探秘网络爬虫的基本原理与实例应用
1. 基本原理
网络爬虫是一种用于自动化获取互联网信息的程序,其基本原理包括URL获取、HTTP请求、HTML解析、数据提取和数据存储等步骤。
-
URL获取: 确定需要访问的目标网页,通过人工指定、站点地图或之前的抓取结果获取URL。
-
HTTP请求: 发送HTTP请求向目标服务器请求页面内容,通常使用GET请求,服务器返回相应的HTML页面或其他格式的数据。
-
HTML解析: 解析HTML页面,使用解析器库如Beautiful Soup或lxml,以便更方便地提取数据。
-
数据提取: 在HTML解析的基础上,通过选择器或正则表达式等方式,定位和提取所需的数据。
-
数据存储: 将提取到的数据保存到本地文件、数据库或其他数据存储介质中。
2. 百度是如何搜到CSDN的
百度搜素引擎通过爬虫技术实现网页的抓取和索引。当用户在百度搜索框中输入关键词时,百度就会将之前爬取的结果展示出来了:
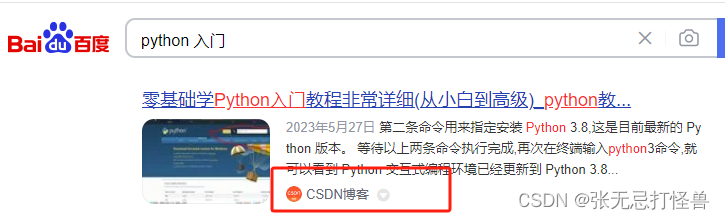
-
抓取: 百度爬虫按照一定的算法和策略抓取与用户搜索相关的网页。这包括在互联网上爬取网页的内容、链接等信息。
-
索引: 抓取到的网页被存储在百度的数据库中,建立索引以便能够快速检索。索引包括关键词、页面内容、链接等信息。
当用户输入关键词,百度根据索引中的信息找到匹配的网页,并按照一定的排名算法呈现给用户,其中包括了CSDN等相关网页。
3. Python爬虫简单实例
以下是一个使用Python实现的简单网络爬虫示例,通过爬取百度首页的标题:
import requests
from bs4 import BeautifulSoup# 发送HTTP请求
response = requests.get("https://www.baidu.com")
html_content = response.text# HTML解析
soup = BeautifulSoup(html_content, 'html.parser')
# 提取标题
title = soup.title.text# 打印结果
print(f"百度首页标题:{title}")
这个例子使用了requests库发送HTTP请求,BeautifulSoup库解析HTML页面,然后提取了页面的标题信息。这只是一个简单的入门示例,实际爬虫应用可能需要更复杂的处理和对抗反爬机制的策略。在实际应用中,请确保你的爬虫行为合法,遵守网站的规则和法规。