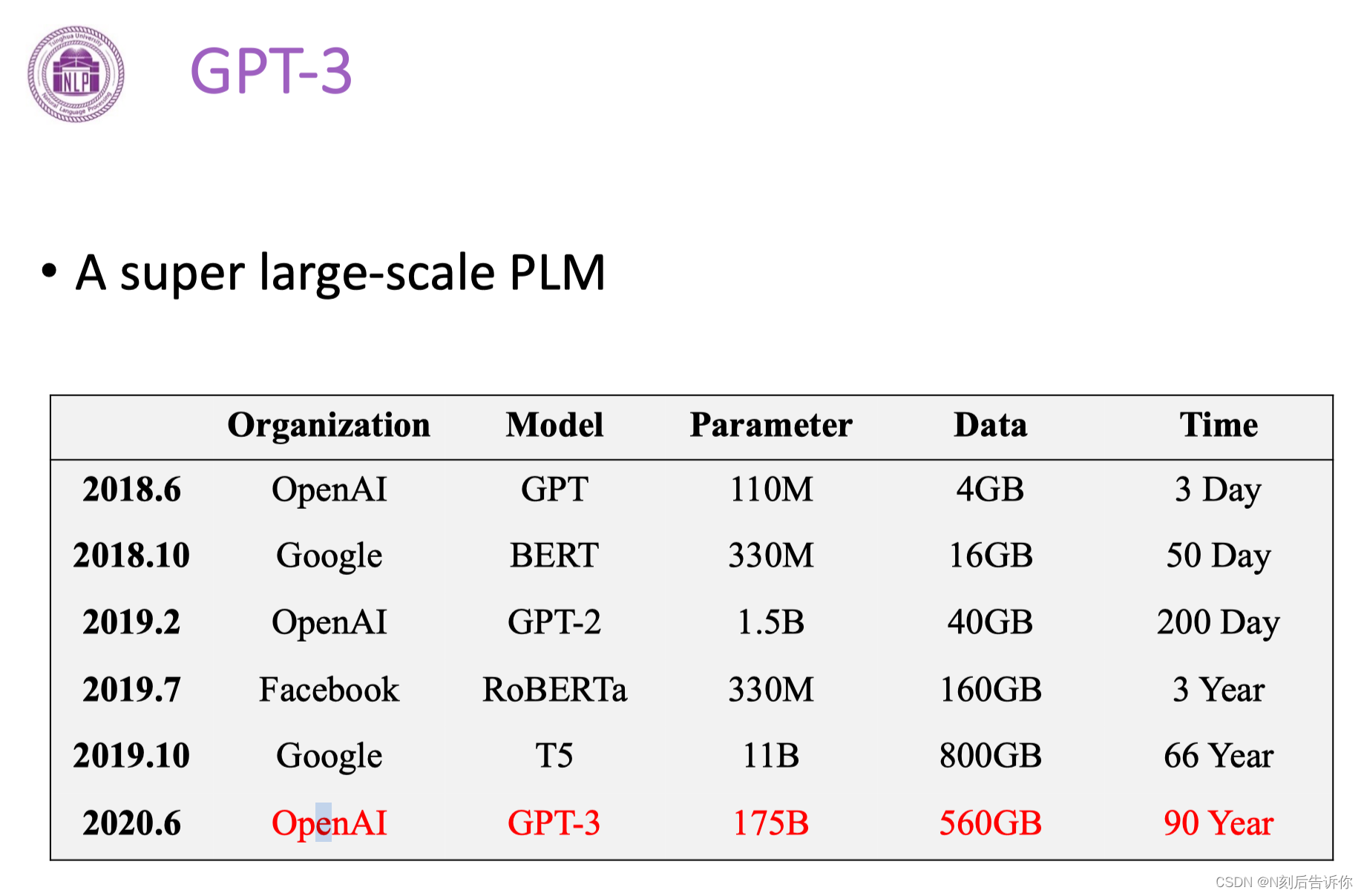
GPT3

T5
统一所有NLP任务为seq to seq的形式
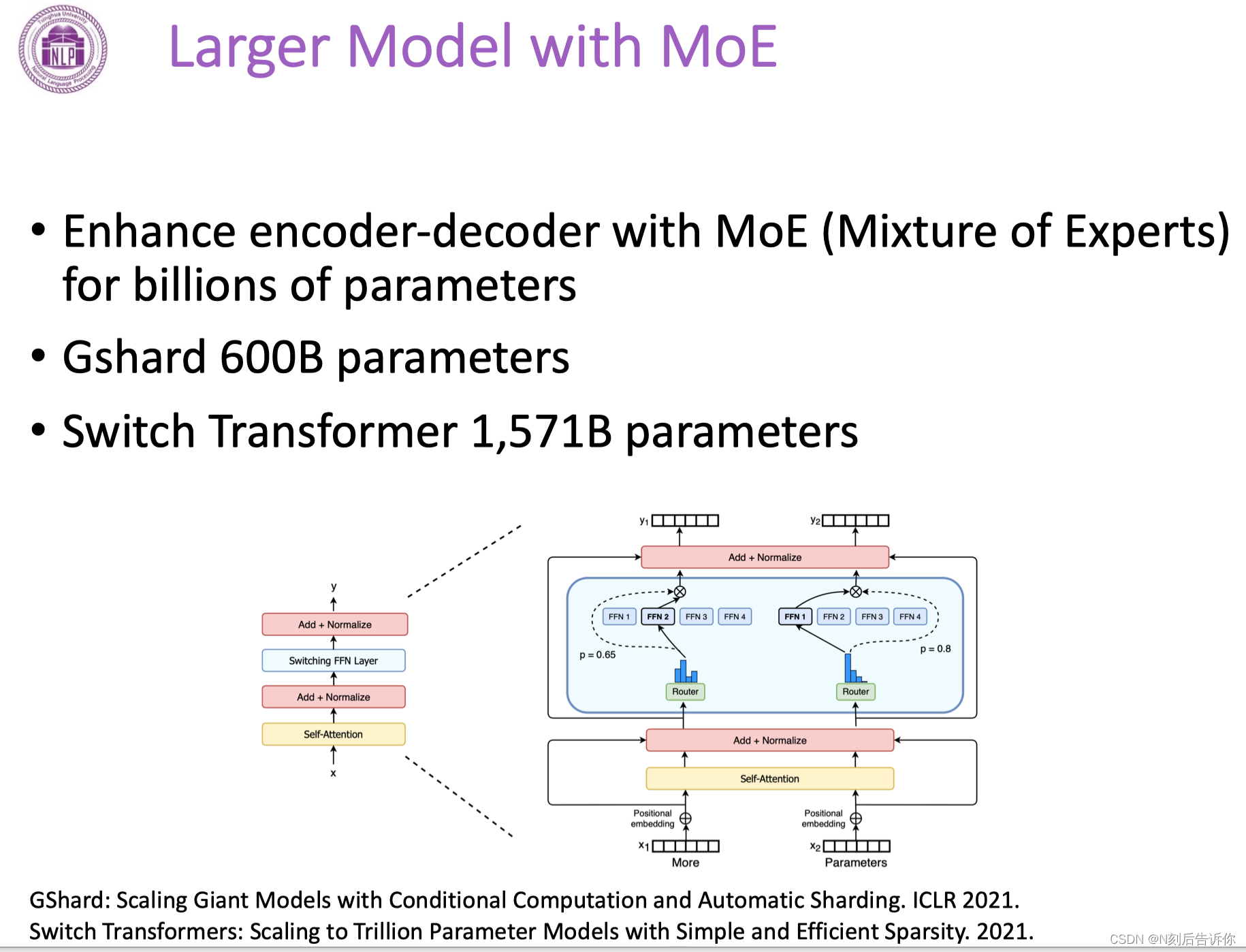
MoE
每次模型调用部分子模块来处理。涉及调度,负载均衡。
Transformers教程
介绍

使用Transformers的Pipeline

Tokenization

常用API

