set和map的基本使用
目录
关联式容器
要点分析
键值对
pair介绍
set
模板参数列表:
set的构造:
常用接口
操作
multiset
map
map的构造
插入
make_pair
map的迭代器
operator[]
multimap
multimap中为什么没有重载operator[]
关联式容器
关联式容器也是用来存储数据的,和vector、list这样的序列式容器不同的是,它里面存储的是<key,value>结构的键值对,在数据检索时效率很高。在STL库中有两种不同结构的关联式容器,树形结构与哈希结构。树形结构的关联式容器包括set、multiset、map、multimap这四种,也是下面要谈论的主要内容。
要点分析
键值对
要走进关联式容器,首先要理解键值对的概念,这一概念在之前的文章中也有介绍,键值对是用来表示对应关系的结构,结构中一般包含两个成员变量key和value,key代表键值,value代表与之对应的信息。例如:下述图片中的名著和作者就是一一对应的关系!

pair介绍
pair这个类是对键值对的定义,将一对不同类型的数据组合(T1和T2)组合在一起,结构中包含两个成员变量分别是key和value,它们的类型是T1和T2。

template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair(): first(T1()), second(T2()){}pair(const T1& a, const T2& b): first(a), second(b){}
}set
set的底层是用二叉搜索树来实现的。set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
模板参数列表:
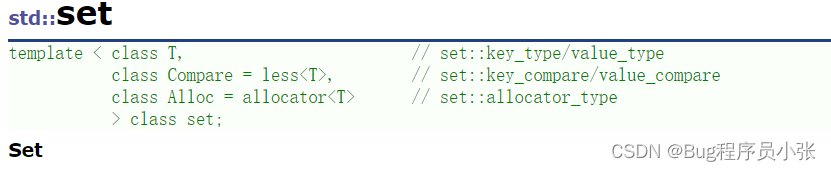
●T: set中存放元素的类型,实际在底层存储<value, value>的键值对。
●Compare:set中元素默认按照小于来比较。
●Alloc:set中元素空间的管理方式,使用STL提供的空间配置器管理。
set的构造:

void TestSet3()
{//构造空的setset<int> s1;//根据区间构造setint arr[10] = {0,1,3,4,5,7,9,6,2,8};int size = sizeof(arr) / sizeof(int);set<int> s2(arr,arr+size);}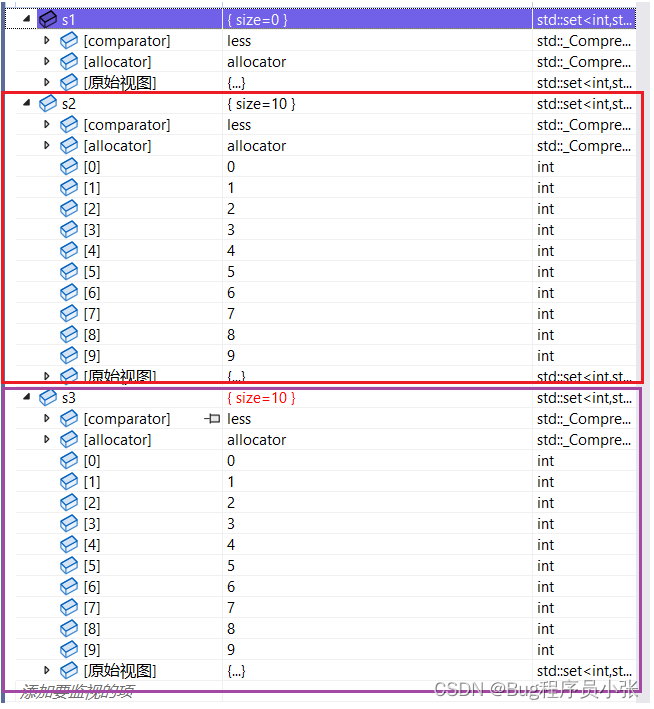
常用接口
修改操作

插入
void SetInsert()
{set<int> ss;ss.insert(5);ss.insert(3);ss.insert(2);ss.insert(2);ss.insert(4);ss.insert(2);ss.insert(2);for (auto& e : ss){cout << e << " ";}
}
需要注意的是,当要插入的数据已经存在,将不会继续插入。
删除
void Seterase()
{set<int> ss;ss.insert(1);ss.insert(2);ss.insert(3);ss.insert(4);ss.insert(5);for (auto& e : ss){cout << e << " ";}cout << endl;ss.erase(3);for (auto& e : ss){cout << e << " ";}cout << endl;ss.erase(5);for (auto& e : ss){cout << e << " ";}cout << endl;ss.erase(1);for (auto& e : ss){cout << e << " ";}
}
交换
void setswap()
{set<int> s1;s1.insert(1);s1.insert(3);s1.insert(5);s1.insert(7);s1.insert(9);cout << "交换前s1:";for (auto& e : s1){cout << e << " ";}set<int> s2;s2.insert(2);s2.insert(4);s2.insert(6);s2.insert(8);s2.insert(10);cout << endl;cout << "交换前s2:";for (auto& e : s2){cout << e << " ";}s1.swap(s2);cout << endl;cout << "交换后s1:";for (auto& e : s1){cout << e << " ";}cout << endl;cout << "交换后s2:";for (auto& e : s2){cout << e << " ";}
}
清理
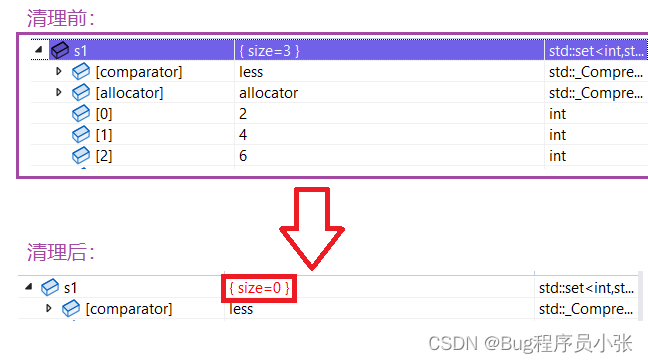
void setclear()
{set<int> s1;s1.insert(2);s1.insert(4);s1.insert(6);s1.clear();
}
迭代器

void set_iterator()
{int arr[10] = {1,3,5,7,9,2,4,6,8,10};int size = sizeof(arr) / sizeof(int);set<int> s1(arr,arr+size);//auto it1 = s1.begin();set<int>::iterator it1 = s1.begin();while (it1 != s1.end()){cout << *it1 << " ";it1++;}//auto it2 = s2.rbegin()set<int>::reverse_iterator it2 = s1.rbegin();cout << endl;while (it2 != s1.rend()){cout << *it2 << " ";it2++;}
}
容量

void setempty_size()
{int arr[10] = { 1,3,5,7,9,2,4,6,8,10 };int size = sizeof(arr) / sizeof(int);set<int> s1(arr, arr + size);cout << "是否为空:" << s1.empty() << endl;cout << "有效元素个数:" << s1.size() << endl;s1.clear();cout << "是否为空:" << s1.empty() << endl;cout << "有效元素个数:" << s1.size() << endl;
}
操作

find:
void setfind()
{int arr[10] = { 1,3,5,7,9,2,4,6,8,10 };int size = sizeof(arr) / sizeof(int);set<int> s1(arr, arr + size);for (auto& e : s1){cout << e << " ";}cout << endl;auto it = s1.find(5);if (it != s1.end()){cout <<"找到了:" << *it << endl;}else{cout << "没找到!" << endl;}it = s1.find(100);if (it != s1.end()){cout << "找到了:" << *it << endl;}else{cout << "没找到!" << endl;}
}
count:
void setcount()
{int arr[10] = { 1,3,1,7,1,2,1,6,8,10 };int size = sizeof(arr) / sizeof(int);set<int> s1(arr, arr + size);for (auto& e : s1){cout << e << " ";}cout << endl;cout << s1.count(1) << endl;cout << s1.count(2) << endl;cout << s1.count(50) << endl;
}
对于count这个接口,你可能不太理解它为什么会存在,它好像只能确定数据是否出现过,查找数据已经有find了,好像没什么“用武之地”。哈哈哈,它的“志向”当然不在此处,我们接着向下看!
multiset
multiset在接口的用法上大致相同,相比较set而言multiset允许重复数据的出现:
void _multiset()
{int arr[10] = { 1,3,1,7,1,2,1,6,8,10 };int size = sizeof(arr) / sizeof(int);multiset<int> s(arr,arr+size);for (auto& e : s){cout << e << " ";}}
count接口上场:
void _multiset_count()
{int arr[10] = { 1,3,1,7,1,2,1,6,2,10 };int size = sizeof(arr) / sizeof(int);multiset<int> s(arr, arr + size);for (auto& e : s){cout << e << " ";}cout << endl;cout << s.count(1) << endl;cout << s.count(2) << endl;cout << s.count(10) << endl;
}
小问题:既然multiset允许数据的重复,那么当我们查找数据的时候,找到的是哪一个呢?
void _multiset_find()
{int arr[10] = { 1,3,1,7,1,2,3,6,3,10 };int size = sizeof(arr) / sizeof(int);multiset<int> s(arr, arr + size);for (auto& e : s){cout << e << " ";}cout << endl;multiset<int>::iterator it = s.find(3);while (it != s.end()){cout << *it << " ";it++;}
}
测试后发现,find找到的位置是中序遍历第一次找到的元素位置。其余接口和set的使用大多一样,这里就不在测试了。
map

●key: 键值对中key的类型
●T: 键值对中value的类型
map的构造

插入
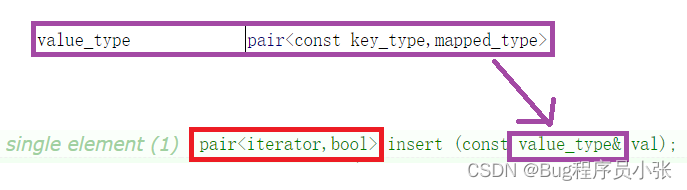
查询文档了解到,insert的返回值是一个pair,需要的参数也是一个pair。
void maptest2()
{map<string, string> notepad;notepad.insert(pair<string,string>("张三","赤峰"));notepad.insert(pair<string,string>("李四","北京"));for (auto& e : notepad){cout << e.first << ":" << e.second << endl;}//auto pr = notepad.insert(pair<string, string>("王麻子", "西安"));pair<map<string,string>::iterator,bool> pr = notepad.insert(pair<string, string>("王麻子", "西安"));cout << (pr.first)->first <<":"<<(pr.first)->second<< endl;
}
接收insert后的返回值,并进行分析:

通过上述测试对insert有了大致的了解,但是插入的过程中代码显得好笨重,pair<string,string>......每次都要写好长好长,这个时候就要介绍一个帮我们偷懒的朋友了:make_pair!
make_pair

make_pair的返回值是一个pair,根据模板参数T1,T2确定pair中两个元素的类型,根据参数x,y确定元素值。也就是说在上述代码插入数据的部分可以这样写:
map<string, string> s;
s.insert(make_pair("张小红","内蒙古"));
map的迭代器
void mapTest4()
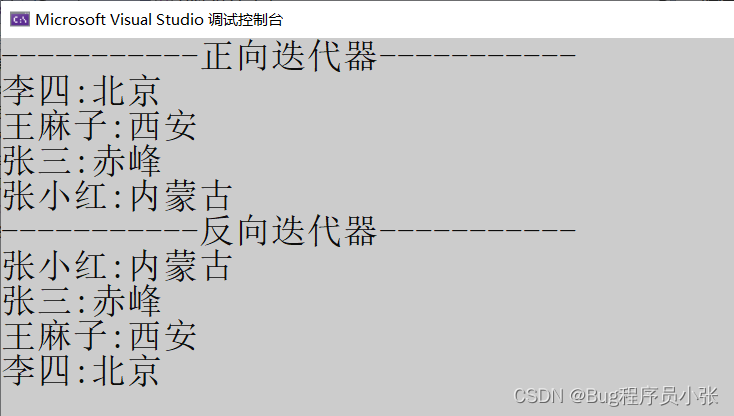
{map<string, string> notepad;notepad.insert(make_pair("张三", "赤峰"));notepad.insert(make_pair("李四", "北京"));notepad.insert(make_pair("王麻子", "西安"));notepad.insert(make_pair("张小红", "内蒙古"));map<string, string>::iterator it1 = notepad.begin();cout << "-----------正向迭代器-----------" << endl;while (it1 != notepad.end()){//cout << (*it1).first << ":" << (*it1).second << endl;cout << it1->first << ":" << it1->second << endl;it1++;}cout << "-----------反向迭代器-----------" << endl;map<string, string>::reverse_iterator it2 = notepad.rbegin();while (it2 != notepad.rend()){//cout << (*it2).first << ":" << (*it2).second << endl;cout << it2->first << ":" << it2->second << endl;it2++;}
}
operator[]
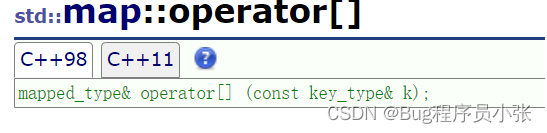
operator[]重载和以往的[]重载相比有一些不一样,传过来的参数是key,返回值是value。在这过程中,首先向this插入make_pair,insert的返回值类型又是一个pair<iterator,bool>,访问pair的first元素获取到一个迭代器,迭代器找到的位置又是一个pair<key,value>,返回该pair的第二个元素也就是value。

观察上图分析后,[]除了访问元素外,还能进行查找,修改,插入的操作。
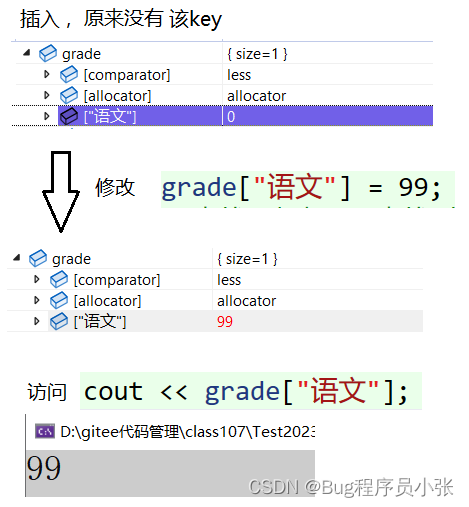
void mapTest5()
{map<string,int> grade;//插入,前提是该数据原来并不存在grade["语文"];//[]返回值是value,可以对其进行修改grade["语文"] = 99;//查找,根据key查找对应的valuecout << grade["语文"] << endl;
}
应用场景1:统计“象牙山村”选举票数!
void mapset1()
{map<string, int> count;string arr[10] = {"刘能","谢广坤","谢广坤","赵四","王老七","刘能","刘能","王老七","刘能","谢广坤"};for (auto& e : arr){auto it = count.find(e);if (it == count.end()){//插入count.insert(make_pair(e,1));}else{//(*it).second++;it->second++;}}cout << "-------象牙山选举大会--------" << endl;for (auto& e : count){cout << e.first << ":" << e.second <<"票"<< endl;}
}

使用[]的版本:
void maptest1()
{map<string, int> count;string arr[10] = {"刘能","谢广坤","谢广坤","赵四","王老七","刘能","刘能","王老七","刘能","谢广坤"};for (auto& e : arr){count[e]++;}cout << "-------象牙山选举大会--------" << endl;for (auto& e : count){cout << e.first << ":" << e.second <<"票"<< endl;}
}
对比两组代码,后者是不是简单了不少呢,[]使用起来非常的方便,但同时也是一把双刃剑,需要我们对其底层原理有所了解,在使用的时候也一定要细心。
multimap
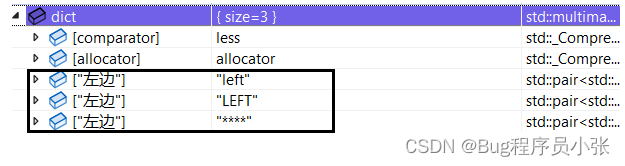
multimap和map的区别:map中的key是唯一的,而multimap中key是可以重复的。
void Test6()
{multimap<string, string> dict;dict.insert(make_pair("左边", "left"));dict.insert(make_pair("左边", "LEFT"));dict.insert(make_pair("左边", "****"));
}
multimap中为什么没有重载operator[]
在了解过map的[]重载后,你知道[]需要key来访问value。那么在multimap这种允许key重复出现的场景下,xxx[key]访问到的value不一定是唯一的,这时的修改操作也不知道该去修改哪一个value,所以multimap没有重载[]。
小结:关联式容器的介绍到这就结束了,有些接口没有涉及到,有兴趣的小伙伴可以继续查找文档探索!
<set> - C++ Reference
<map> - C++ Reference