WeNet语音识别+Qwen-72B-Chat Bot+Sambert-Hifigan语音合成
WeNet语音识别+Qwen-72B-Chat Bot👾+Sambert-Hifigan语音合成
简介
利用 WeNet 进行语音识别,使用户能够通过语音输入与系统进行交互。接着,Qwen-72B-Chat Bot作为聊天机器人接收用户的语音输入或文本输入,提供响应并与用户进行对话。最后,系统利用 Sambert-Hifigan 进行语音合成,将机器人的响应转换为自然流畅的语音输出,使用户能够以语音方式接收机器人的回复。
特点
-
对话记忆功能: 该系统能够记忆和追踪用户和聊天机器人之间的对话历史。这使得用户能够在对话中随时回顾之前的交流内容,从而实现更连贯的对话和更好的交互体验。
-
多语音模型切换: 该系统支持多种语音模型的切换。用户可以根据需要选择不同的语音模型进行交互。这种多语音模型切换功能使得系统在不同语境下有更强的适用性和灵活性。
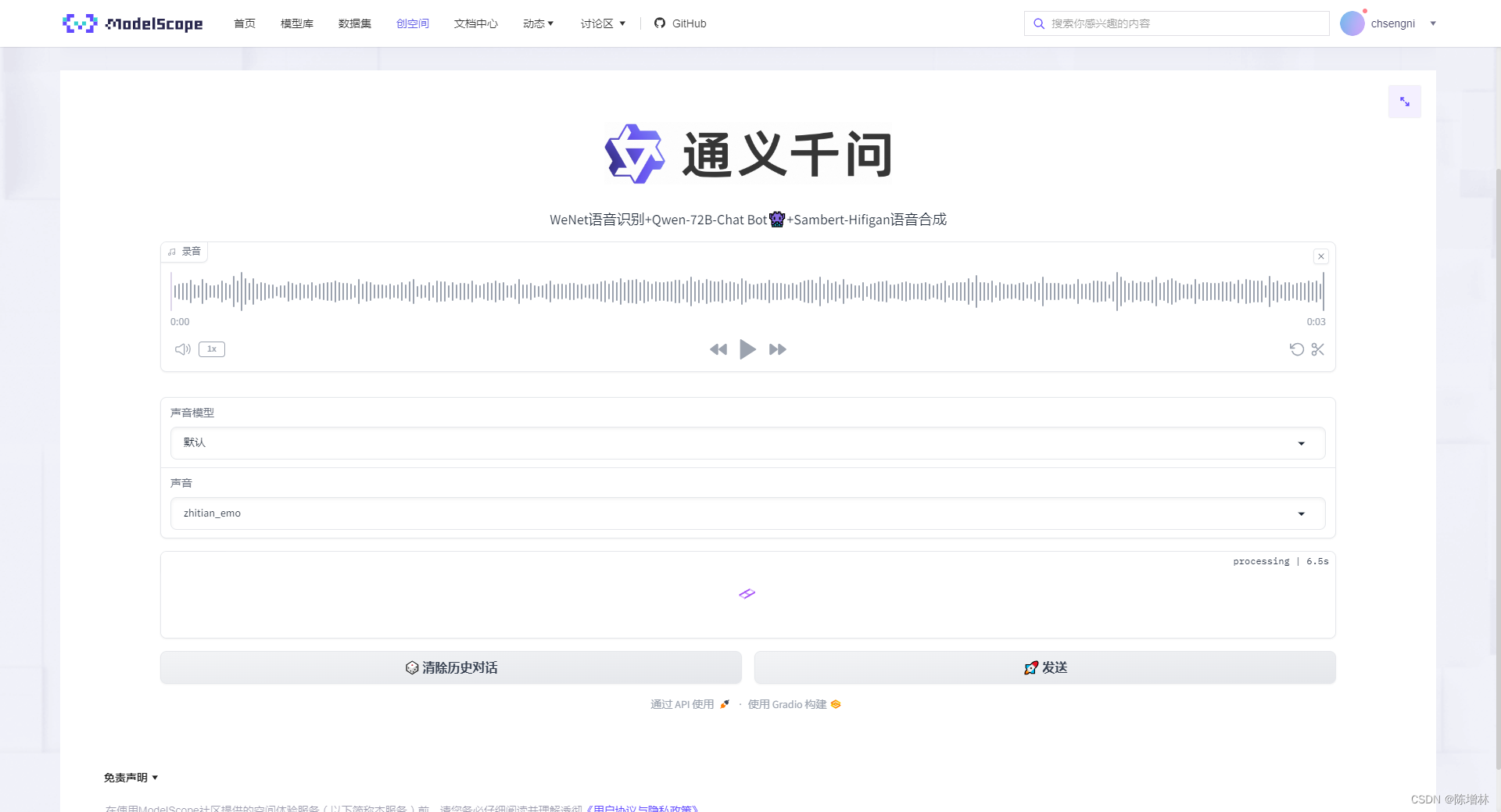
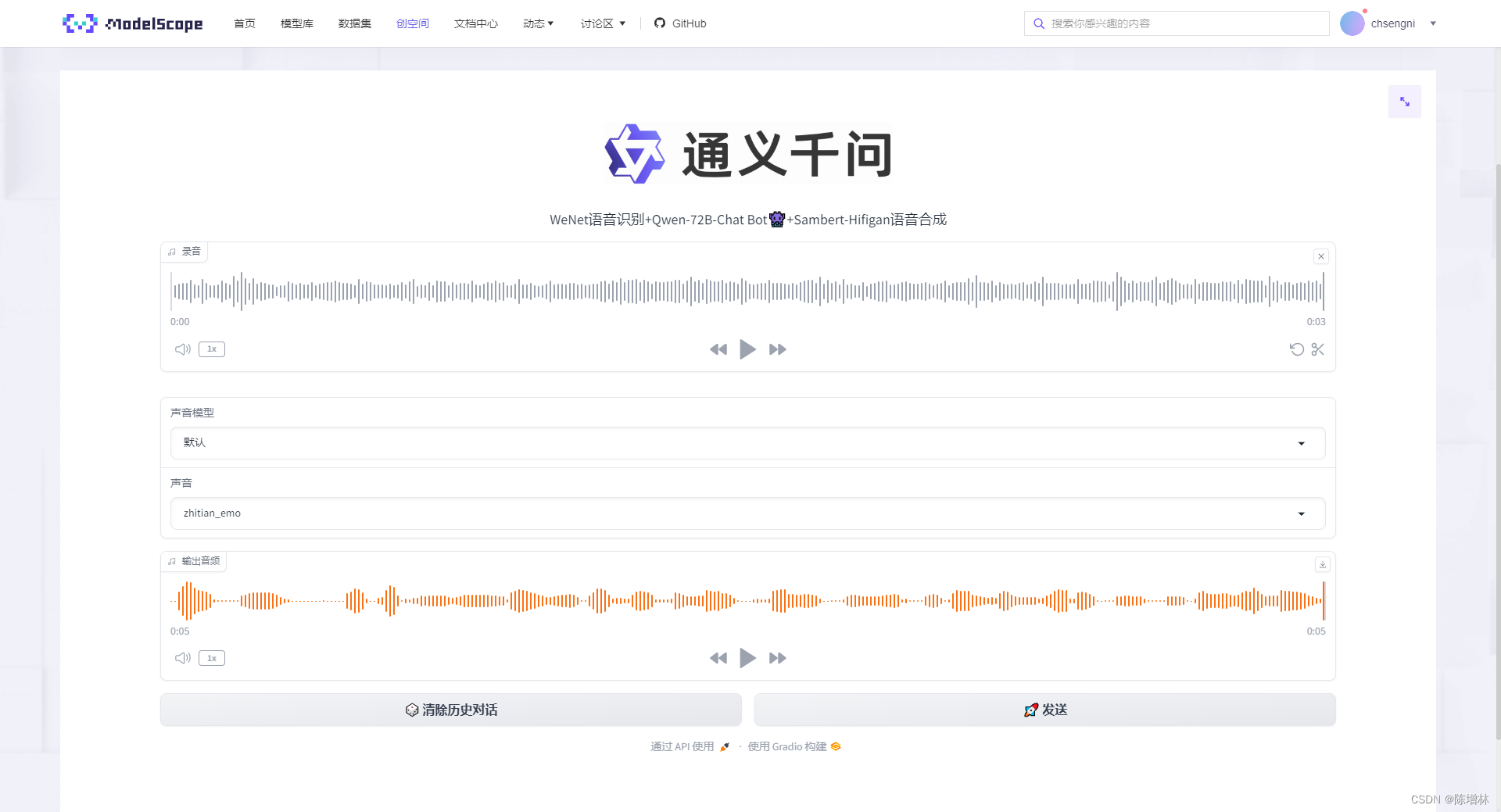
界面
体验一下

环境配置
完整代码
import os
os.system('pip install dashscope')
os.system('pip install modelscope')
import gradio as gr
from http import HTTPStatus
import dashscope
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
from typing import List, Optional, Tuple, Dict
from urllib.error import HTTPError
import wenet
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasksdefault_system = 'You are a helpful assistant.'
chs_model = wenet.load_model('chinese')
YOUR_API_TOKEN = os.getenv('YOUR_API_TOKEN')
dashscope.api_key = YOUR_API_TOKEN
History = List[Tuple[str, str]]
Messages = List[Dict[str, str]]# 加载四个不同的语音合成模型
sambert_hifigan_zh_model_id = 'damo/speech_sambert-hifigan_tts_zh-cn_16k'
sambert_hifigan_zh = pipeline(task=Tasks.text_to_speech, model=sambert_hifigan_zh_model_id)sambert_hifigan_ch_model_id = 'speech_tts/speech_sambert-hifigan_tts_chuangirl_Sichuan_16k'
sambert_hifigan_ch = pipeline(task=Tasks.text_to_speech, model=sambert_hifigan_ch_model_id)sambert_hifigan_ca_model_id = 'speech_tts/speech_sambert-hifigan_tts_jiajia_Cantonese_16k'
sambert_hifigan_ca = pipeline(task=Tasks.text_to_speech, model=sambert_hifigan_ca_model_id)sambert_hifigan_ws_model_id = 'speech_tts/speech_sambert-hifigan_tts_xiaoda_WuuShanghai_16k'
sambert_hifigan_ws = pipeline(task=Tasks.text_to_speech, model=sambert_hifigan_ws_model_id)def clear_session() -> History:return []def modify_system_session(system: str) -> str:if system is None or len(system) == 0:system = default_systemreturn system, system, []def history_to_messages(history: History, system: str) -> Messages:messages = [{'role': Role.SYSTEM, 'content': system}]for h in history:messages.append({'role': Role.USER, 'content': h[0]})messages.append({'role': Role.ASSISTANT, 'content': h[1]})return messagesdef messages_to_history(messages: Messages) -> Tuple[str, History]:assert messages[0]['role'] == Role.SYSTEMsystem = messages[0]['content']history = []for q, r in zip(messages[1::2], messages[2::2]):history.append([q['content'], r['content']])return system, historydef model_chat(path:str, history: Optional[History], system: str,model:str,voice:str
) -> Tuple[str, str, History]:if path is not None:query = chs_model.transcribe(path)['text']if query is None:query = ''if history is None:history = []messages = history_to_messages(history, system)messages.append({'role': Role.USER, 'content': query})gen = Generation.call(model = "qwen-72b-chat",messages=messages,result_format='message',stream=True)for response in gen:if response.status_code == HTTPStatus.OK:role = response.output.choices[0].message.roleresponse = response.output.choices[0].message.contentsystem, history = messages_to_history(messages + [{'role': role, 'content': response}])else:raise HTTPError('Request id: %s, Status code: %s, error code: %s, error message: %s' % (response.request_id, response.status_code,response.code, response.message))output=None# 进行语音合成sambert_hifigan_tts_model = {'默认': sambert_hifigan_zh,'四川话': sambert_hifigan_ch,'粤语': sambert_hifigan_ca,'上海话': sambert_hifigan_ws}# 使用对应的语音合成模型进行合成sambert_hifigan_tts = sambert_hifigan_tts_model.get(model)if model == '默认':output = sambert_hifigan_tts(input=response, voice=voice)else:output = sambert_hifigan_tts(input=response)wav = output[OutputKeys.OUTPUT_WAV]path = 'output.wav'with open(path, 'wb') as f:f.write(wav)return history, system, pathdef update_dropdowns(model,voice): if model == "默认": voice=gr.Dropdown(choices=['zhitian_emo', 'zhiyan_emo', 'zhizhe_emo', 'zhibei_emo'], value='zhitian_emo',label="声音",visible=True) else: voice=gr.Dropdown(choices=['zhitian_emo', 'zhiyan_emo', 'zhizhe_emo', 'zhibei_emo'], value='zhitian_emo',label="声音",visible=False)return voice
with gr.Blocks() as demo:gr.Markdown("""<p align="center"><img src="https://modelscope.cn/api/v1/models/qwen/Qwen-VL-Chat/repo?Revision=master&FilePath=assets/logo.jpg&View=true" style="height: 80px"/><p>""")gr.Markdown("""<center><font size=4>WeNet语音识别+Qwen-72B-Chat Bot👾+Sambert-Hifigan语音合成</center>""")textbox = gr.Microphone(type="filepath",label='录音')with gr.Row():with gr.Column(scale=3):system_input = gr.Textbox(value=default_system, lines=1, label='System', visible=False)with gr.Column(scale=1):modify_system = gr.Button("🛠️ 设置system并清除历史对话", scale=2, visible=False)system_state = gr.Textbox(value=default_system, visible=False)chatbot = gr.Chatbot(label='Qwen-72B-Chat', visible=False)model=gr.Dropdown(choices=['默认', '四川话', '粤语', '上海话'], value='默认',label="声音模型")voice = gr.Dropdown(choices=['zhitian_emo', 'zhiyan_emo', 'zhizhe_emo', 'zhibei_emo'], value='zhitian_emo',label="声音")audio_output = gr.Audio(type="filepath",label='输出音频',autoPlay=True)with gr.Row():clear_history = gr.Button("🎲 清除记忆")sumbit = gr.Button("🚀 发送")model.change(update_dropdowns,inputs=[model,voice],outputs=[voice])sumbit.click(model_chat,inputs=[textbox, chatbot, system_state,model,voice],outputs=[chatbot, system_input,audio_output],concurrency_limit=10)clear_history.click(fn=clear_session,inputs=[],outputs=[chatbot],concurrency_limit=10)modify_system.click(fn=modify_system_session,inputs=[system_input],outputs=[system_state, system_input, chatbot],concurrency_limit=10)
demo.queue(api_open=False).launch(height=800, share=False)