大模型系列:OpenAI使用技巧_使用OpenAI进行K-means聚类
文章目录
- 1. 使用K-means算法找到聚类
- 2. 聚类中的文本样本和聚类的命名让我们展示每个聚类中的随机样本。
我们使用一个简单的k-means算法来演示如何进行聚类。聚类可以帮助发现数据中有价值的隐藏分组。数据集是在 Get_embeddings_from_dataset Notebook中创建的。
# 导入必要的库
import numpy as np
import pandas as pd
from ast import literal_eval# 数据文件路径
datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"# 读取csv文件为DataFrame格式
df = pd.read_csv(datafile_path)# 将embedding列中的字符串转换为numpy数组
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)# 将所有的embedding数组按行堆叠成一个矩阵
matrix = np.vstack(df.embedding.values)# 输出矩阵的形状
matrix.shape
(1000, 1536)
1. 使用K-means算法找到聚类
我们展示了K-means的最简单用法。您可以选择最适合您用例的聚类数量。
# 导入KMeans聚类算法
from sklearn.cluster import KMeans# 设置聚类数目
n_clusters = 4# 初始化KMeans算法,设置聚类数目、初始化方法和随机种子
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)# 使用KMeans算法对数据进行聚类
kmeans.fit(matrix)# 获取聚类标签
labels = kmeans.labels_# 将聚类标签添加到数据框中
df["Cluster"] = labels# 按照聚类标签对数据框进行分组,计算每个聚类的平均分数,并按照平均分数排序
df.groupby("Cluster").Score.mean().sort_values()
/Users/ted/.virtualenvs/openai/lib/python3.9/site-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warningwarnings.warn(Cluster
0 4.105691
1 4.191176
2 4.215613
3 4.306590
Name: Score, dtype: float64
# 导入必要的库
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt# 初始化t-SNE模型,设置参数
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)# 使用t-SNE模型对数据进行降维
vis_dims2 = tsne.fit_transform(matrix)# 提取降维后的数据的x和y坐标
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]# 针对每个类别,绘制散点图,并标记类别的平均值
for category, color in enumerate(["purple", "green", "red", "blue"]):# 提取属于当前类别的数据的x和y坐标xs = np.array(x)[df.Cluster == category]ys = np.array(y)[df.Cluster == category]# 绘制散点图plt.scatter(xs, ys, color=color, alpha=0.3)# 计算当前类别的平均值avg_x = xs.mean()avg_y = ys.mean()# 标记平均值plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)# 设置图表标题
plt.title("Clusters identified visualized in language 2d using t-SNE")
Text(0.5, 1.0, 'Clusters identified visualized in language 2d using t-SNE')
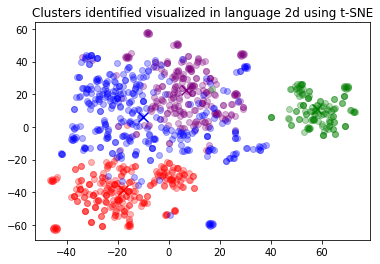
在二维投影中对聚类进行可视化。在这次运行中,绿色聚类(#1)似乎与其他聚类非常不同。让我们看一下每个聚类的几个样本。
2. 聚类中的文本样本和聚类的命名让我们展示每个聚类中的随机样本。
我们将使用text-davinci-003来为聚类命名,基于从该聚类中随机抽取的5个评论样本。
# 导入openai模块import openai# 每个聚类组中的评论数量
rev_per_cluster = 5# 遍历每个聚类组
for i in range(n_clusters):# 输出聚类组的主题print(f"Cluster {i} Theme:", end=" ")# 选取属于该聚类组的评论,并将它们合并成一个字符串reviews = "\n".join(df[df.Cluster == i].combined.str.replace("Title: ", "").str.replace("\n\nContent: ", ": ").sample(rev_per_cluster, random_state=42).values)# 使用openai模块对选取的评论进行主题分析response = openai.Completion.create(engine="text-davinci-003",prompt=f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',temperature=0,max_tokens=64,top_p=1,frequency_penalty=0,presence_penalty=0,)# 输出主题分析结果print(response["choices"][0]["text"].replace("\n", ""))# 选取属于该聚类组的样本行,并输出它们的得分、摘要和文本内容sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state=42)for j in range(rev_per_cluster):print(sample_cluster_rows.Score.values[j], end=", ")print(sample_cluster_rows.Summary.values[j], end=": ")print(sample_cluster_rows.Text.str[:70].values[j])# 输出分隔符print("-" * 100)
Cluster 0 Theme: All of the reviews are positive and the customers are satisfied with the product they purchased.
5, Loved these gluten free healthy bars, saved $$ ordering on Amazon: These Kind Bars are so good and healthy & gluten free. My daughter ca
1, Should advertise coconut as an ingredient more prominently: First, these should be called Mac - Coconut bars, as Coconut is the #2
5, very good!!: just like the runts<br />great flavor, def worth getting<br />I even o
5, Excellent product: After scouring every store in town for orange peels and not finding an
5, delicious: Gummi Frogs have been my favourite candy that I have ever tried. of co
----------------------------------------------------------------------------------------------------
Cluster 1 Theme: All of the reviews are about pet food.
2, Messy and apparently undelicious: My cat is not a huge fan. Sure, she'll lap up the gravy, but leaves th
4, The cats like it: My 7 cats like this food but it is a little yucky for the human. Piece
5, cant get enough of it!!!: Our lil shih tzu puppy cannot get enough of it. Everytime she sees the
1, Food Caused Illness: I switched my cats over from the Blue Buffalo Wildnerness Food to this
5, My furbabies LOVE these!: Shake the container and they come running. Even my boy cat, who isn't
----------------------------------------------------------------------------------------------------
Cluster 2 Theme: All of the reviews are positive and express satisfaction with the product.
5, Fog Chaser Coffee: This coffee has a full body and a rich taste. The price is far below t
5, Excellent taste: This is to me a great coffee, once you try it you will enjoy it, this
4, Good, but not Wolfgang Puck good: Honestly, I have to admit that I expected a little better. That's not
5, Just My Kind of Coffee: Coffee Masters Hazelnut coffee used to be carried in a local coffee/pa
5, Rodeo Drive is Crazy Good Coffee!: Rodeo Drive is my absolute favorite and I'm ready to order more! That
----------------------------------------------------------------------------------------------------
Cluster 3 Theme: All of the reviews are about food or drink products.
5, Wonderful alternative to soda pop: This is a wonderful alternative to soda pop. It's carbonated for thos
5, So convenient, for so little!: I needed two vanilla beans for the Love Goddess cake that my husbands
2, bot very cheesy: Got this about a month ago.first of all it smells horrible...it tastes
5, Delicious!: I am not a huge beer lover. I do enjoy an occasional Blue Moon (all o
3, Just ok: I bought this brand because it was all they had at Ranch 99 near us. I
----------------------------------------------------------------------------------------------------
重要的是要注意,聚类不一定与您打算使用它们的目的完全匹配。更多的聚类将关注更具体的模式,而较少的聚类通常会关注数据中最大的差异。