有了向量数据库,我们还需 SQL 数据库吗?
“除了向量数据库外,我是否还需要一个普通的 SQL 数据库?”
这是我们经常被问到的一个问题。如果除了向量数据以外,用户还有其他标量数据信息,那么其业务可能需要在进行语义相似性搜索前先根据某种条件过滤数据,例如:
-
在法律领域,可能只需要从某个特定数据库中搜索相关的法律条款;
-
在零售业,可能需要搜索某个尺码的男鞋;
-
在图像搜索时,可能希望搜索 2010-2016 年上映且 IMDB 电影评分高于 7.0 的电影的海报。
对此,我们的答案是——不需要。用向量数据库 Milvus 或全托管的 Milvus 服务——Zilliz Cloud,就无需额外再维护一个 SQL 数据库存储标量了。只要一个系统,用户便可起送实现“向量搜索+标量过滤”的混合查询,从而获取更精准的搜索结果。
其中,Milvus 允许用户在进行向量搜索时依据标量数据进行条件过滤,数据属性可以是除向量以外的任何字段。Milvus 会对向量字段创建向量索引并进行向量相似性搜索,与此同时,还可以通过表达式对搜索结果进行元数据过滤。只需在搜索时输入过滤表达式,Milvus 就会帮你自动进行这两种操作。
本教程使用 Zilliz Cloud Pipelines—— Zilliz Cloud 内置的功能,用于将非结构化数据编码为 Embedding 向量,同时支持用文本和过滤表达式直接搜索向量。我们将演示如何利用标量过滤来召回只符合某些特定条件的文档片段,例如特定的来源网址,或者特定的文件名称。大家也可以利用类似的思路实现召回带有特定标签的文档,例如发表年份、版本号等。
01. 创建 Collection 和 Pipelines
本教程需要用到 Zilliz Cloud 免费版(海外版)。Zilliz Cloud 是全托管的 Milvus 服务,将用户的数据库部署在 Serverless 云服务器上,但我们仍旧可以通过调用 PyMiluvs API 接口在本地使用 Zilliz Cloud 向量数据库。以下用来测试的文本内容来自于 PyMilvus 文档
-
打开 https://cloud.zilliz.com/ 并创建 “Starter” 版本集群。
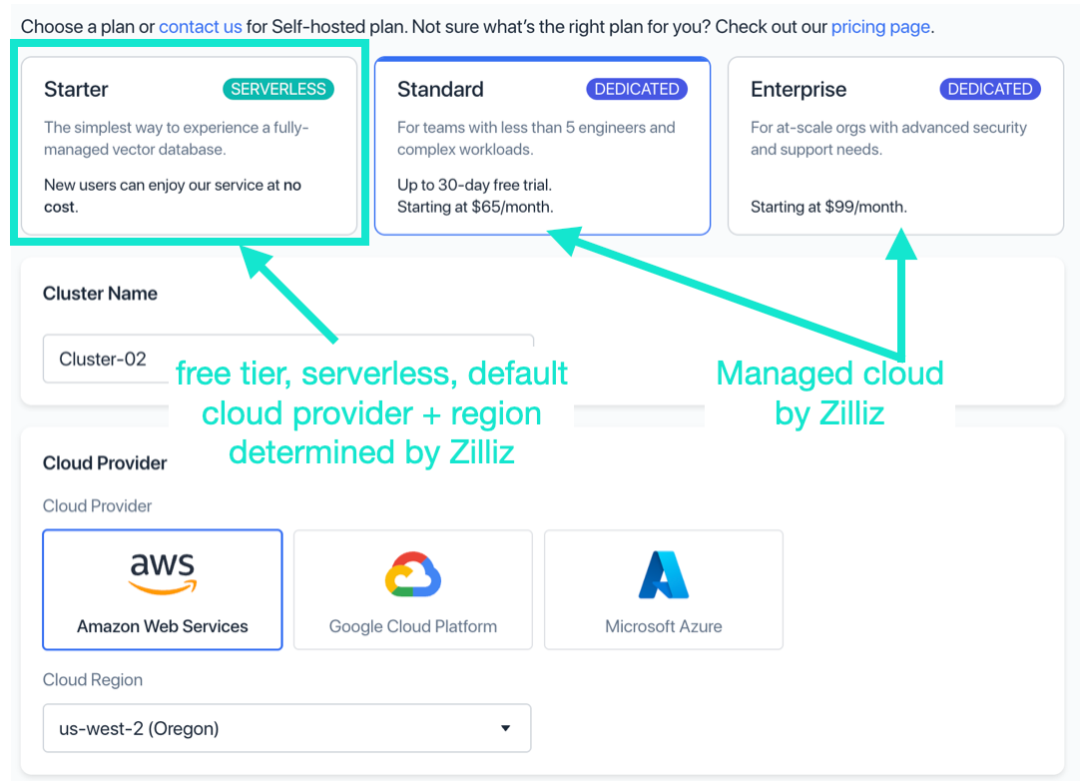
-
添加 Collection 名称,点击“创建 Collection 和 集群”。
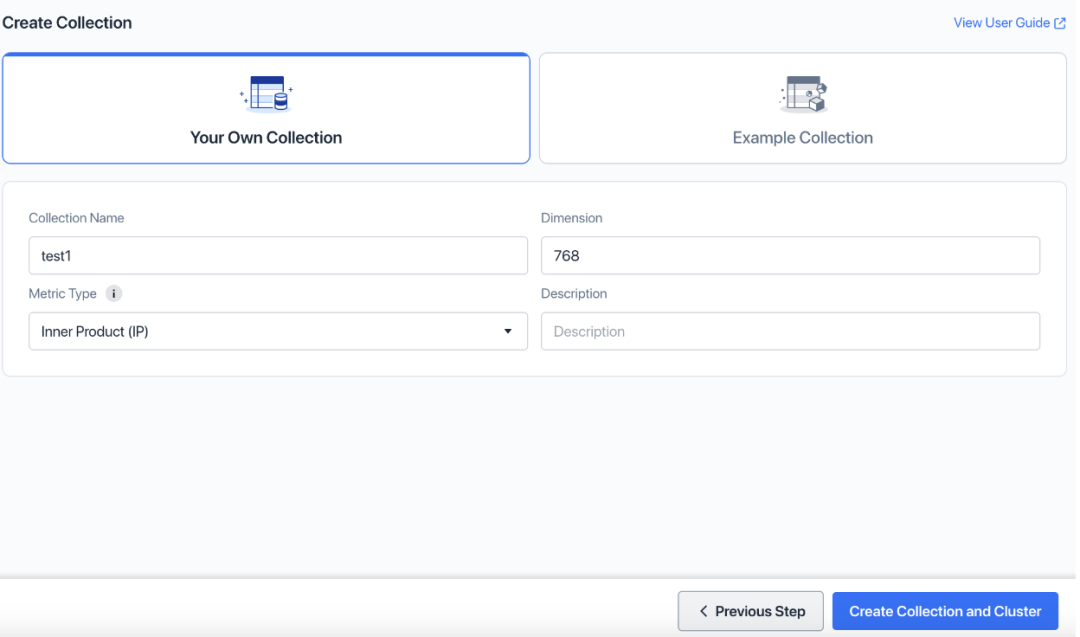
默认情况下,创建 Zilliz Cloud 集群时会同时创建 1 个 Collection,本教程中不会使用它。后面我们创建 Zilliz Cloud Pipelines 时,会自动创建另一个 Collection。请注意,这两个 Collection 不相同。
-
在左侧导航栏中点击 Piplines,跟随界面提示创建 Pipelines 并上传数据:
a. 请先选择创建“Ingestion Pipeline”。
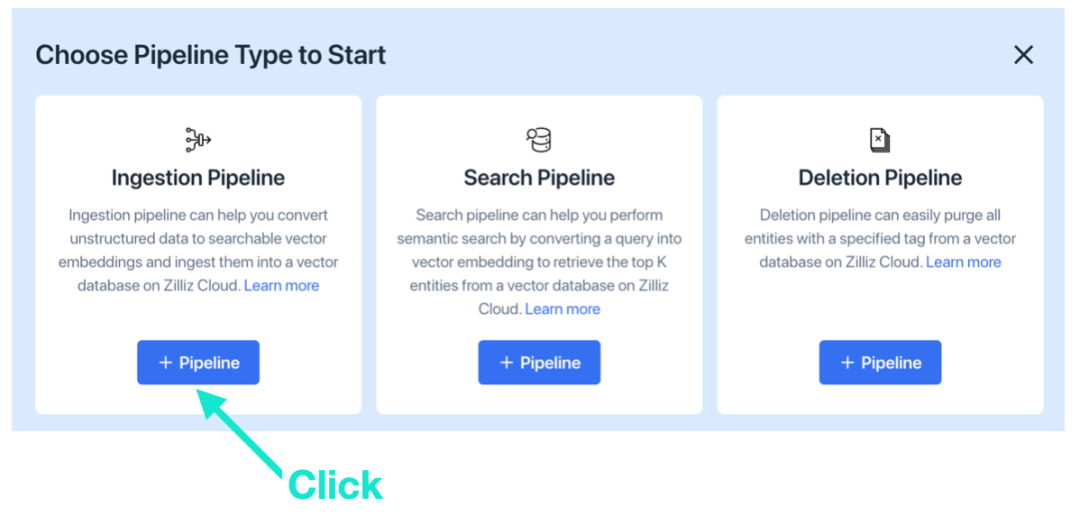
b. 选择刚刚创建的 Serverless 集群,分别输入 Collection 和 Pipeline 名称,点击“添加 function”。
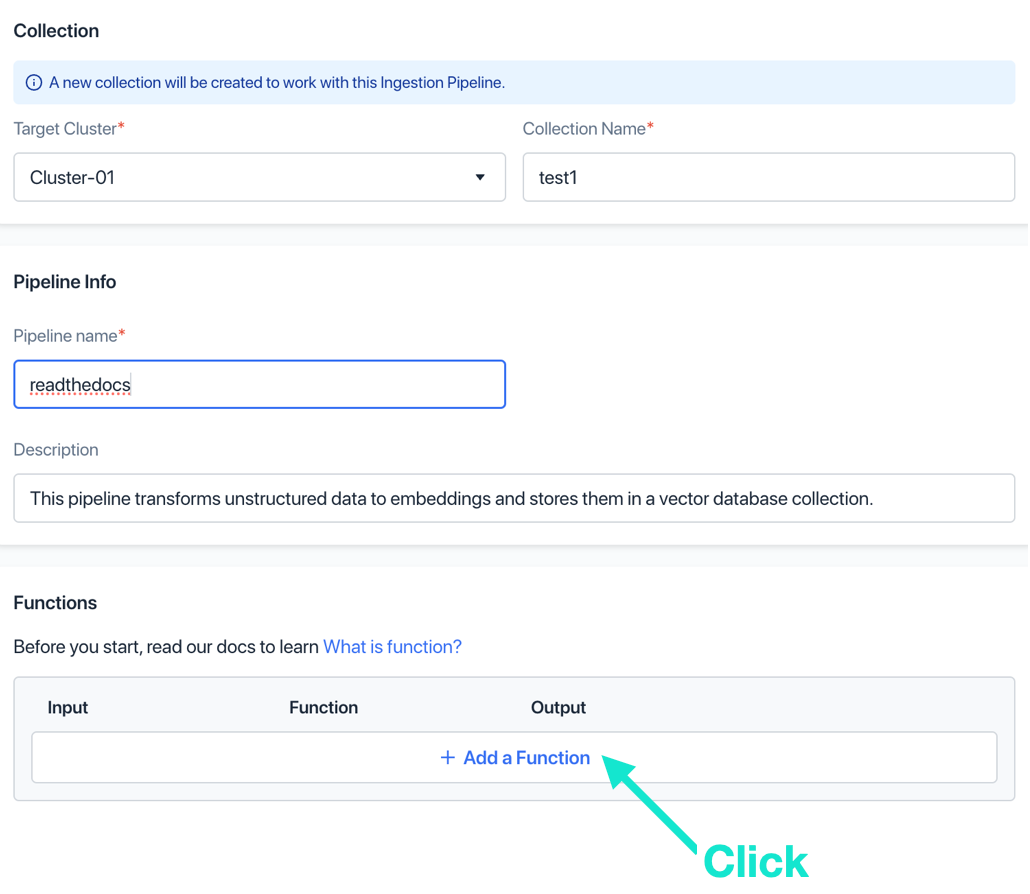
c. 选择INDEX_DOC function,输入function名称,其他参数值保留默认即可,点击“添加”。这个function会将文档切片生成向量。
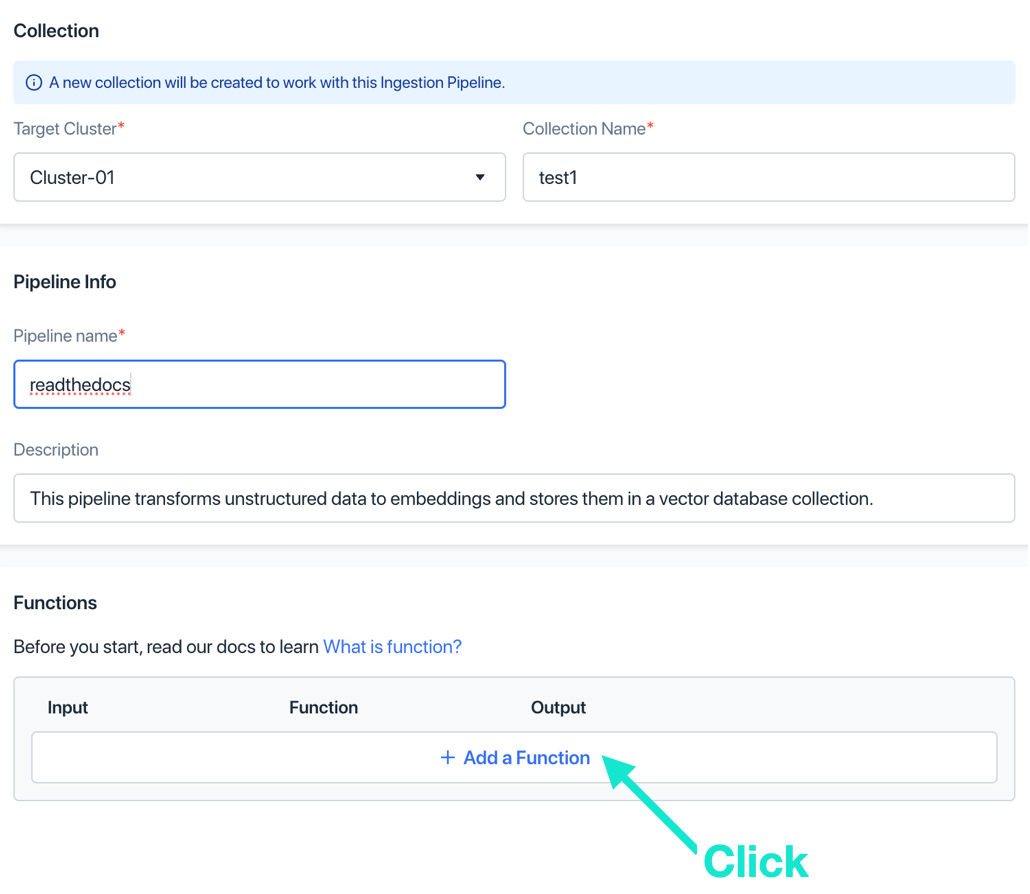
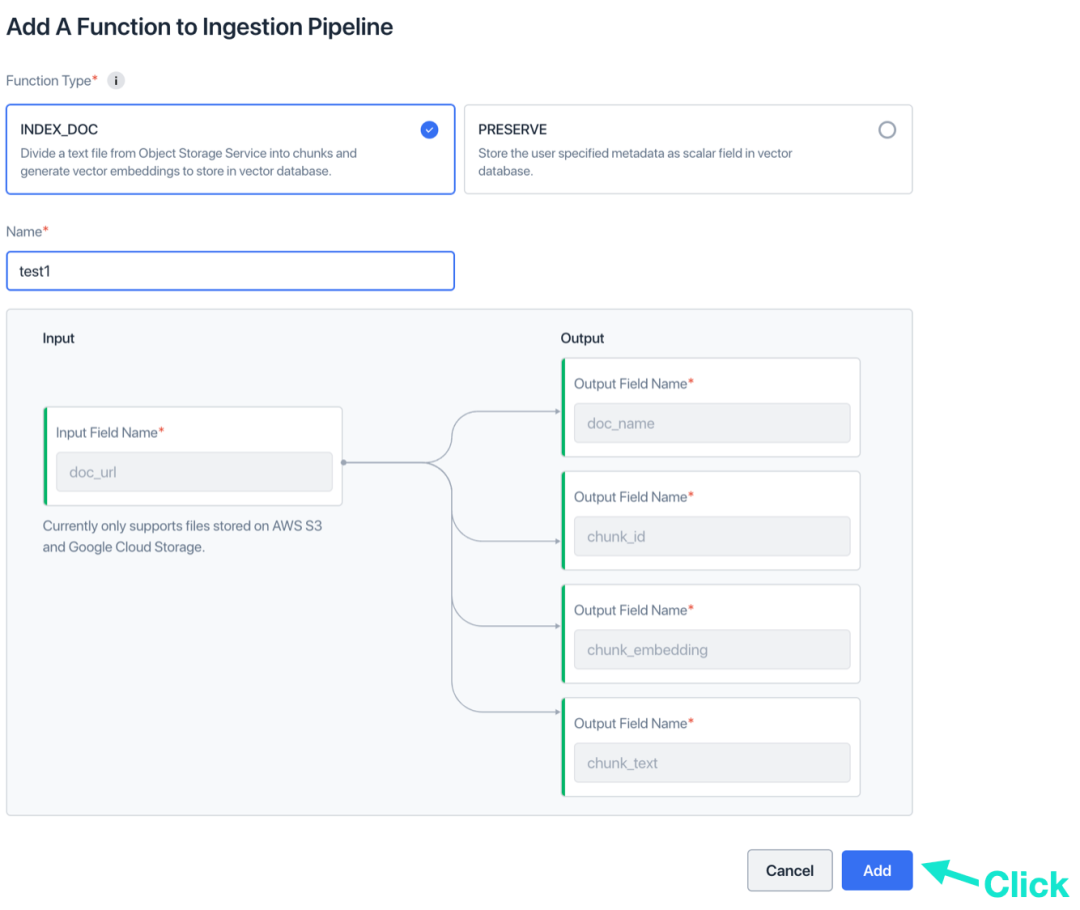
d. (可选)再次点击“添加 function”。
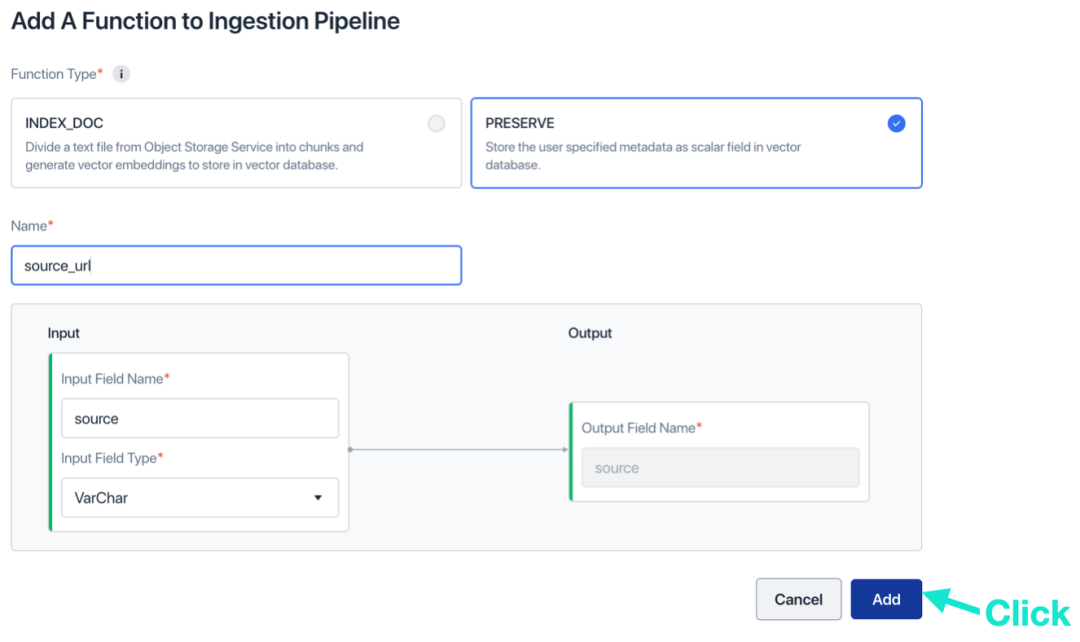
e. (可选)选择 PRESERVE function,并为其命名,点击“添加”。这个 function 用来保存文档的标签信息。
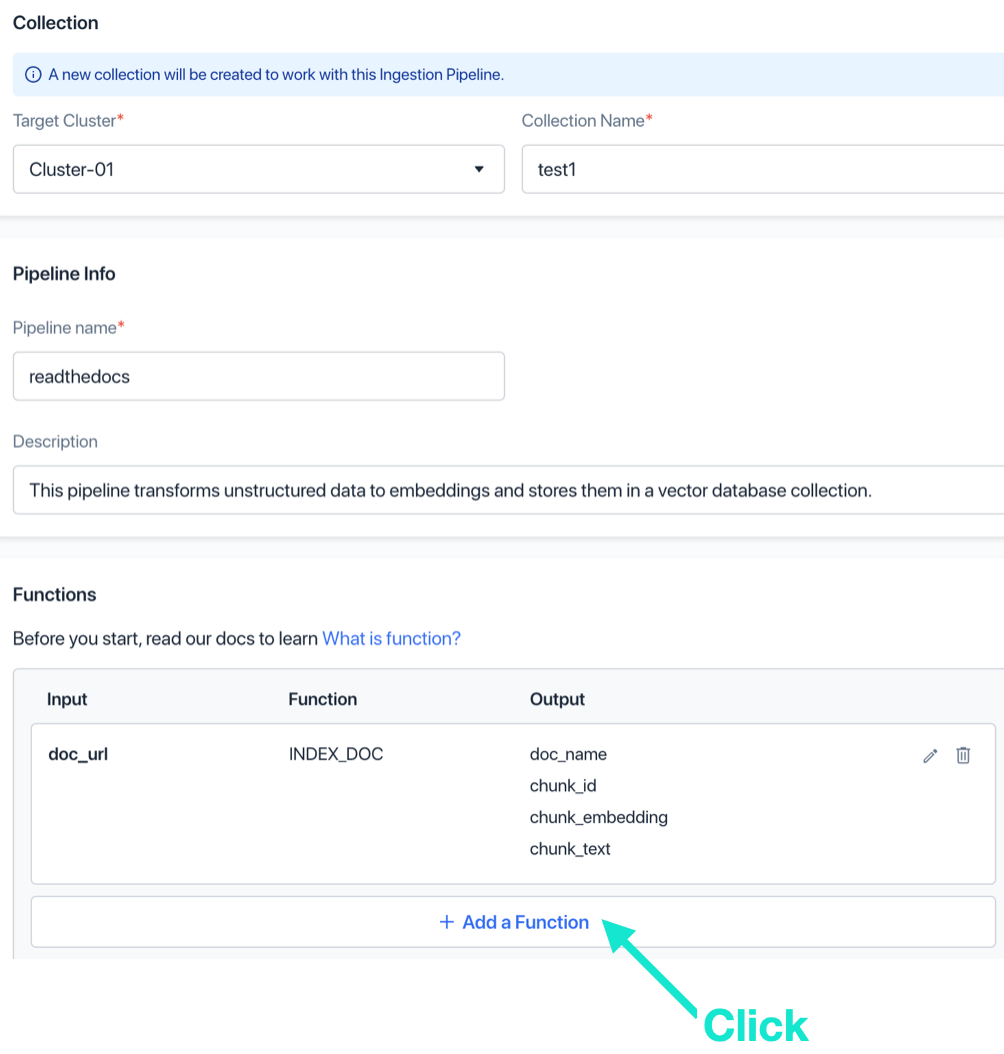
-
点击“创建 Ingestion Pipeline”。现在,我们已经完成创建 Ingestion Pipeline 和 Collection。
-
点击“创建 Deletion 和 Search Pipeline”。
-
进入 Pipelines 列表页面,点击按钮“▶️”运行 Ingestion Pipeline。
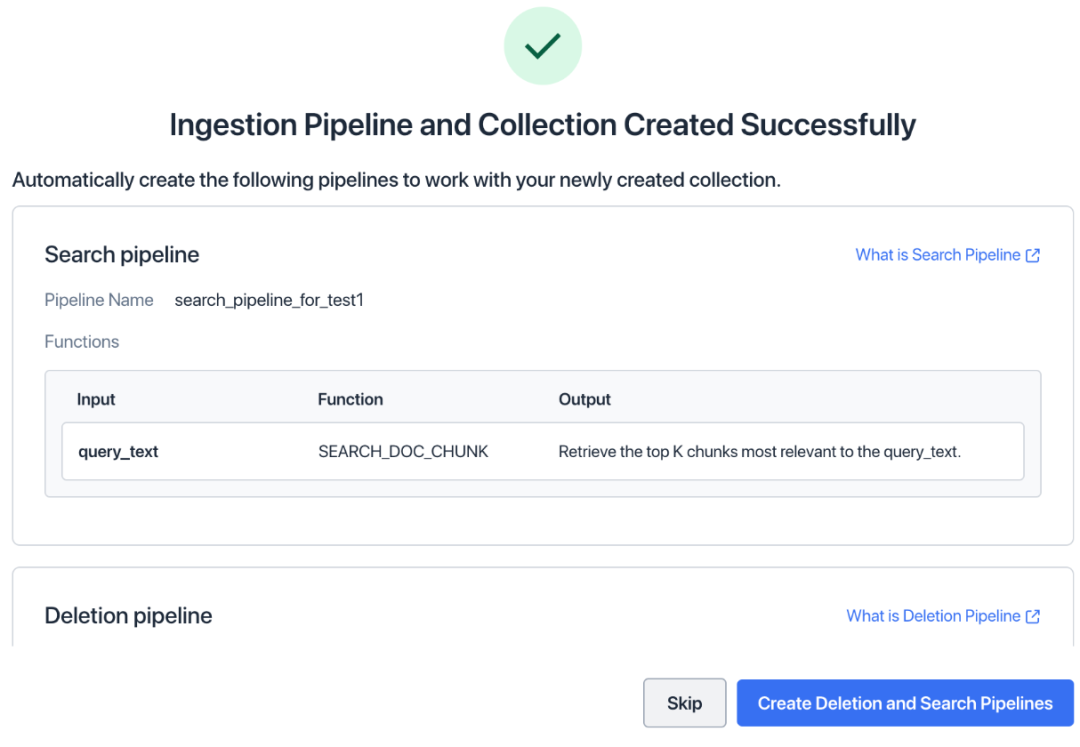
-
Ingestion Pipeline支持上传您在对象存储上的文件(例如AWS S3 和 Google Cloud Storage)。本例中我们将数据上传至 AWS S3。上传完成后,点击“通过 Pre-signed-URL 分享”。复制分享链接(Pre-signed URL)。如果没有对象存储,可以使用我们提供的测试文件链接 https://publicdataset.zillizcloud.com/milvus_doc.md 当作Pre-signed URL。
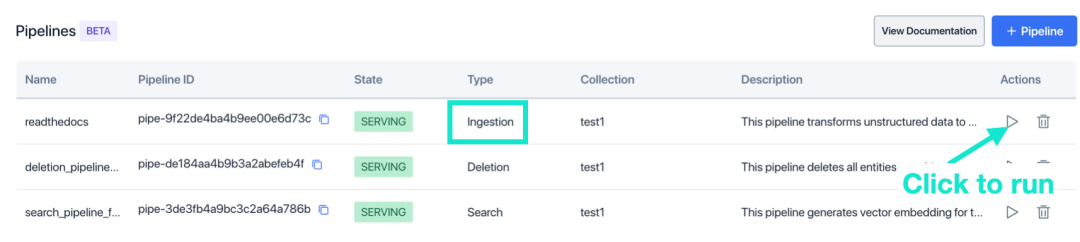
-
在代码中粘贴Pre-signed URL 并点击运行。这步会将文件进行分片提取向量并导入到向量数据库 Collection 中。
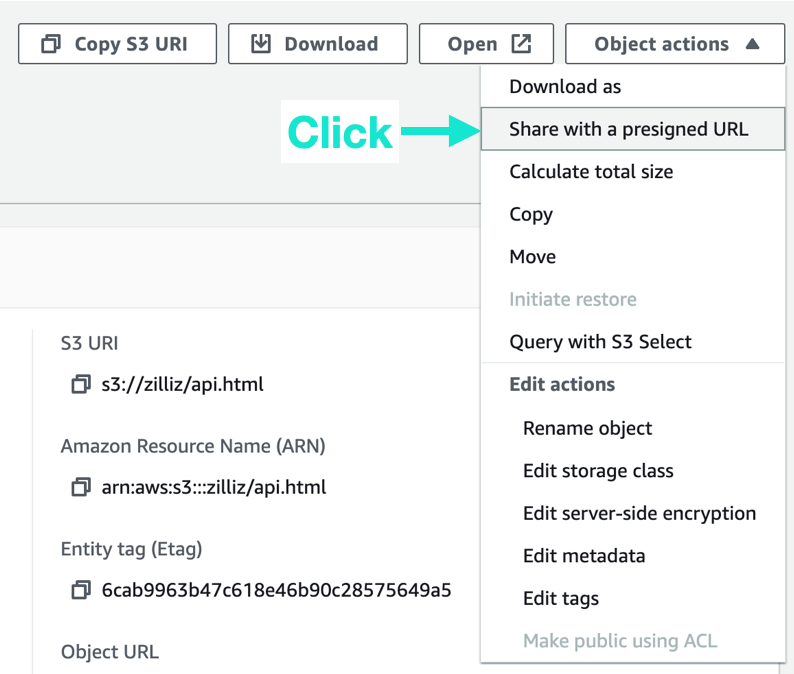
-
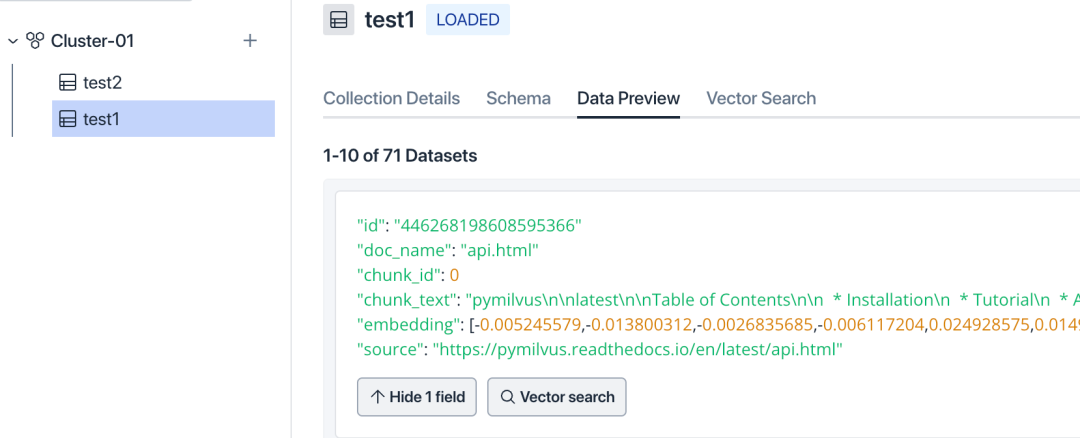
进入collection页面,检查 Collection 和 Schema 是否正确。此时文档片段的向量应该已经显示在Data Preview中了。
之后,可以在 Playground 界面上或者通过调用 API 来查询数据。
02. 用标量过滤召回符合特定标签的向量
-
在 Pipeline 列表中找到 “Search Pipeline”并点击右侧的按钮“▶️”运行 Search Pipeline。
-
在请求中,输入一个问题并点击“运行”。
-
编辑“过滤条件”。请使用布尔表达式。点击运行后,可以看到 Zilliz Cloud 已经根据您输入的条件过滤了搜索结果。
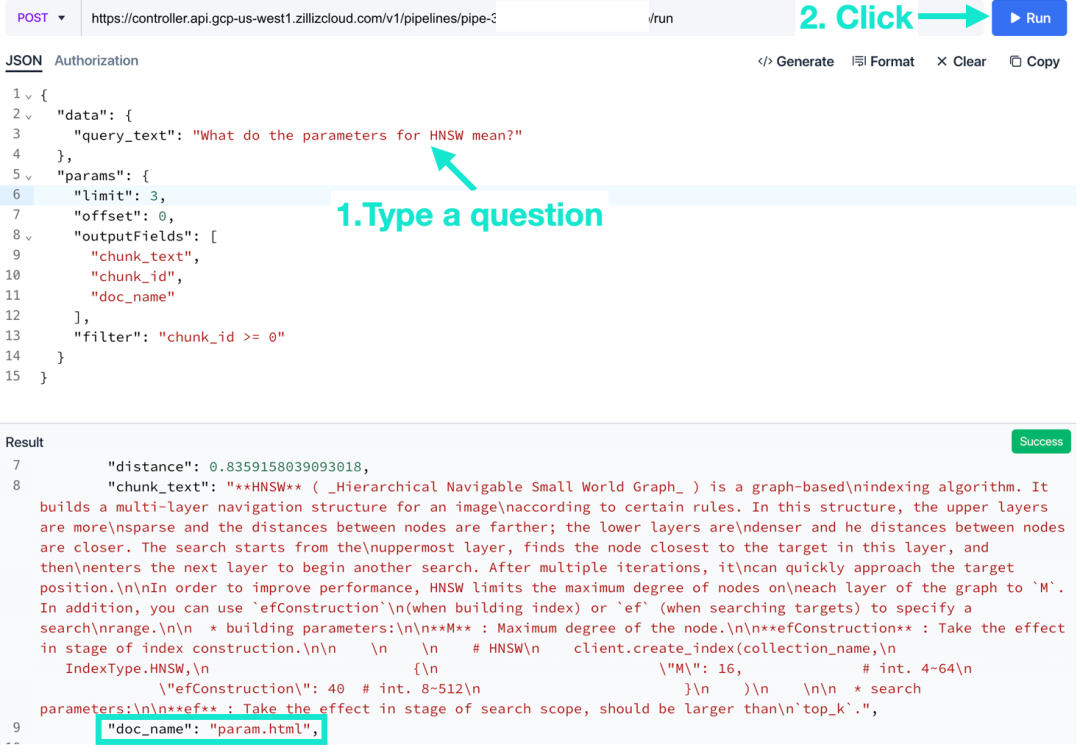
用 Zilliz Cloud Pipelines 进行元数据过滤就是这么简单!你可以通过布尔表达式针对除向量字段以外的所有标量字段进行条件过滤。
03. 通过 API 接口进行搜索
同样,我们也可以通过调用 API 接口来进行搜索,使用 API 过程中,用户需要提供以下两点:
-
Zilliz API Token
-
Pipeline ID
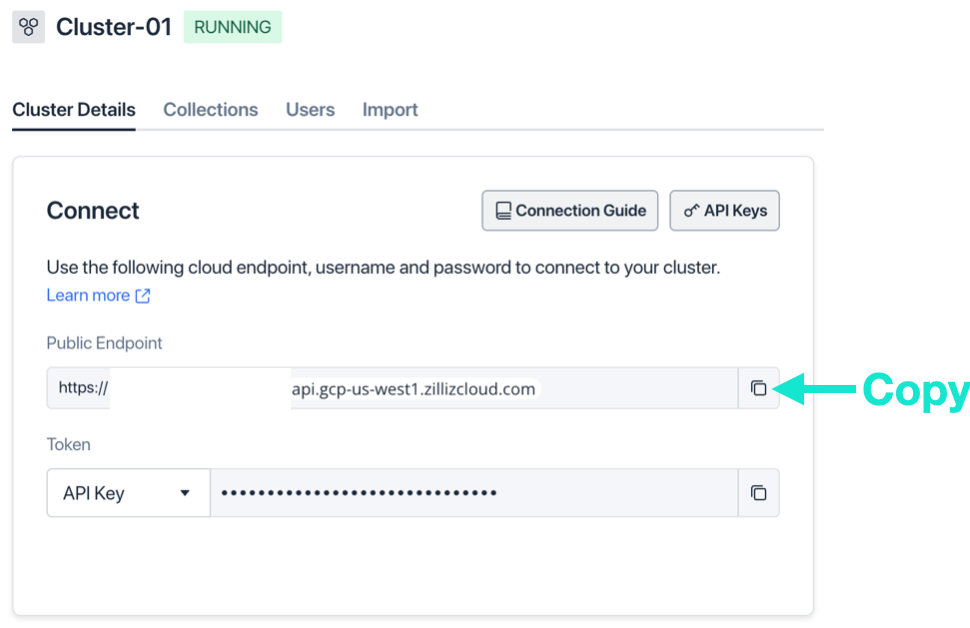
我们可以通过集群详情页获取 API Token。
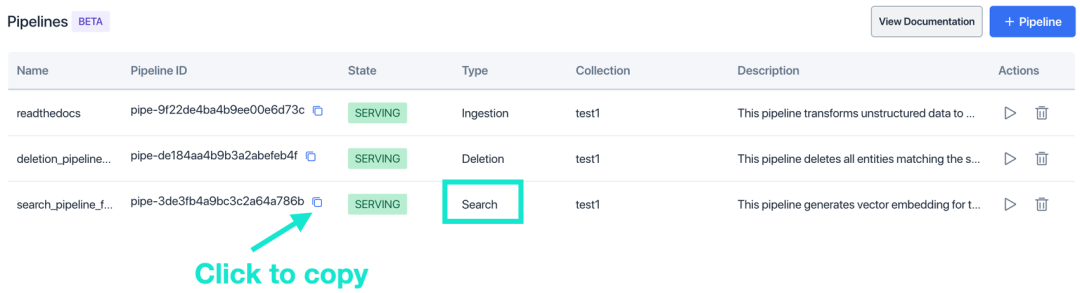
如需获取 Pipeline ID,请先在 Pipelines 列表页找到 Search Pipeline,随后在 Pipeline ID 一栏中复制该 Pipelines 的ID。在调用 API 接口时将 Pipeline ID 粘贴到 URL 中。
import requests, json
url = "https://controller.api.gcp-us-west1.zillizcloud.com/v1/pipelines/pipe-xxxx/run"
headers = {"Content-Type": "application/json","Authorization": f"Bearer {TOKEN}",
}
data = {"data": {"query_text": SAMPLE_QUESTION},"params": {"limit": TOP_K,"offset": 0,# Any of these fields can be used in filter expression."outputFields": ["chunk_text", "chunk_id", "doc_name", "source"],"filter": "doc_name == 'param.html'"}
}# Send the POST request
response = requests.post(url, headers=headers, json=data)
用 API 进行元数据过滤搜索就是这么简单!如果大家有兴趣了解更多 Zilliz Cloud Pipelines 的使用方法,可以参考 Notebook用 Pipelines 搭建一个有标签过滤功能的 RAG 问答机器人,欢迎上手尝试。
本文由 mdnice 多平台发布