Elasticsearch:使用 OpenAI 生成嵌入并进行向量搜索 - nodejs
在我之前的文章:
-
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)(二)(三)(四)
我详细地描述了如何使用 LangChain 及 OpenAI 进行向量搜索及 RAG。在那篇文章中,它没有用户界面。在今天的文章中,我将展示如何使用 OpenAI 来把数据进行向量化(不是使用 Elastic Stack 提供的 eland 上传模型的方式。这种方案是完全免费的),并写入到 Elasticsearch。我们使用 Web UI 来对向量进行搜索。我们可以在如下的地址下载代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们将使用其中的一个例子:
$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/openai-embeddings安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在我下面的练习中,我将使用 Elastic Stack 8.11 来进行展示。
运行应用
在运行之前,我们在自己的 terminal 中打入如下的命令:
export ELASTICSEARCH_URL=https://localhost:9200
export ELASTIC_USERNAME=elastic
export ELASTIC_PASSWORD=o6G_pvRL=8P*7on+o6XH
export OPENAI_API_KEY=YourOpenAIKey
在我的设置中,我使用自签名证书的 Elasticsearch 集群。在上面,你需要根据自己的 Elasticsearch 超级用户及密码进行配置。你也需要在 OpenAI 的网站中申请开发者 key。你可以在地址 https://platform.openai.com/api-keys 进行申请。
另外,我们需要拷贝 Elasticsearch 的证书到当前的目录中:
$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/openai-embeddings
$ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
$ ls
LICENSE http_ca.crt package.json utils.js
README.md images sample_data views
generate_embeddings.js package-lock.json search_app.js如上所示,generate_embeddings.js 这个文件是用来使用 OpenAI 来生产 embeddings 的。关于如何使用证书及签名连接到 Elasticsearch,请参阅之前的文章 “Elasticsearch:使用最新的 Nodejs client 8.x 来创建索引并搜索”。有关如何连接到 Elasticsearch 的部分代码,请参阅上面的 utils.js。
在运动代码之前,我们使用如下的命令来安装相应的包:
npm install$ vi package.json
$ npm installremoved 10 packages, and audited 110 packages in 1s10 packages are looking for fundingrun `npm fund` for detailsfound 0 vulnerabilities我们可以查看当前的 nodejs 版本:
$ node --version
v19.0.1我们也可以查看 openai 的版本:
$ npm list | grep openai
openai-integration-example-javascript@1.0.0 /Users/liuxg/python/elasticsearch-labs/example-apps/openai-embeddings
└── openai@4.20.1在这里需要强调的是 openai 的版本不同,调用的 API 的接口会有区别。
$ npm list | grep elasticsearch
openai-integration-example-javascript@1.0.0 /Users/liuxg/python/elasticsearch-labs/example-apps/openai-embeddings
├── @elastic/elasticsearch@8.8.0生成向量
我们可以查看 package.json 的文档定义:
package.json
{"name": "openai-integration-example-javascript","version": "1.0.0","description": "OpenAI integration example","main": "search_app.js","scripts": {"app": "node search_app.js","generate": "node generate_embeddings.js"},"author": "Elastic","license": "MIT","dependencies": {"@elastic/elasticsearch": "^8.8.0","express": "^4.18.2","hbs": "^4.2.0","openai": "^4.20.1"}
}我们使用如下的命令来生成 embeddings:
npm run generate$ npm run generate> openai-integration-example-javascript@1.0.0 generate
> node generate_embeddings.jsConnecting to Elasticsearch: https://localhost:9200
connection success true
Creating index openai-integration...
Reading from file sample_data/medicare.json
Processing 12 documents...
Processing batch of 10 documents...
docsBatch size: 10
Calling OpenAI API for 10 embeddings with model text-embedding-ada-002
Indexing 10 documents to index openai-integration...
Processing batch of 2 documents...
docsBatch size: 2
Calling OpenAI API for 2 embeddings with model text-embedding-ada-002
Indexing 2 documents to index openai-integration...
Processing complete在运行上面的命令时,一定要在 terminal 中设置上面的变量。在上面,我们可以看到有12个文档已经被摄入到 Elasticsearch 中。它使用的是 OpenAI 的接口来进行向量化的。我们可以使用如下的命令在 Kibana 中进行查看:
GET openai-integration/_search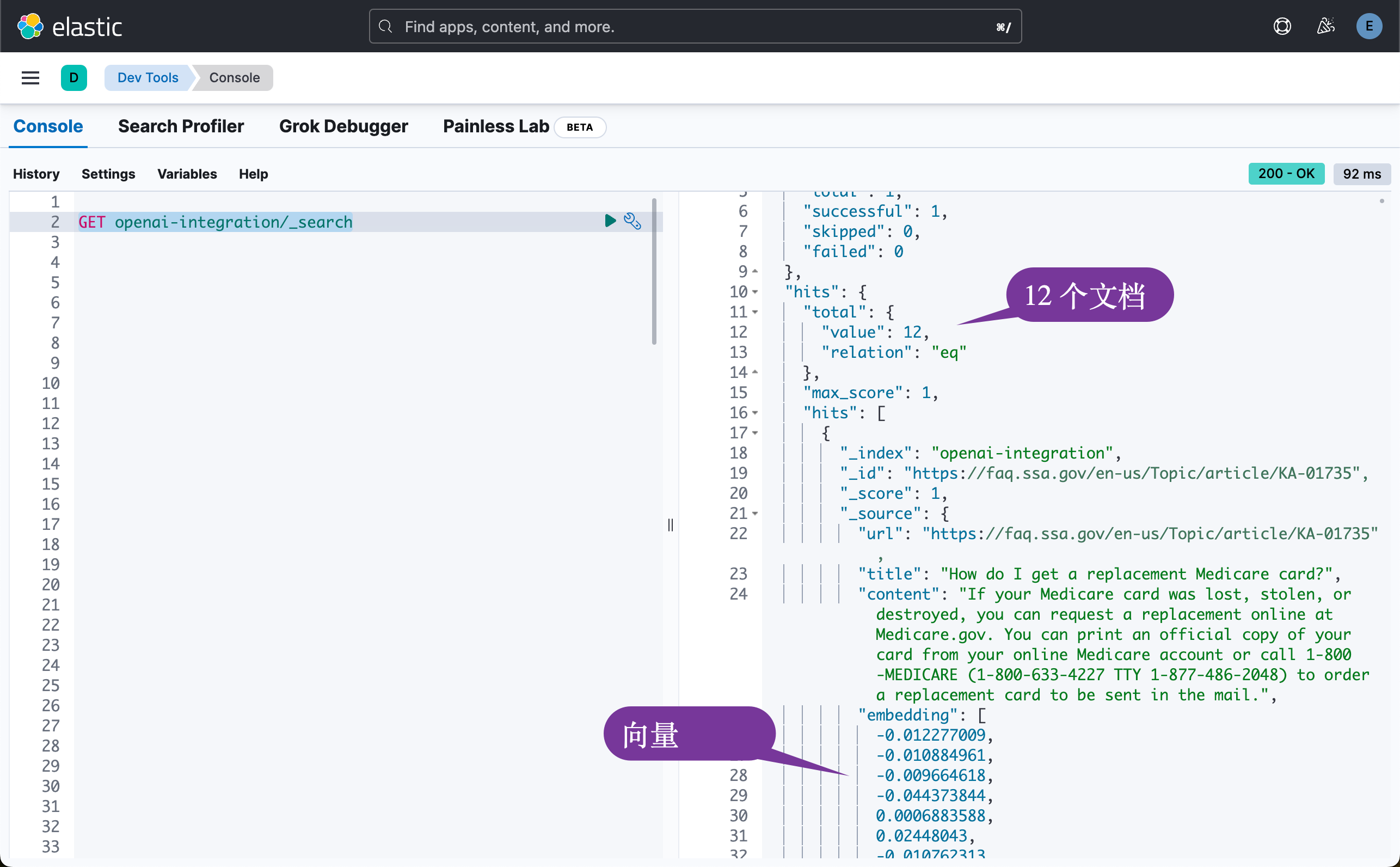
启动 web 应用
我们可以使用如下的命令来启动 web 应用:
npm run app$ npm run app> openai-integration-example-javascript@1.0.0 app
> node search_app.jsConnecting to Elasticsearch: https://localhost:9200
Express app listening on port 3000
connection success true如上所示,我们的 web 应用在 localhost:3000 的端口上运行。我们可以在浏览器中进行打开:
在 web 应用中进行语义搜索
我们的数据结构如下:
{"url": "https://faq.ssa.gov/en-us/Topic/article/KA-01735","title": "How do I get a replacement Medicare card?","content": "If your Medicare card was lost, stolen, or destroyed, you can request a replacement online at Medicare.gov. You can print an official copy of your card from your online Medicare account or call 1-800-MEDICARE (1-800-633-4227 TTY 1-877-486-2048) to order a replacement card to be sent in the mail."},{"url": "https://faq.ssa.gov/en-us/Topic/article/KA-02713","title": "How do I terminate my Medicare Part B (medical insurance)?","content": "You can voluntarily terminate your Medicare Part B (Medical Insurance). However, you may need to have a personal interview with Social Security to review the risks of dropping coverage and to assist you with your request. To find out more about how to terminate Medicare Part B or to schedule a personal interview, contact us at 1-800-772-1213 (TTY: 1-800-325-0778) or visit your nearest Social Security office."},在我们的实现中,我们是针对 content 这个 text 字段进行向量化的,也就是说我们可以针对这个字段进行语义搜索。
我们尝试进行如下的搜索:
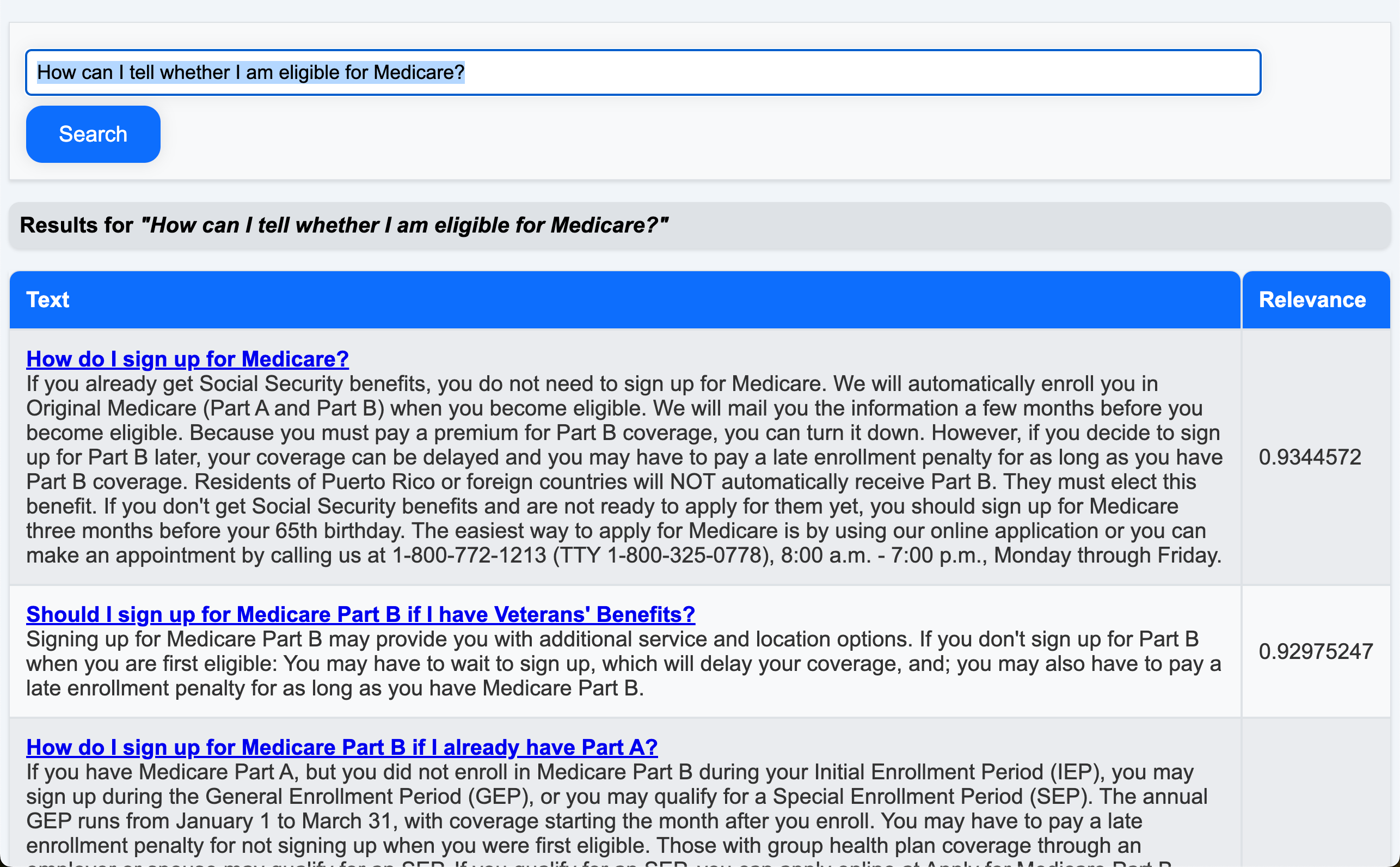
how much does Medicare cost?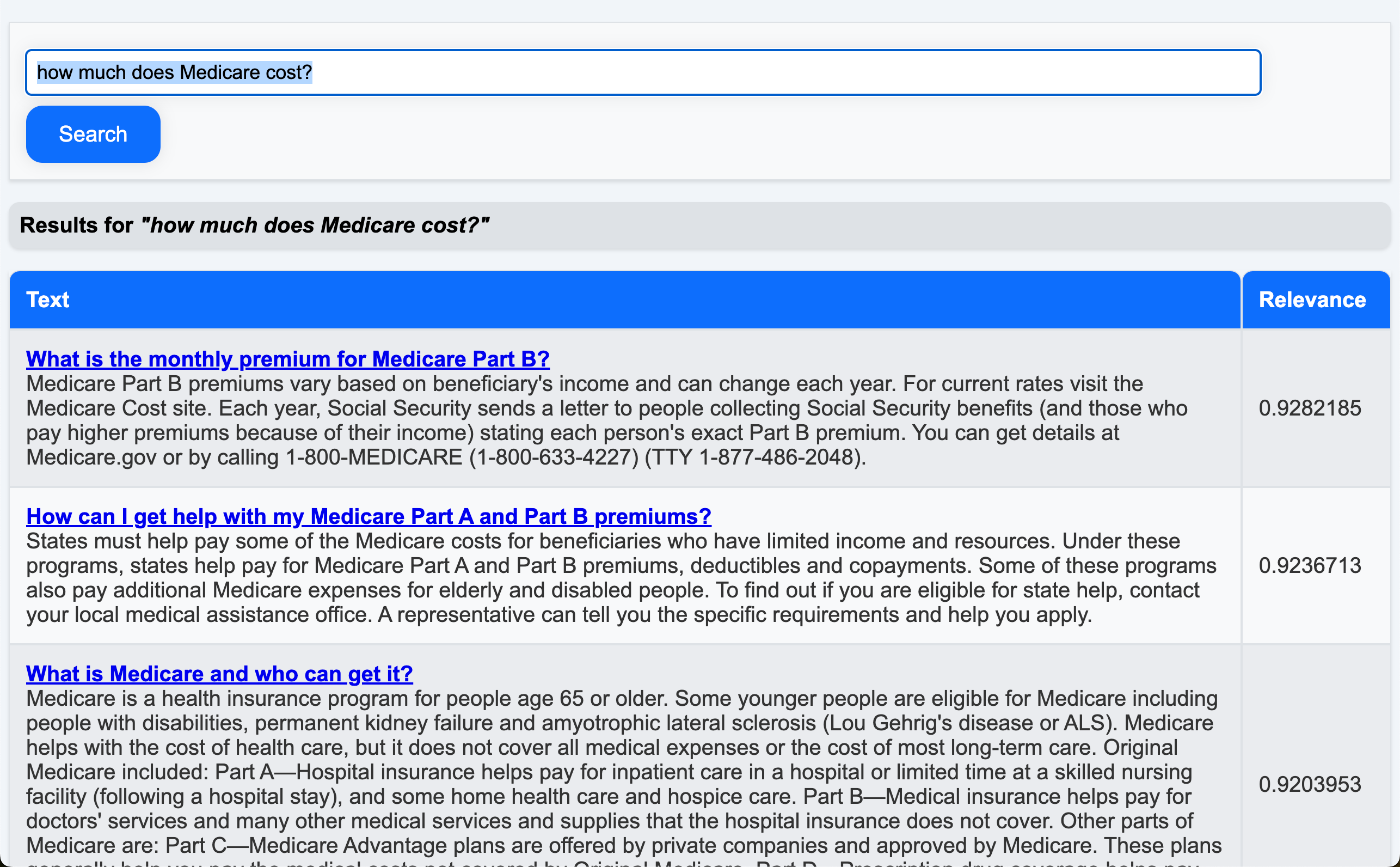
我们还可以进行如下的搜索:
how can I terminate my Medicare?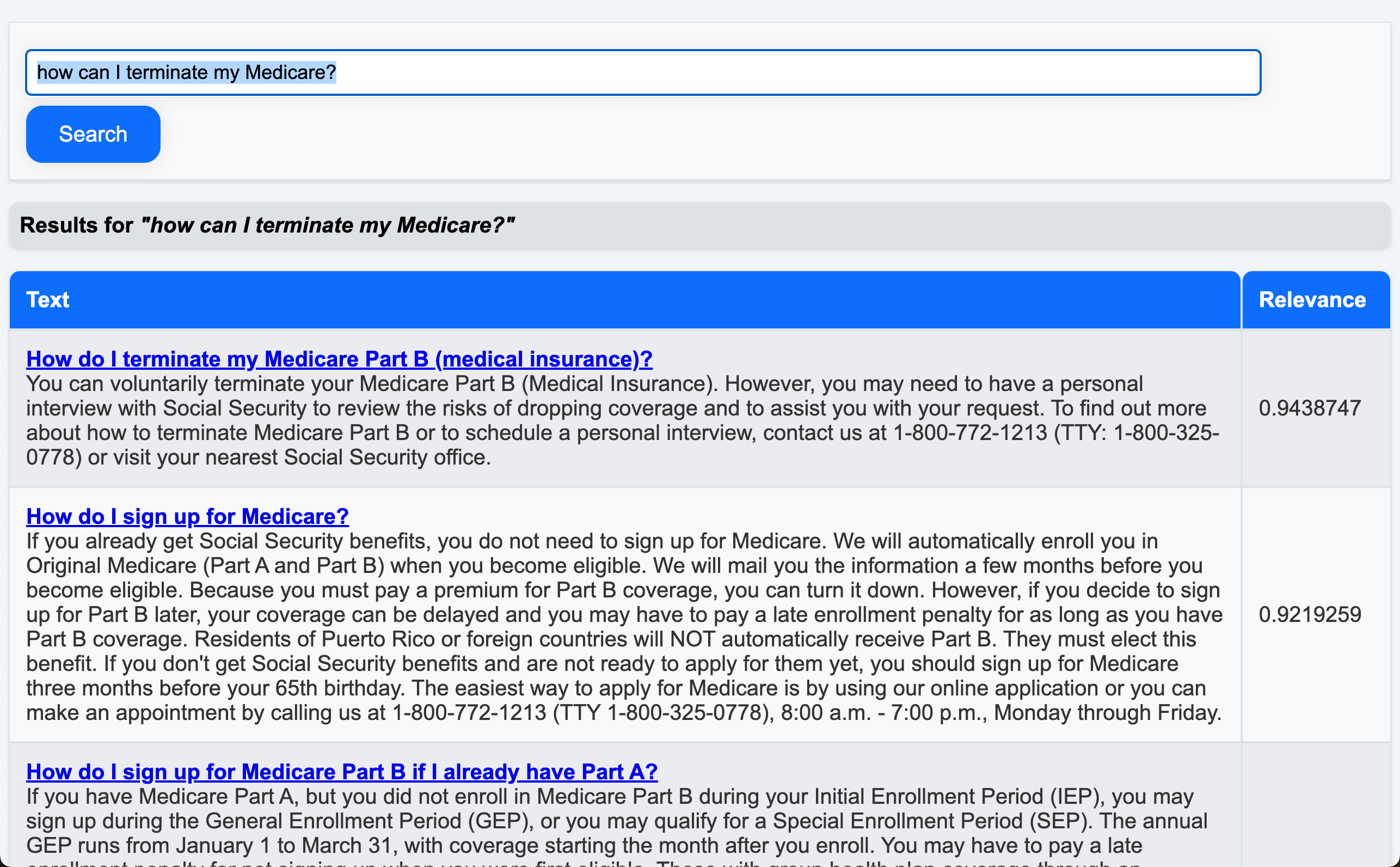
How can I tell whether I am eligible for Medicare?