深度强化学习DLR
1 强化学习基础知识
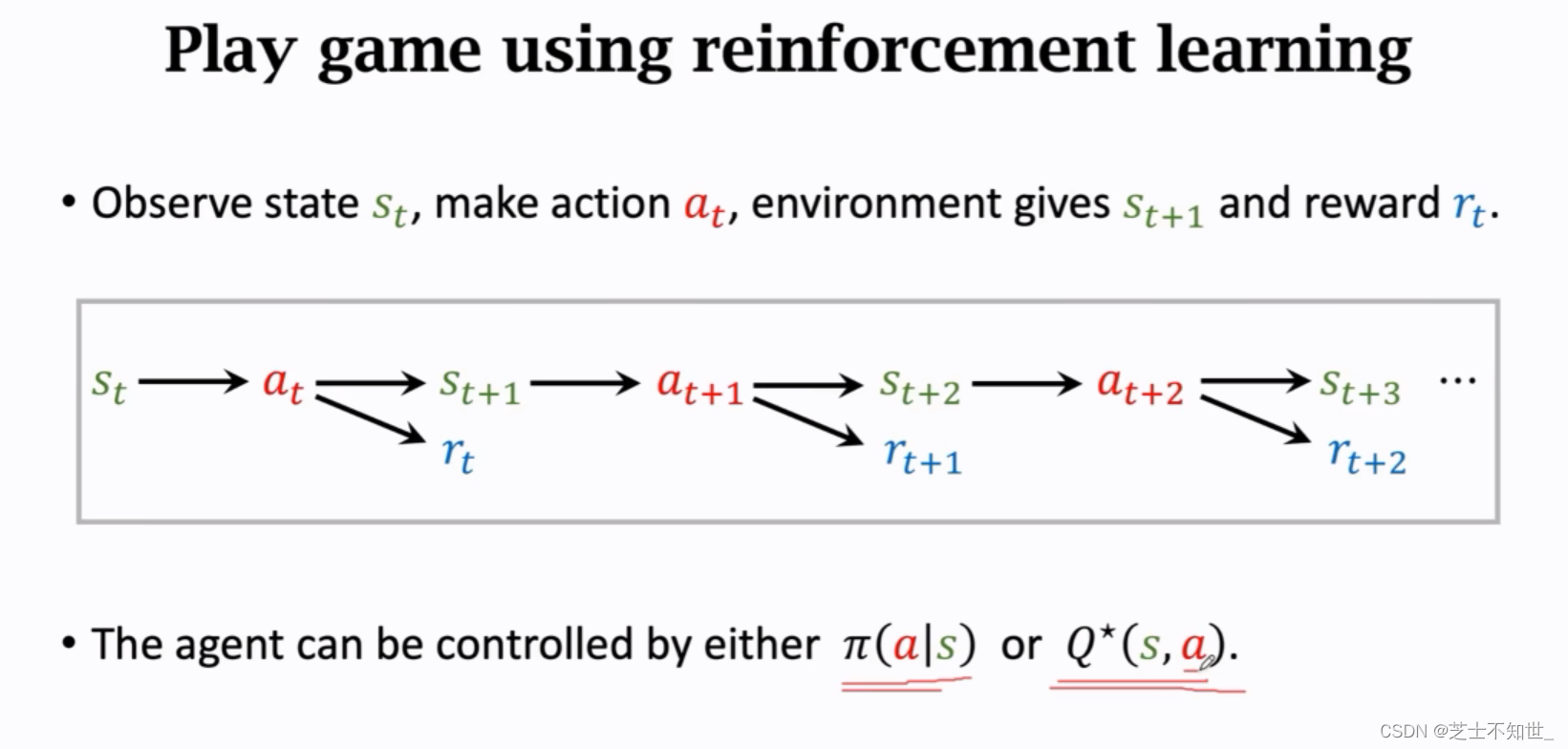
强化学习过程:⾸先环境(Env)会给智能体(Agent)⼀个状态(State),智能体接收到环境给的观测值之后会做出⼀个动作(Action),环境接收到智能体给的动作之后会做出⼀系列的反应,例如对这个动作给予⼀个奖励(Reward),以及给出⼀个新的状态S。这是⼀个反复与环境进⾏交互,不断试错⼜不断进步的过程。
智能体Agent:执行任务的角色。
环境Env:任务的环境。
状态State:角色和环境所处的状态。
动作Action:角色在当前状态下做出的动作。
奖励Reward:环境根据角色的动作给出的反馈。
回报Return:未来奖励Reward的加权累计。
随机策略函数π(a∣s)\pi(a|s)π(a∣s):在状态S下在动作空间随机抽样给出动作a。
动作价值函数Qπ(s∣a)Q_\pi(s|a)Qπ(s∣a):给当前状态S下的动作打分,使用Q∗(s∣a)Q_*(s|a)Q∗(s∣a)得出分数最高的动作a。

强化学习分类:
1.价值学习Q*(s|a):给状态S下各种动作打分,选择价值最大的最优动作a。——Deep Q Network(DQN) 与 Q Learning 与 SARSA
2.策略学习π(a|s):在状态S随机概率抽样给出a。——策略网络Policy Network
3.价值学习+策略学习:Actor-Critic method 与 Advantage Actor-Critic——AC算法 与 A2C算法