EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
目录
- EI级 | Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
- 预测效果
- 基本介绍
- 模型描述
- 程序设计
- 参考资料
预测效果
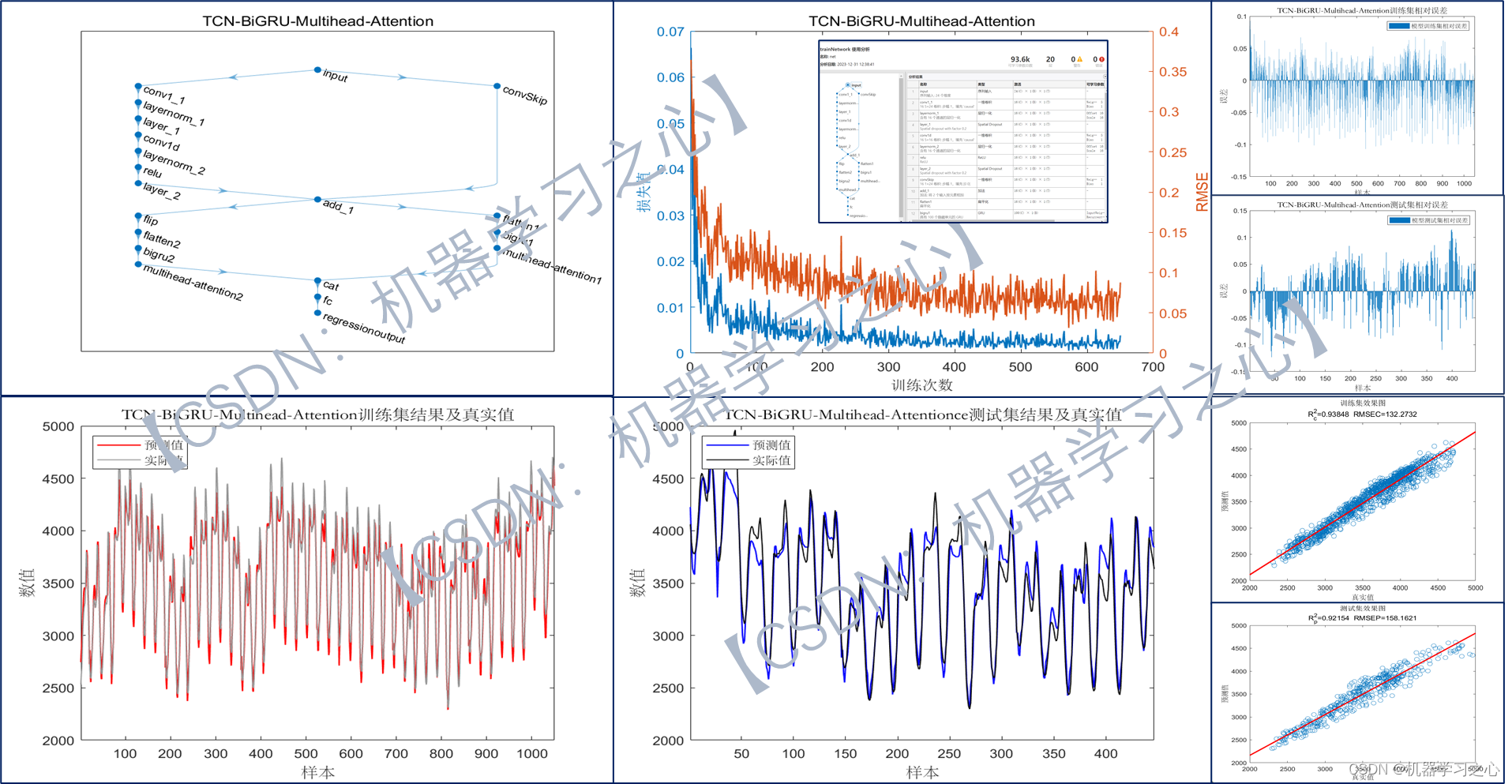

基本介绍
1.【EI级】 Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测;
多头自注意力层 (Multihead-Self-Attention):Multihead-Self-Attention多头注意力机制是一种用于模型关注输入序列中不同位置相关性的机制。它通过计算每个位置与其他位置之间的注意力权重,进而对输入序列进行加权求和。注意力能够帮助模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。在时序预测任务中,注意力机制可以用于对序列中不同时间步之间的相关性进行建模。
2.运行环境为Matlab2023a及以上;
3.data为数据集,输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测,main.m为主程序,运行即可,所有文件放在一个文件夹;
4.命令窗口输出R2、MSE、RMSE、MAE、MAPE、MBE等多指标评价。
模型描述
TCN-BiGRU-Multihead-Attention是一种用于多变量时间序列预测的深度学习模型。该模型结合了Temporal Convolutional Network (TCN)、Bidirectional Gated Recurrent Unit (BiGRU)和Multihead Attention三个组件,以提高模型对时间序列数据的建模能力和预测准确性。
输入层:模型接收多个变量的时间序列作为输入。每个变量的时间序列可以具有不同的特征。
Temporal Convolutional Network (TCN):TCN是一种卷积神经网络结构,用于捕捉时间序列数据中的局部和全局模式。TCN中的卷积层可以跨越不同时间步,从而捕捉长期依赖性。TCN通过多个卷积层和残差连接来构建深度模型,并提供更好的特征提取能力。
Bidirectional Gated Recurrent Unit (BiGRU):BiGRU是一种循环神经网络结构,通过正向和反向两个方向进行时间序列的建模。正向和反向的GRU单元分别记忆和传递时间序列的过去和未来信息,从而更好地捕捉序列中的上下文关系。
Multihead Attention:多头注意力机制用于模型对时间序列数据的重要特征进行自适应加权。它通过将输入序列进行多次映射,每次映射产生一个注意力头。每个注意力头关注不同的时间序列特征,然后将它们的加权表示进行融合,以获得更全面的特征表示。
输出层:最后,模型使用全连接层将多头注意力的输出进行整合,并生成最终的预测结果。预测结果可以是单个时间步的值或者是未来多个时间步的序列。
训练过程中,模型通过最小化预测值与真实标签之间的误差来进行优化,并使用反向传播算法更新模型的参数。为了避免过拟合,可以使用正则化技术如Dropout或L2正则化,并进行交叉验证和早停等操作。
TCN-BiGRU-Multihead-Attention模型通过结合TCN、BiGRU和多头注意力机制,可以更好地建模多变量时间序列数据,并提高时间序列预测的准确性。
程序设计
- 完整程序和数据获取方式:私信博主回复Matlab实现TCN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测获取。
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 相关指标计算
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
% MAPE
maep1 = sum(abs(T_sim1 - T_train)./T_train) ./ M ;
maep2 = sum(abs(T_sim2 - T_test )./T_test) ./ N ;
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
disp(['训练集数据的MAPE为:', num2str(maep1)])
disp(['测试集数据的MAPE为:', num2str(maep2)])
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
% RMSE
RMSE1 = sqrt(sumsqr(T_sim1 - T_train)/M);
RMSE2 = sqrt(sumsqr(T_sim2 - T_test)/N);
%-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
disp(['训练集数据的RMSE为:', num2str(RMSE1)])
disp(['测试集数据的RMSE为:', num2str(RMSE2)])参考资料
[1] http://t.csdn.cn/pCWSp
[2] https://download.csdn.net/download/kjm13182345320/87568090?spm=1001.2014.3001.5501
[3] https://blog.csdn.net/kjm13182345320/article/details/129433463?spm=1001.2014.3001.5501