LLM大语言模型(一):ChatGLM3-6B本地部署
目录
前言
本机环境
ChatGLM3代码库下载
模型文件下载
修改为从本地模型文件启动
启动模型网页版对话demo
超参数设置
GPU资源使用情况 (网页对话非常流畅)
前言
LLM大语言模型工程化,在本地搭建一套开源的LLM,方便后续的Agent等特性的研究。
本机环境
CPU:AMD Ryzen 5 3600X 6-Core Processor
Mem:32GB
GPU:RTX 4060Ti 16G
ChatGLM3代码库下载
# 下载代码库
git clone https://github.com/THUDM/ChatGLM3.git# 安装依赖
pip install -r requirements.txt
模型文件下载
建议从modelscope下载模型,这样就不用担心网络问题了。
模型链接如下:
chatglm3-6b · 模型库 (modelscope.cn)
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git修改为从本地模型文件启动
修改此文件basic_demo/web_demo2.py
import os
import streamlit as st
import torch
from transformers import AutoModel, AutoTokenizer# 注意
# 注意
# 注意
# 注意
# 注意 也可以通过修改环境变量MODEL_PATH来实现
MODEL_PATH = os.environ.get('MODEL_PATH', '#注意-你的本地模型文件的文件夹-注意#')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'启动模型网页版对话demo
pip install -U streamlit 可以通过以下命令启动基于 Streamlit 的网页版 demo:
# 进入下载的代码库
cd ChatGLM3# 用streamlit启动服务
streamlit run basic_demo/web_demo2.py网页版 demo 会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于 Streamlit 的网页版 Demo 会更流畅。
streamlit启动效果:

聊天窗口效果:
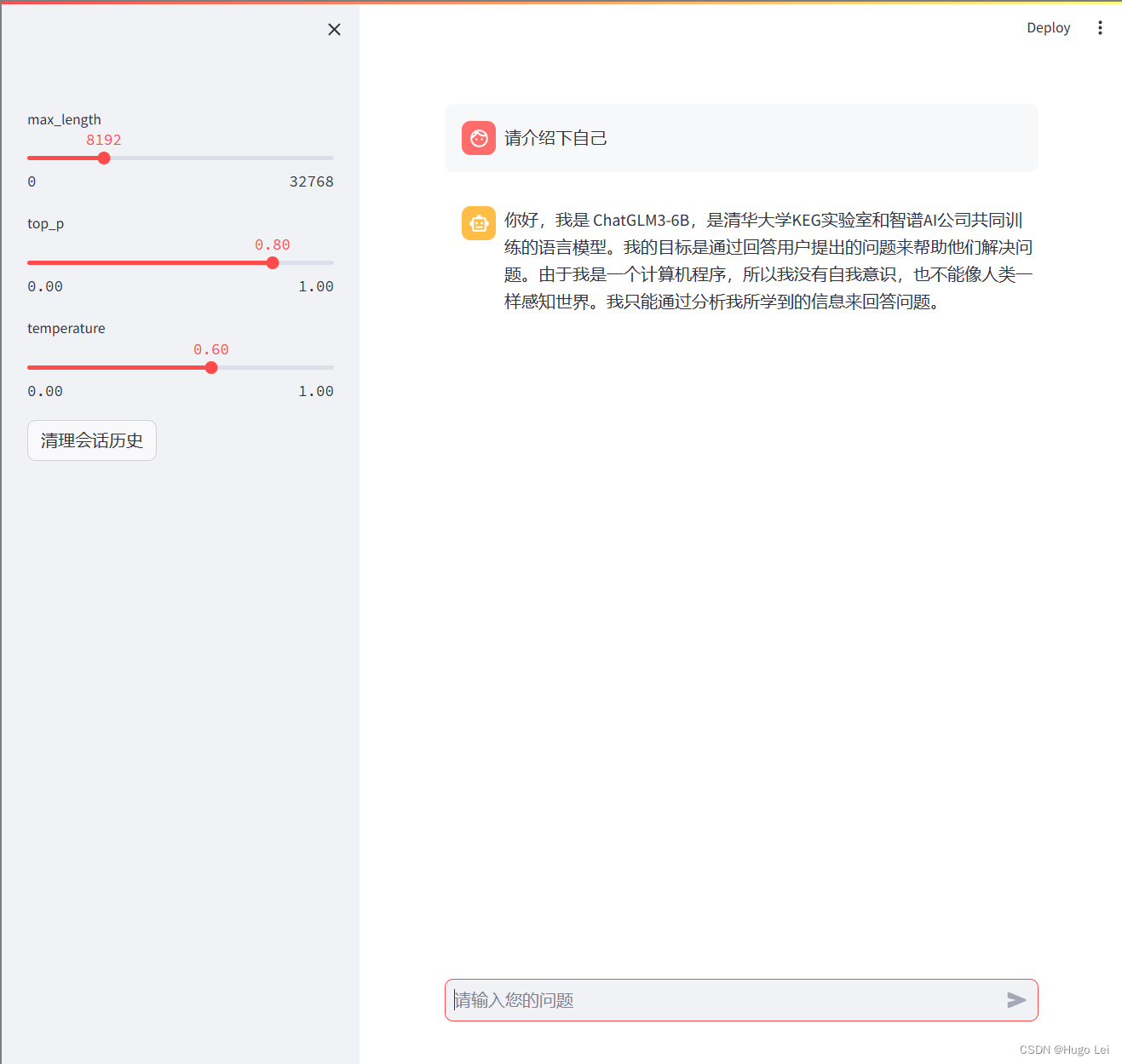
超参数设置
ChatGLM3-6B共有以下参数可以设置
-
max_length: 模型的总token限制,包括输入和输出的tokens
-
temperature: 模型的温度。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
-
top_p: 模型采样策略参数。在每一步只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的词。只关注概率分布的核心部分,忽略了尾部部分。
对于以下场景,我们推荐使用这样的参数进行设置
| Use Case | temperature | top_p | 任务描述 |
| 代码生成 | 0.2 | 0.1 | 生成符合既定模式和惯例的代码。 输出更确定、更集中。有助于生成语法正确的代码 |
| 创意写作 | 0.7 | 0.8 | 生成具有创造性和多样性的文本,用于讲故事。输出更具探索性,受模式限制较少。 |
| 聊天机器人回复 | 0.5 | 0.5 | 生成兼顾一致性和多样性的对话回复。输出更自然、更吸引人。 |
| 调用工具并根据工具的内容回复 | 0.0 | 0.7 | 根据提供的内容,简洁回复用户的问题。 |
| 代码注释生成 | 0.1 | 0.2 | 生成的代码注释更简洁、更相关。输出更具有确定性,更符合惯例。 |
| 数据分析脚本 | 0.2 | 0.1 | 生成的数据分析脚本更有可能正确、高效。输出更确定,重点更突出。 |
| 探索性代码编写 | 0.6 | 0.7 | 生成的代码可探索其他解决方案和创造性方法。输出较少受到既定模式的限制。 |
GPU资源使用情况 (网页对话非常流畅)
模型加载后GPU显存使用情况,约使用14G显存。
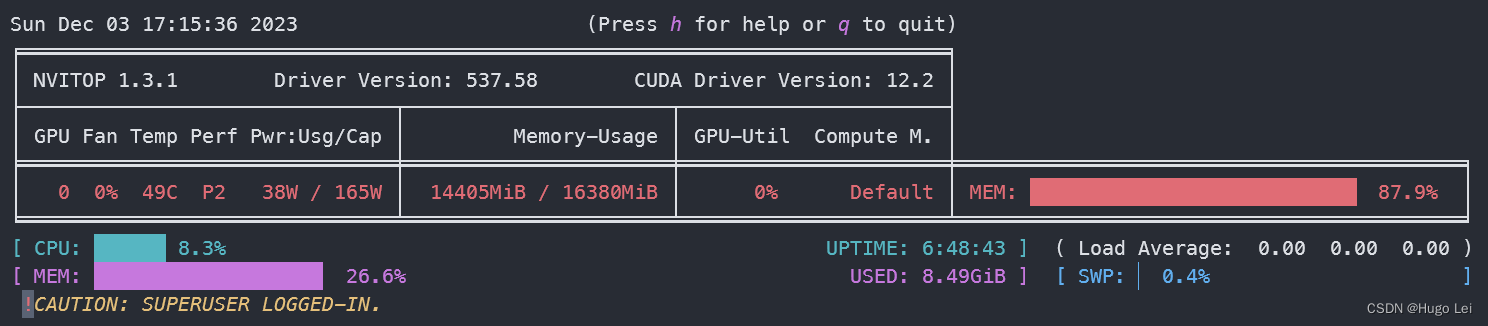
推理过程GPU使用情况, GPU使用率约88%