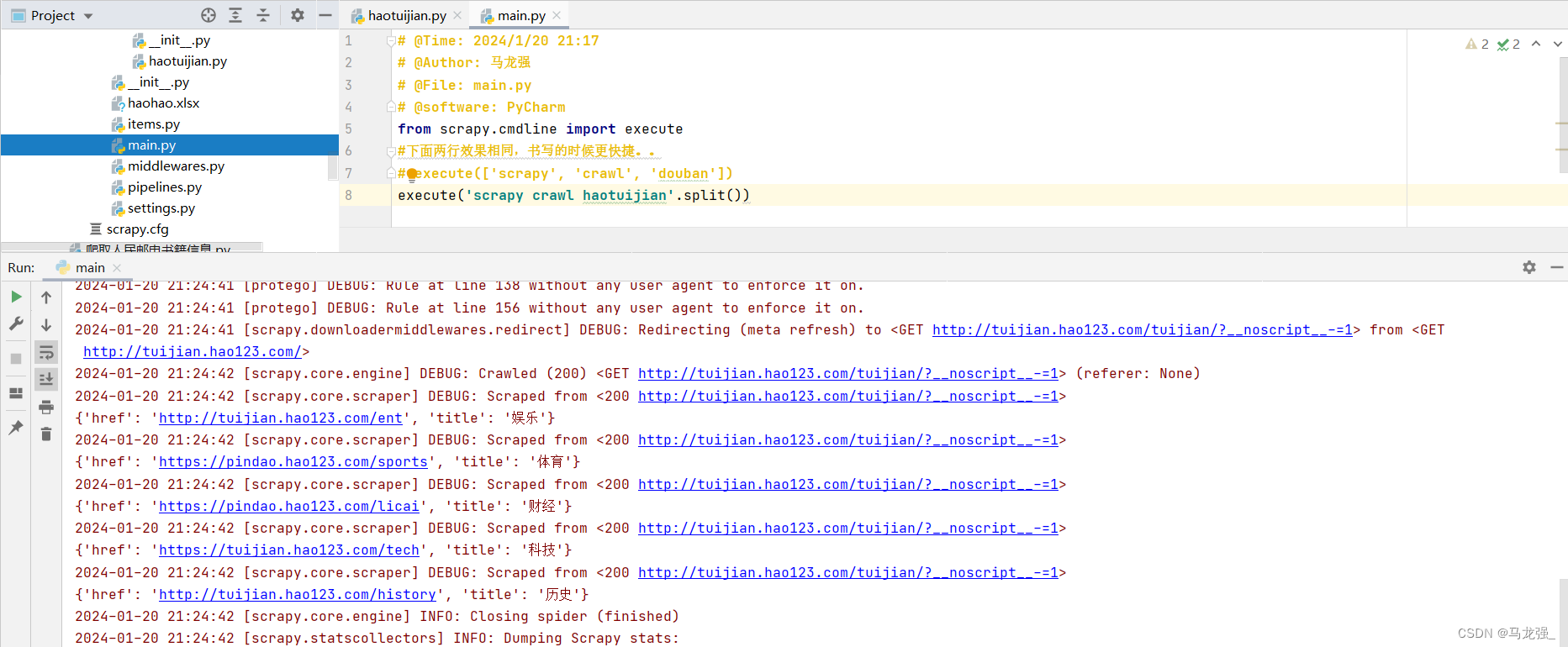
一、网页信息
 二、检查网页,找出目标内容
二、检查网页,找出目标内容
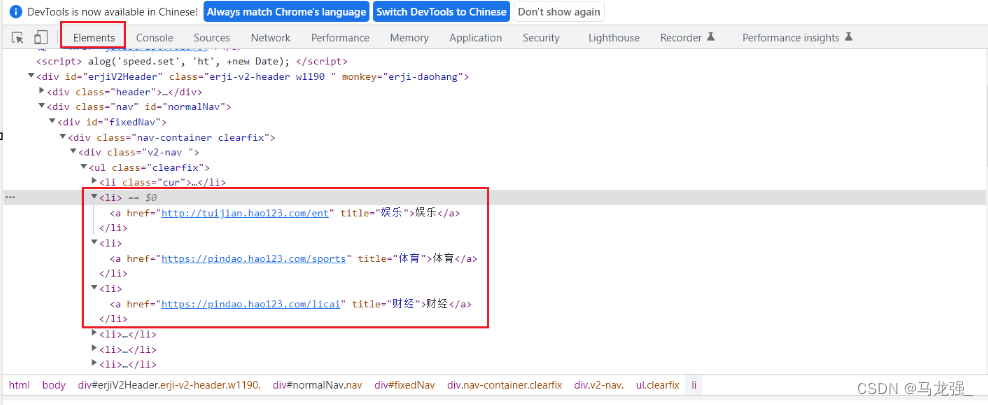
三、根据网页格式写正常爬虫代码
from bs4 import BeautifulSoup
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
}
url = 'http://tuijian.hao123.com/'
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'soup = BeautifulSoup(response.text, 'html.parser')
list_div = soup.find('div', class_='v2-nav')
ul_tags = list_div.find_all('ul')[0]
li_tags = ul_tags.find_all('li')for li in li_tags:a_tag = li.find('a')if a_tag:title = a_tag.texthref = a_tag['href']if title in ["娱乐", "体育", "财经", "科技", "历史"]:print(f"{title}: {href}")
四、创建Scrapy项目haohao
1.进入相关目录中,执行:scrapy startproject haohao
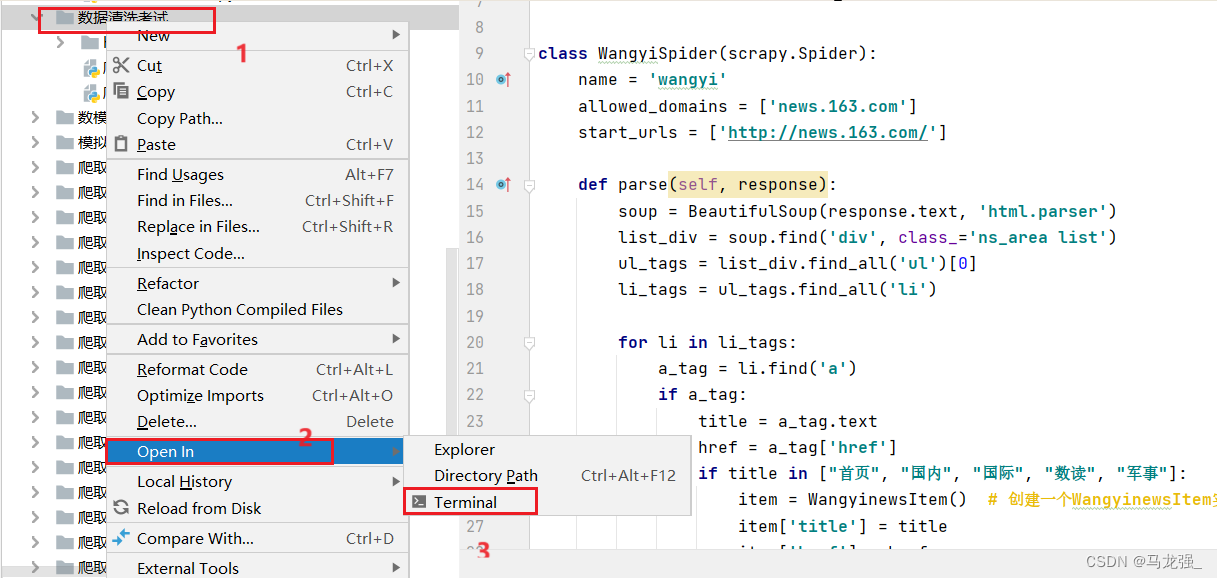
2.创建结果

五、创建爬虫项目haotuijian.py
1.进入相关目录中,执行:scrapy genspider haotuijian http://tuijian.hao123.com/

2.执行结果,目录中出现haotuijian.py文件
六、写爬虫代码和配置相关文件
1.haotuijian.py文件代码
import scrapy
from bs4 import BeautifulSoup
from ..items import HaohaoItemclass HaotuijianSpider(scrapy.Spider):name = 'haotuijian'allowed_domains = ['tuijian.hao123.com']start_urls = ['http://tuijian.hao123.com/']def parse(self, response):soup = BeautifulSoup(response.text, 'html.parser')list_div = soup.find('div', class_='v2-nav')ul_tags = list_div.find_all('ul')[0]li_tags = ul_tags.find_all('li')for li in li_tags:a_tag = li.find('a')if a_tag:title = a_tag.texthref = a_tag['href']if title in ["娱乐", "体育", "财经", "科技", "历史"]:item = HaohaoItem() # 创建一个HaohaoItem实例来传输保存数据item['title'] = titleitem['href'] = hrefyield item
2.items.py文件代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass HaohaoItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()href = scrapy.Field()
3.pipelines.py文件代码(保存数据到Mongodb、Mysql、Excel中)
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from pymongo import MongoClient
import openpyxl
import pymysql#保存到mongodb中
class HaohaoPipeline:def __init__(self):self.client = MongoClient('mongodb://localhost:27017/')self.db = self.client['qiangzi']self.collection = self.db['hao123']self.data = []def close_spider(self, spider):if len(self.data) > 0:self._write_to_db()self.client.close()def process_item(self, item, spider):self.data.append({'title': item['title'],'href': item['href'],})if len(self.data) == 100:self._write_to_db()self.data.clear()return itemdef _write_to_db(self):self.collection.insert_many(self.data)self.data.clear()#保存到mysql中
class MysqlPipeline:def __init__(self):self.conn = pymysql.connect(host='localhost',port=3306,user='root',password='789456MLq',db='pachong',charset='utf8mb4')self.cursor = self.conn.cursor()self.data = []def close_spider(self,spider):if len(self.data) > 0:self._writer_to_db()self.conn.close()def process_item(self, item, spider):self.data.append((item['title'],item['href']))if len(self.data) == 100:self._writer_to_db()self.data.clear()return itemdef _writer_to_db(self):self.cursor.executemany('insert into haohao (title,href)''values (%s,%s)',self.data)self.conn.commit()#保存到excel中
class ExcelPipeline:def __init__(self):self.wb = openpyxl.Workbook()self.ws = self.wb.activeself.ws.title = 'haohao'self.ws.append(('title','href'))def open_spider(self,spider):passdef close_spider(self,spider):self.wb.save('haohao.xlsx')def process_item(self,item,spider):self.ws.append((item['title'], item['href']))return item
4.settings.py文件配置



七、运行代码
1.进入相关目录,执行:scrapy crawl haotuijian
2.执行过程
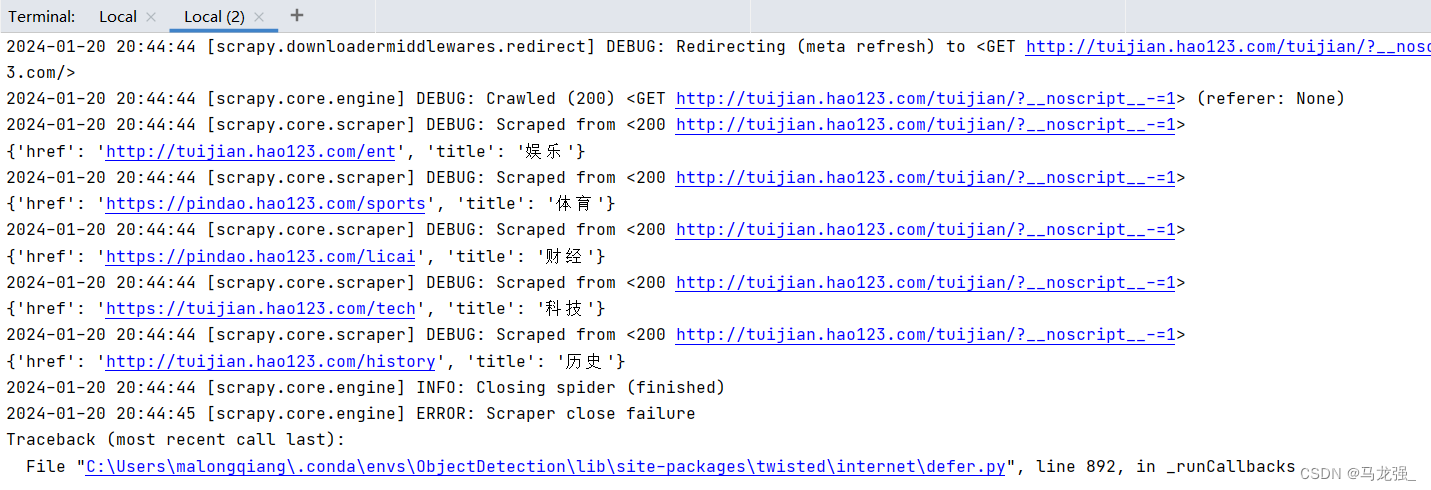
3.执行结果
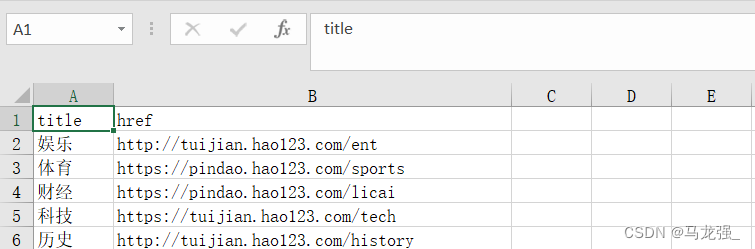
(1) haohao.excel
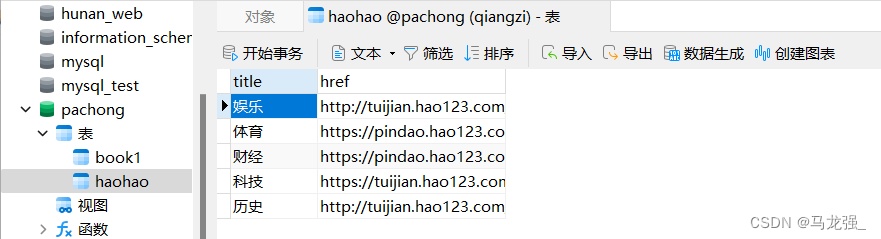
(2) Mysql:haohao (需提前创建表)
(3)Mongodb: hao123
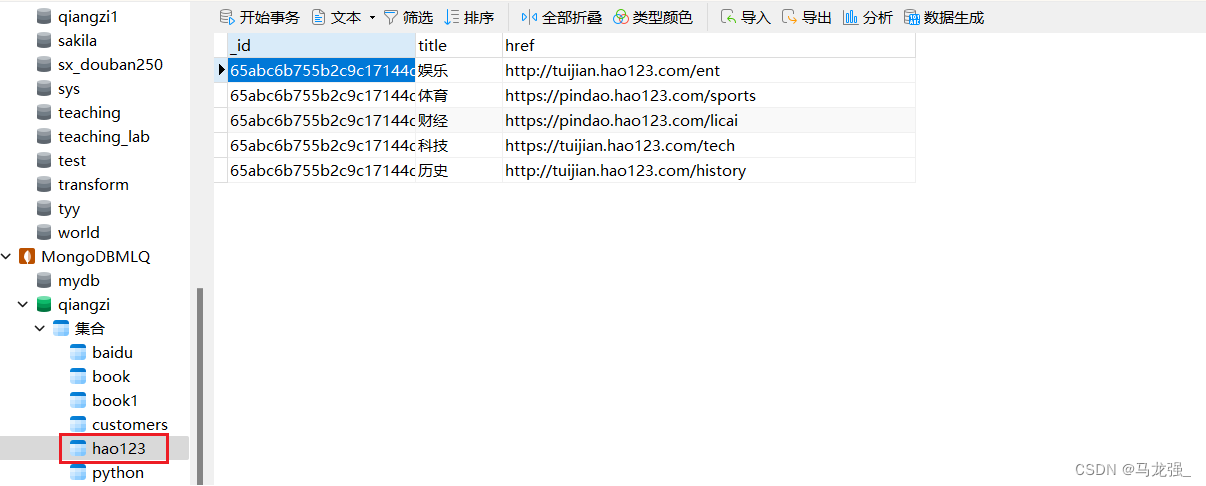
八、知识补充
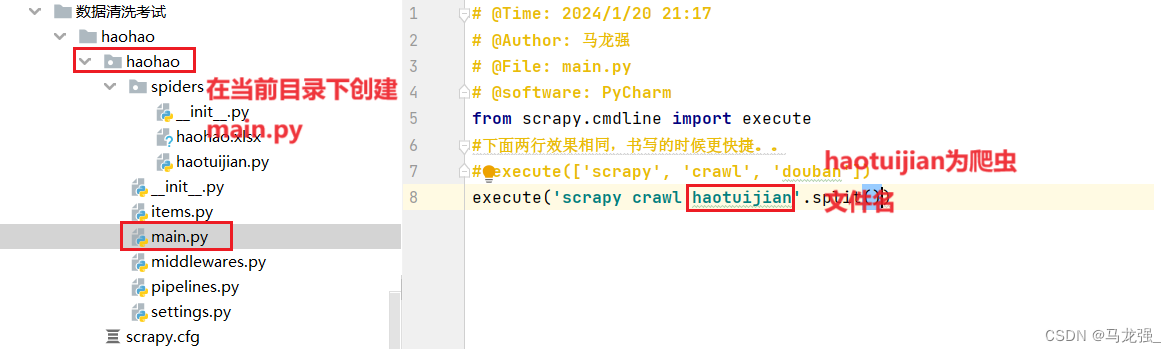
1.创建main.py文件,并编写代码
2.直接运行main.py文件
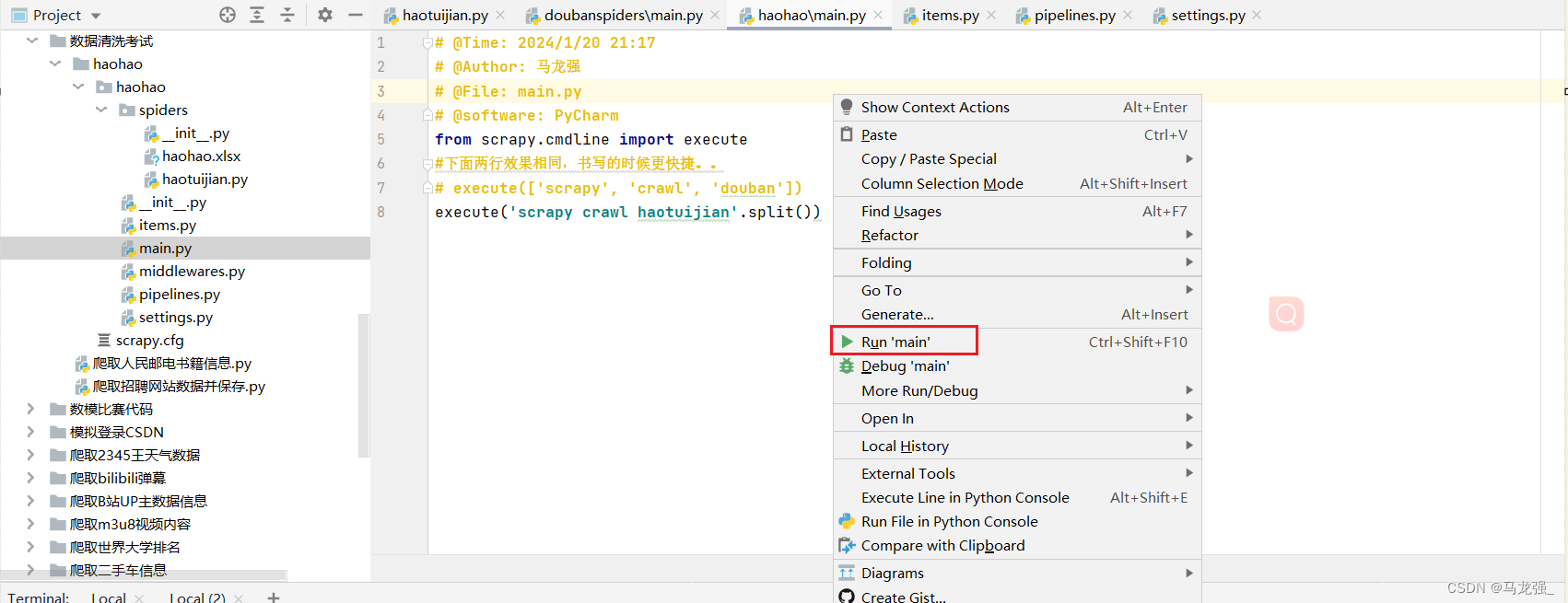
3.运行结果与使用指令运行结果相同(只不过运行过程变成了红色,但可以像普通python代码一样可以随时暂停)