【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(3)-训练yolov5模型(本地)
训练yolov5模型(本地)
- 训练文件 train.py
- 训练如下图
- 一些参数的设置
- weights:
- 对于weight参数,可以往Default参数中填入的参数有
- cfg:(缩写)
- cfg参数可以选择的网络模型
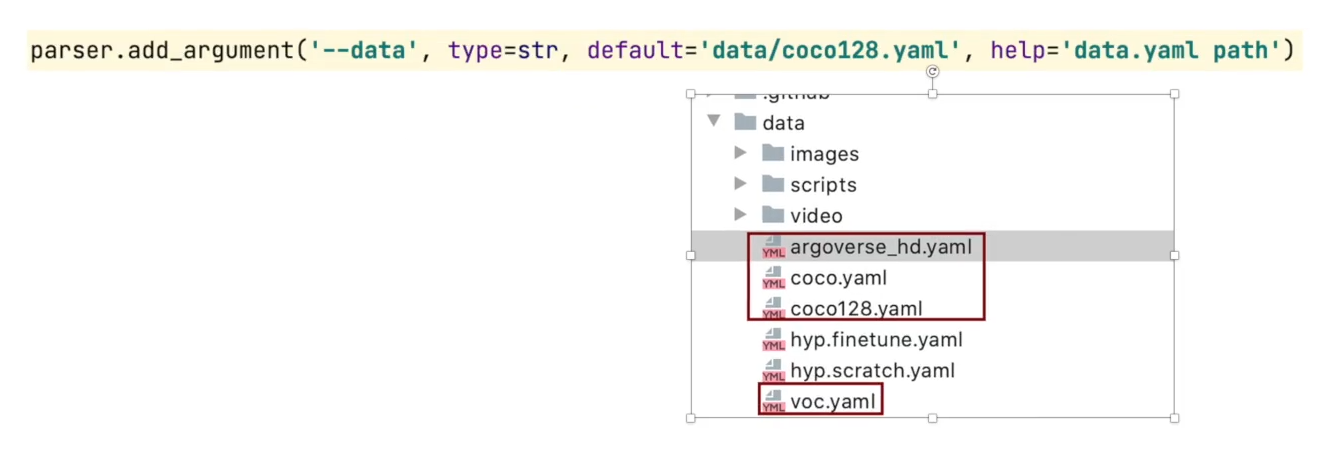
- data
- 对于data
- hyp 超参数
- epochs 训练多少轮
- batch-size 把多少数据打包成一个batch,送到网络当中
- img-size
- rect:矩阵的训练方式
- resume
- nosave
- notest
- noautoanchor 锚点
- evolve
- bucket
- cache-image
- image-weight
- device
- multi-scale
- single-cls
- adam 优化器
- sync-bn
- local_rank
- project
- entity
- name
- exist-ok
- quad
- linear-lr
- Label-smoothing
- save-period
训练文件 train.py
往下翻,找到main函数

这里的works最好设置为0

运行如图,下载coco数据集中
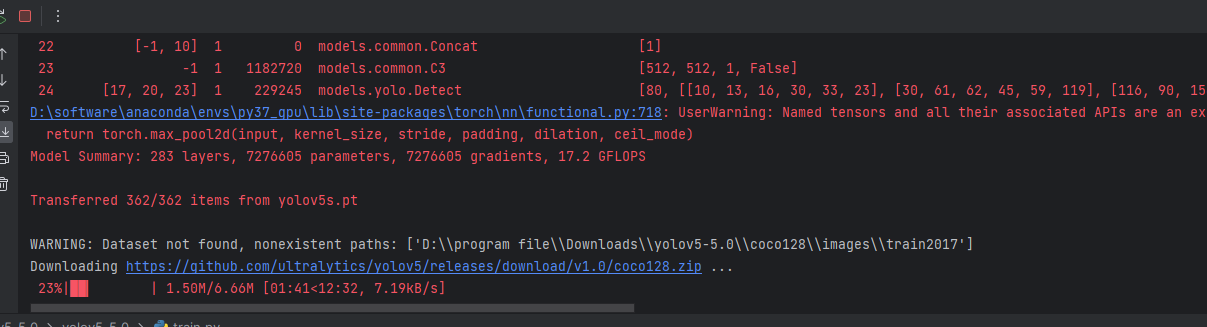

超参数:学习速率等各种参数
库:显示权重
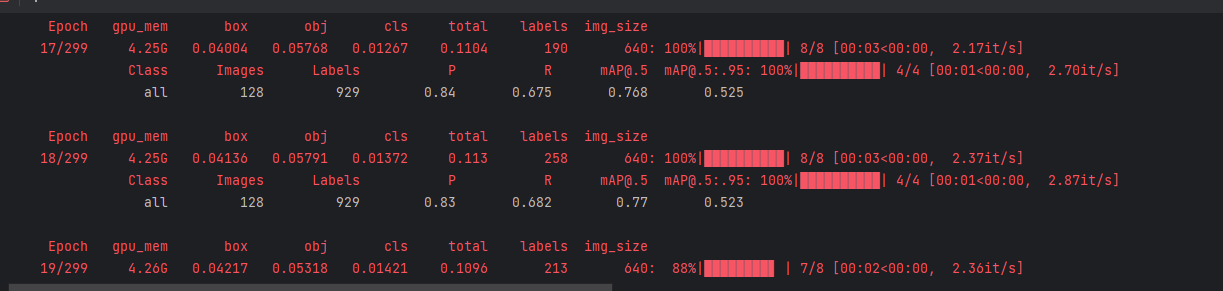
训练如下图
出现数据集下载的问题可以参考下面的解决方法
Dataset autodownload failure
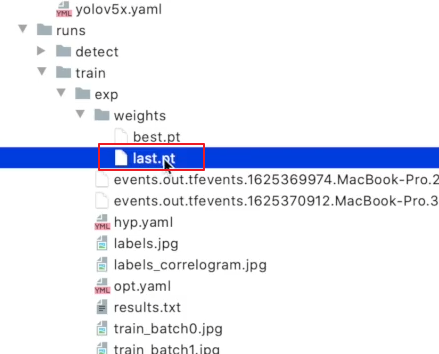
训练文件保存的目录

如果没有发现该文件夹可以进行刷新
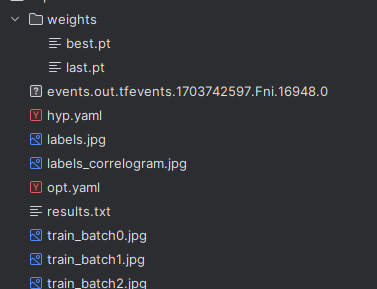
best.pt :在哪个训练轮数当中最好效果的网络模型参数
last.pt:最后一个训练的网络模型
hyp.yaml :训练过程中对模型的一些超参数
labels.jpg:标注的分布
labels_correlogram:标注的一些相关矩阵
opt.yaml:在训练过程中对参数的一些设置
results.txt:对训练结果的一些记录
tran_batch0.jpg:训练的一些图片
一些参数的设置
weights:
指定训练好模型的路径,用该模型去初始化网络中的一些参数(自动去下载这些模型),如果我自己拥有一个训练好的模型,放在某一个路径,把这个路径放进来,就会用我训练好的模型作为训练过程中模型的参数初始化。
但是我们现在的训练一般是从头开始训练,所以这里默认为空,采用程序对参数的权重对它初始化,不采用训练好的模型对他初始化

对于weight参数,可以往Default参数中填入的参数有

cfg:(缩写)
关于模型的一些配置,一般都存在model里面,

整个yolov55总共可以分为4个模型,
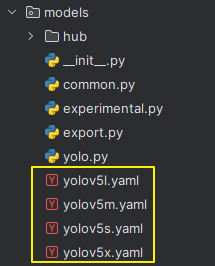
里面都是模型参数的一些设置
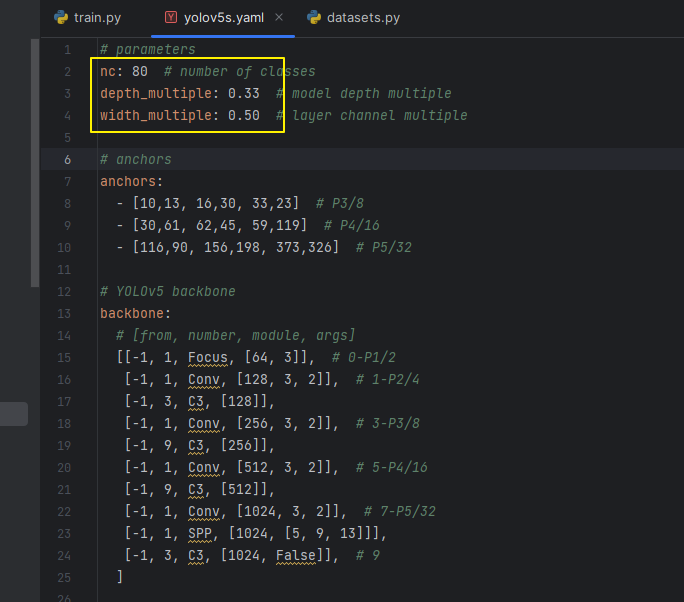
nc:模型应该分为多少个类
depth_multiple:模型的一些深度
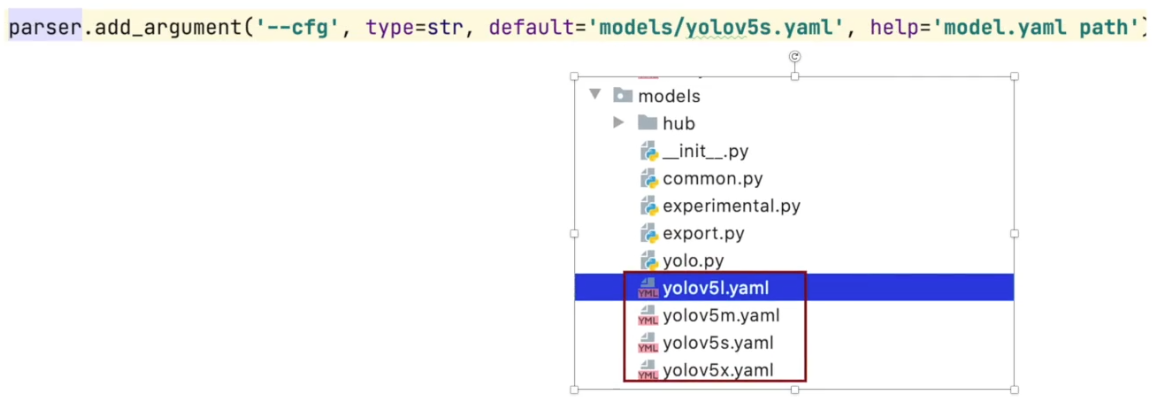
如果选择小模型复制路径填入default
修改之后的代码为

我们现在来训练模型,这个模型的结构是yolov5s,其中的一些模型初始化的参数采用程序之中的简单初始化,不用其他已经训练好的模型来指定参数初始化
cfg参数可以选择的网络模型
data
指定训练数据集

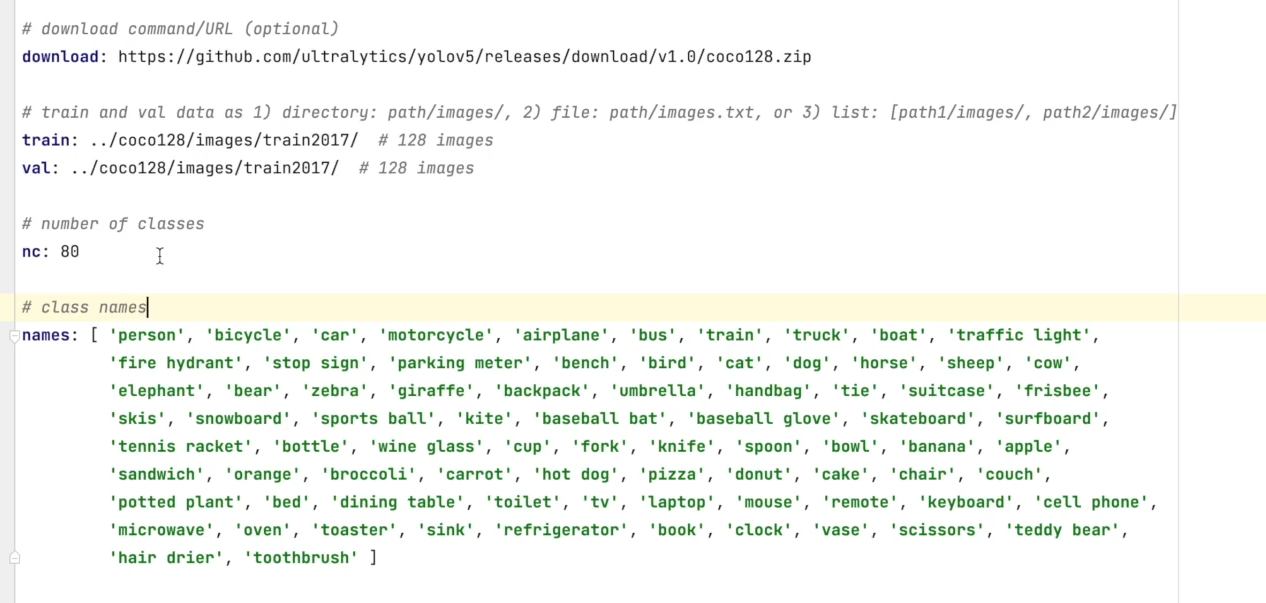
download :指定从哪里下载数据集,没法下载就从浏览器复制地址粘贴下载
train:指定coco数据集应该下载到什么地方
nc:总共有多少个类别
names:每个类别的名称是什么
0 类别代表人
对于data
hyp 超参数

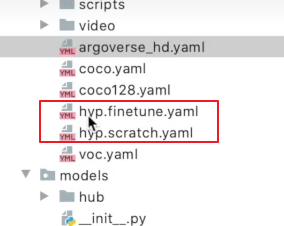
scratch 从头开始,一般把这个文件作为从头开始训练的文件
finetune:用于对模型进行一个微调
epochs 训练多少轮
默认300轮

batch-size 把多少数据打包成一个batch,送到网络当中

img-size
去分别设置训练集,和数列集的大小
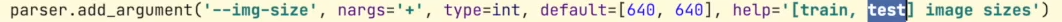
5s对应640
rect:矩阵的训练方式


加速模型。减少不必要信息
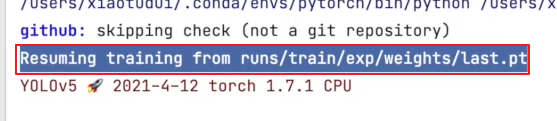
resume
从最近训练的一个模型当中在它的基础上进行一个训练

默认是false,但并不是设置为ture就是能运行的,需要指定在哪一个模型的基础上进行一个继续的训练,需要告诉它模型处在什么地方,所以default 后应该设置为模型的位置
需要指定之前训练的模型文件,因为需要读取模型文件和相应的配置

运行就是从该模型停止的地方继续

nosave
我们在一个模型上训练很多次,如果设置为true,就生效了,只保存最后一次epoch训练的模型的一些权重数据,保存为pt文件
notest
是否只对最后一个epoch进行测试,按理说是对每个epoch上进行测试

noautoanchor 锚点
在目标检测算法中,大致可以分为有锚点的模型和没有锚点的模型
这里建议去查一下锚点锚框的相关知识
以前要是在图片中检测目标的话,要在图片上进行一个遍历,比如滑动窗口。现在都采用锚点的方式。

指定参数就会把锚点取消,默认是开启的
evolve

默认开启,对参数进行进化,寻找最优参数的方式
如果不明白参数是什么意思,可以去百度复制一下询问
bucket
作者之前把一些东西放在谷歌云盘上了,通过这个可以直接下载

cache-image

是否把图片缓存用于更好的训练
image-weight
从我们上一轮的测试过程中,对于哪些测试图片/测试部分,测试效果不好,在下一轮的训练过程中会对这些图片加一些相关的权重

device
设备

multi-scale
对图片尺寸进行变换

single-cls
训练的数据集是单类别还是多类别

adam 优化器
true选择优化器,false选择随机梯度下降

sync-bn
带DDP字眼的可以不用看了

分布式训练,多cpu
local_rank
DDP参数,不要去改

project
文件默认位置

entity
库,不用管

name
保存的文件名

exist-ok

不设置会存在exp1,2,3,4,5
设置了就存在一个exp里面
quad

按住ctrl+F可以找到的单词在什么位置,看源码
或者在问题里查询
linear-lr
对学习速率进行调整

Label-smoothing
标签平滑

save-period
程序日志
