CNN——VGG
1.VGG简介
论文下载地址:https://arxiv.org/pdf/1409.1556.pdf
VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军(冠军由 GoogLeNet 以 6.65% 的错误率夺得)和 25.32% 的错误率夺得定位任务(Localization)的第一名(GoogLeNet 错误率为 26.44%)。
VGG通过vgg块的堆积,VGG19最高让网络达到了16 个卷积层和 3 个全连接层,共计 19 层网络(池化层不带参数,一般不算一层)。这也导致参数量非常的多,模型比较臃肿(第一个全连接层占了非常大一部分)
包括VGG11,VGG13,VGG16和VGG19,性能依次提升,最常用的是VGG16。
 核心点:
核心点:
- 全部使用3×3步长为1的小卷积核。3×3卷积核是最小的能够表示上下左右中心的尺寸。
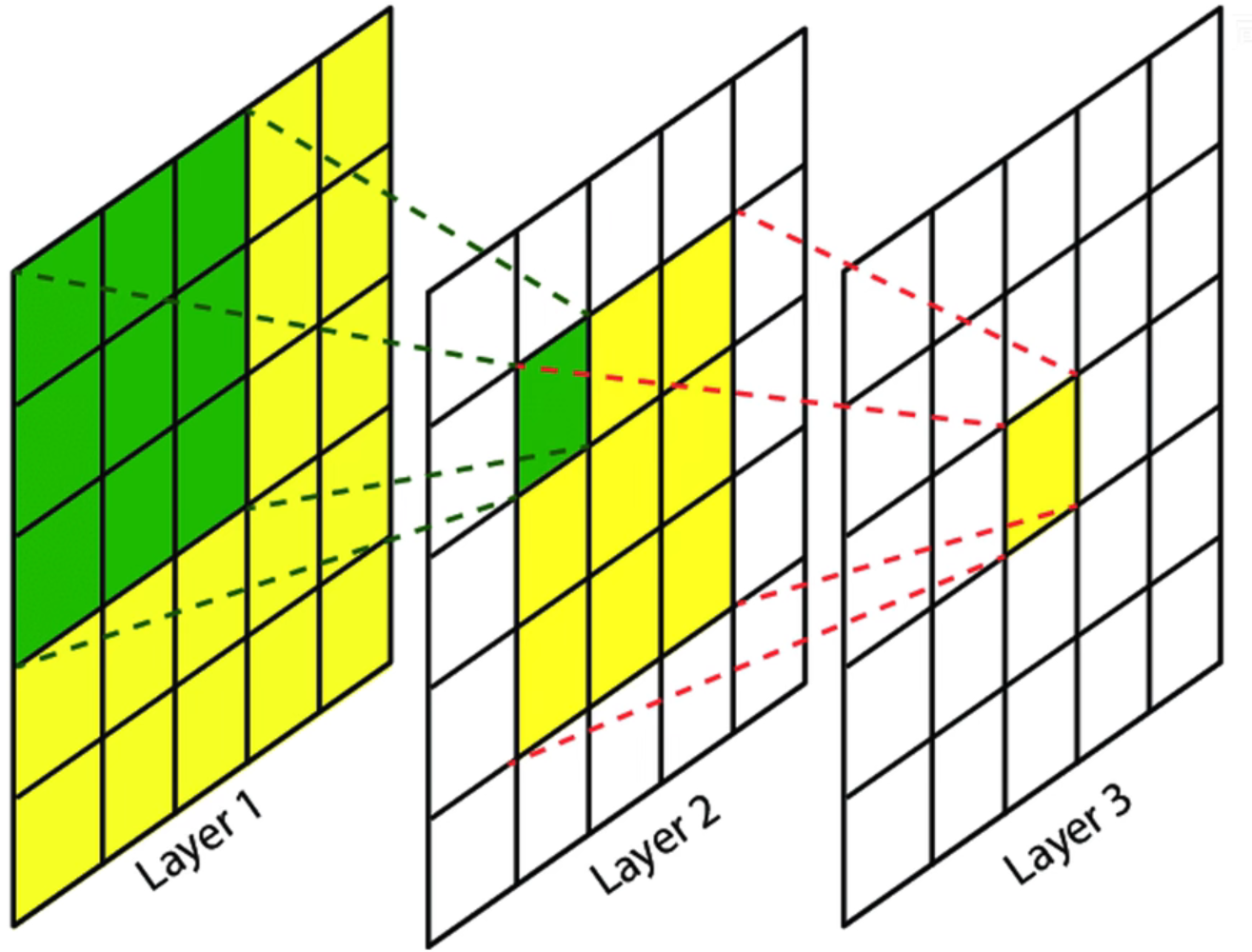
假设输入为5×5,使用2次3×3卷积后最终得到1×1的特征图,那么这个1×1的特征图的感受野为5×5。这和直接使用一个5×5卷积核得到1×1的特征图是一样的。也就是说2次3×3卷积可以代替一次5×5卷积同时,2次3×3卷积的参数更少(2×3×3=18<5×5=25)而且会经过两次激活函数进行非线性变换,学习能力会更好。同样的3次3×3卷积可以替代一次7×7的卷积。
此外步长为1可以不会丢失信息
2.相同的vgg块堆叠
3.深度深,且成功证明深度增加可以提高网络性能
2.VGG网络结构详解
这里以最常用的VGG16为例子。VGG11,VGG13,VGG19都是根据上面的表使用不同的卷积个数。

vgg_block包括若干个3×3卷积(padding=1,stride=1)+激活+2×2池化(padding=0,stride=2),第一个卷积将通道数翻倍
- 3×3卷积,padding=1,stride=1,output=(input-3+2×1)/1+1=input,特征图尺寸不变
- 2×2池化,padding=0,stride=2,output=(input-2)/2+1=1/2input,特征图尺寸减半
1.输入层。224×224×3,RGB图
2.vgg_block1
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 3 | 64 | 224×224 |
| Relu激活 | / | / | 64 | 64 | 224×224 |
| 3×3卷积 | 1 | 1 | 64 | 64 | 224×224 |
| Relu激活 | / | / | 64 | 64 | 224×224 |
| 2×2最大池化 | 0 | 2 | 64 | 64 | 112×112 |
2.vgg_block2
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 64 | 128 | 112×112 |
| Relu激活 | / | / | 128 | 128 | 112×112 |
| 3×3卷积 | 1 | 1 | 128 | 128 | 112×112 |
| Relu激活 | / | / | 128 | 128 | 112×112 |
| 2×2最大池化 | 0 | 2 | 128 | 128 | 56×56 |
3.vgg_block3
从这个块开始卷积变成3次
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 128 | 256 | 56×56 |
| Relu激活 | / | / | 256 | 256 | 56×56 |
| 3×3卷积 | 1 | 1 | 256 | 256 | 56×56 |
| Relu激活 | / | / | 256 | 256 | 56×56 |
| 3×3卷积 | 1 | 1 | 256 | 256 | 56×56 |
| Relu激活 | / | / | 256 | 256 | 56×56 |
| 2×2最大池化 | 0 | 2 | 256 | 256 | 28×28 |
4.vgg_block4
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 256 | 512 | 28×28 |
| Relu激活 | / | / | 512 | 512 | 28×28 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 28×28 |
| Relu激活 | / | / | 512 | 512 | 28×28 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 28×28 |
| Relu激活 | / | / | 512 | 512 | 28×28 |
| 2×2最大池化 | 0 | 2 | 512 | 512 | 14×14 |
4.vgg_block5
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 14×14 |
| Relu激活 | / | / | 512 | 512 | 14×14 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 14×14 |
| Relu激活 | / | / | 512 | 512 | 14×14 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 14×14 |
| Relu激活 | / | / | 512 | 512 | 14×14 |
| 2×2最大池化 | 0 | 2 | 512 | 512 | 7×7 |
6.向量化
flatten,7×7×512(25,088) ->> 1×1×25,088
7.全连接FC1
1×1×25,088 ->>1×1×4096
8.全连接FC2
1×1×4096 ->> 1×1×4096
9.全连接FC3(Softmax)
1×1×4096 ->> 1×1×1000
3.VGGPytorch实现
3.1 手动实现VGG
# 定义VGG块
def vgg_block(num_convs, in_channels, out_channels):layers = [] # 初始化一个空列表用于存放层(卷积层和ReLU激活函数)for _ in range(num_convs): # 循环创建指定数量的卷积层和ReLU激活函数layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) # 添加一个卷积层layers.append(nn.ReLU(inplace=True)) # 添加一个ReLU激活函数,并在原地执行节省内存in_channels = out_channels # 更新输入通道数为输出通道数,以便下一层使用layers.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 添加一个最大池化层return nn.Sequential(*layers) # 返回一个由这些层组成的Sequential模型# 定义VGG网络
class VGG(nn.Module):def __init__(self, cfg, num_classes=1000):super(VGG, self).__init__()self.conv_layers = self._make_layers(cfg) # 创建VGG的卷积层部分self.fc_layers = nn.Sequential( # 创建VGG的全连接层部分nn.Linear(512 * 7 * 7, 4096), # 全连接层1nn.ReLU(inplace=True), # ReLU激活函数nn.Dropout(), # Dropout层用于防止过拟合nn.Linear(4096, 4096), # 全连接层2nn.ReLU(inplace=True), # ReLU激活函数nn.Dropout(), # Dropout层用于防止过拟合nn.Linear(4096, num_classes) # 全连接层3,输出类别数)self.flatten = nn.Flatten()def forward(self, x):x = self.conv_layers(x) # 卷积层部分x = self.flatten(x) # 将特征张量展平以输入全连接层x = self.fc_layers(x) # 全连接层部分return xdef _make_layers(self, cfg):layers = [] # 初始化一个空列表用于存放VGG的层in_channels = 3 # 输入通道数为RGB图像的3通道for num_convs, out_channels in cfg:layers.append(vgg_block(num_convs, in_channels, out_channels)) # 添加VGG块in_channels = out_channels # 更新输入通道数为输出通道数,以便下一层使用return nn.Sequential(*layers) # 返回一个由VGG块组成的Sequential模型# 不同版本的VGG配置
cfgs = {'VGG11': [(1, 64), (1, 128), (2, 256), (2, 512), (2, 512)], # VGG11的卷积层配置'VGG13': [(2, 64), (2, 128), (2, 256), (2, 512), (2, 512)], # VGG13的卷积层配置'VGG16': [(2, 64), (2, 128), (3, 256), (3, 512), (3, 512)], # VGG16的卷积层配置'VGG19': [(2, 64), (2, 128), (4, 256), (4, 512), (4, 512)] # VGG19的卷积层配置
}# 实例化不同版本的VGG
def get_vgg(model_name, num_classes=1000):cfg = cfgs[model_name] # 获取指定版本的VGG配置model = VGG(cfg, num_classes) # 根据配置创建相应版本的VGG模型return model # 返回指定版本的VGG模型# 实例化不同版本的VGG示例
# vgg11 = get_vgg('VGG11')
# vgg13 = get_vgg('VGG13')
vgg16 = get_vgg('VGG16') # 修改分类数目,vgg16 = get_vgg('VGG16',num_classes=10)
# vgg19 = get_vgg('VGG19')summary(vgg16.to(device), (3, 224, 224))
3.2 手动实现VGG16简易版
还有一个简单易懂的实现方式,如VGG16实现如下。但这种方式如果网络比较深代码就比较冗长了,而且一次只能实现一种模型
# 定义VGG16模型结构
class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()# 特征层self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.flatten = nn.Flatten()# 分类层 self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.flatten(x)x = self.classifier(x)return x3.2 使用Pytorch自带的VGG
官方文档:VGG — Torchvision 0.16 documentation (pytorch.org)。Pytorch官方实现了VGG,并且还附带有在ImageNet上预训练权重

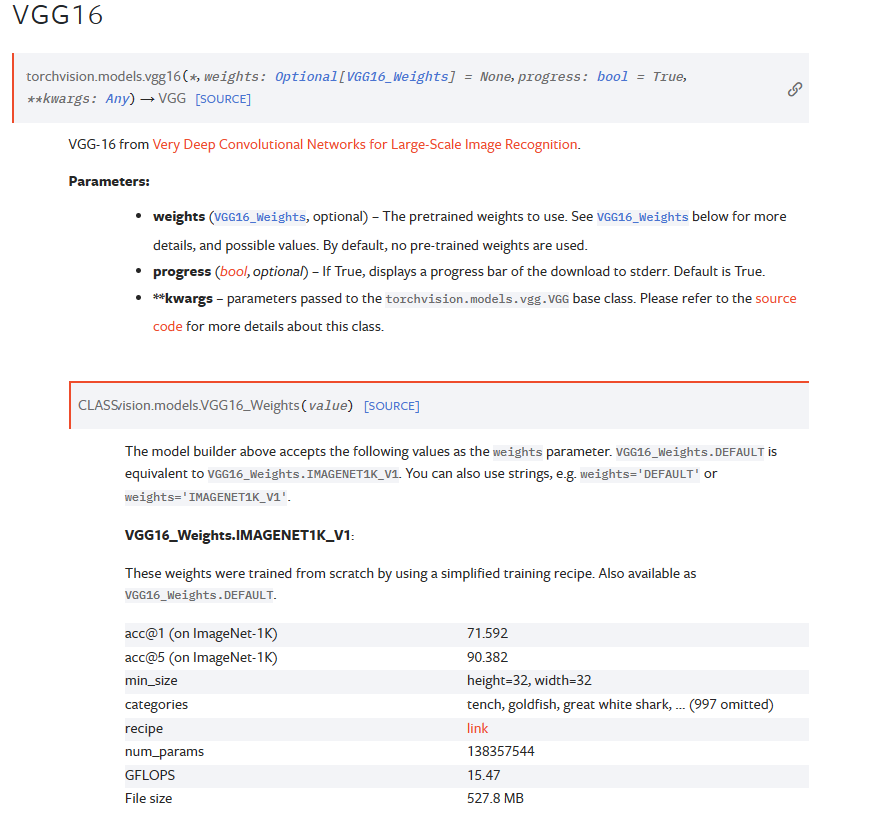
可以看到还有bn版本可选,即在卷积后增加使用了batch-normalization批量归一化。下面是使用的示例:
# 初始化预训练的vgg16模型
modelPre = models.vgg16(weights='DEFAULT')
summary(modelPre.to(device), (3, 224, 224))![]()
weights='DEFAULT'会默认使用最新最好的权重,或者直接指明weights='IMAGENET1K_V1',什么模型有什么权重可以直接去官方文档中查看就好。

除了加入了全局平均池化层之外,其他和我们自己实现的是一样的。全局平均池化层可以支持任意输入尺寸,无论31输出什么尺寸,全部变成7×7
4.VGG在CIFAR-10简单实践
所需库
import torch
import torch.nn as nn
from torchsummary import summary
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
from torchvision import models
import matplotlib.pyplot as plt1.修改网络结构
CIFAR-10输入尺寸为32×32,为了适应该数据集,需要简单修改一下第一层全连接层的输入参数。根据网络结构,尺寸会减半5次,对于224×224来说会降到7,则会降低到1。
将nn.Linear(512 * 7 * 7, 4096)修改为nn.Linear(512 * 1 * 1, 4096)
# 定义VGG16模型结构
class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()# 特征层self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.flatten = nn.Flatten()# 分类层 self.classifier = nn.Sequential(#nn.Linear(512 * 7 * 7, 4096),nn.Linear(512 * 1 * 1, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.flatten(x)x = self.classifier(x)return x# 打印模型结构
model = VGG16(num_classes=10).to(device)
summary(model, (3, 32, 32))
2.读取数据集
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./dataset', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./dataset', train=False, download=True, transform=transform)# 数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)3.使用GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'4.模型训练
def train(model, lr, epochs, train_dataloader, device, save_path):# 将模型放入GPUmodel = model.to(device)# 使用交叉熵损失函数loss_fn = nn.CrossEntropyLoss().to(device)# SGDoptimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=5e-4, momentum=0.9)# 记录训练与验证数据train_losses = []train_accuracies = []# 开始迭代 for epoch in range(epochs): # 切换训练模式model.train() # 记录变量train_loss = 0.0correct_train = 0total_train = 0# 读取训练数据并使用 tqdm 显示进度条for i, (inputs, targets) in tqdm(enumerate(train_dataloader), total=len(train_dataloader), desc=f"Epoch {epoch+1}/{epochs}", unit='batch'):# 训练数据移入GPUinputs = inputs.to(device)targets = targets.to(device)# 模型预测outputs = model(inputs)# 计算损失loss = loss_fn(outputs, targets)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 使用优化器优化参数optimizer.step()# 记录损失train_loss += loss.item()# 计算训练正确个数_, predicted = torch.max(outputs, 1)total_train += targets.size(0)correct_train += (predicted == targets).sum().item()# 计算训练正确率并记录train_loss /= len(train_dataloader)train_accuracy = correct_train / total_traintrain_losses.append(train_loss)train_accuracies.append(train_accuracy)# 输出训练信息print(f"Epoch [{epoch + 1}/{epochs}] - Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.4f}")# 绘制损失和正确率曲线plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.plot(range(epochs), train_losses, label='Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(range(epochs), train_accuracies, label='Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()torch.save(model.state_dict(), save_path)model = VGG16(num_classes=10)
lr = 0.0001
epochs = 10
save_path = './modelWeight/VGG16_CIFAR10'
train(model,lr,epochs,train_dataloader,device,save_path)