[c++]—string类___深度学习string标准库成员函数与非成员函数
要相信别人能做出来自己一定可以做出来,只不过是时间没到而已目录
🚩string类对象capacity操作
💻reserve()保留
💻resize()
🚩string类对象元素访问操作
💻operator[]和at()
💻operator[]和at()函数有关越界访问
🚩string类对象修饰语操作
💻assign()
💻insert()
💻erase()
💻replace()
🎓replace()函数的应用
🚩string类字符串操作
💻substr() 截取子字符串
💻find()函数
👉npos成员常量
💻find()和substr()函数结合使用
💻rfind()函数
🎓find()和rfind()的区别
🎓题目—字符串最后一个单词的长度
👉getline()
💻find_first_of()函数
💻find_last_of()函数
🎓find_first_of()和find_last_of()
我们接着上一章的学习。
🚩string类对象capacity操作


从上一章节介绍了,size()和length()记录的是string类对象的字符串长度, max_size()指的是string类容纳的最大长度,capacith指的是已分配存储的大小,clear表示清空string类对象。
这里只限定在vs环境下,不同的环境下的处理不同
💻reserve()保留

C++中的reserve函数被广泛用于容器类中,它的作用是预留一定量的内存空间来存储元素,以提高程序的效率。这个函数只影响容器的capacity(容量),而不改变该容器包含的元素个数。使用reserve函数可以避免频繁的动态内存分配和释放,减少内存碎片的产生,以提高代码的效率。

💻resize()
c++中resize函数是c++标准库vector容器的一个成员函数,用于改变vector的大小。它可以使vector变大或变小,根据变化的大小,它可能会在vector的末尾添加新元素,或者从末尾删除元素。

第一个参数表示新的大小,第二个可选参数表示插入的新值(缺省为默认构造函数值,可以是一个默认值,也可以是一个可变参数模板包)。
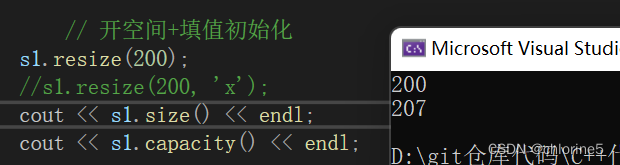
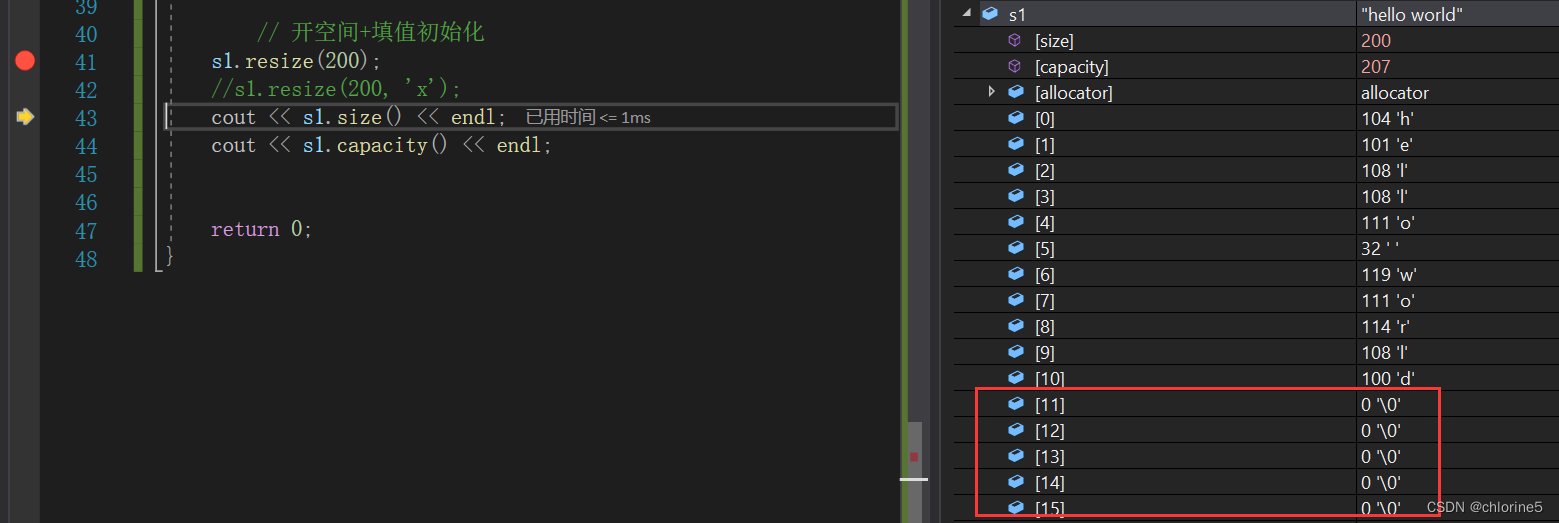
这里给字符串长度设置成200,后面直接初始化成'\0',capacity肯定是大于200的。
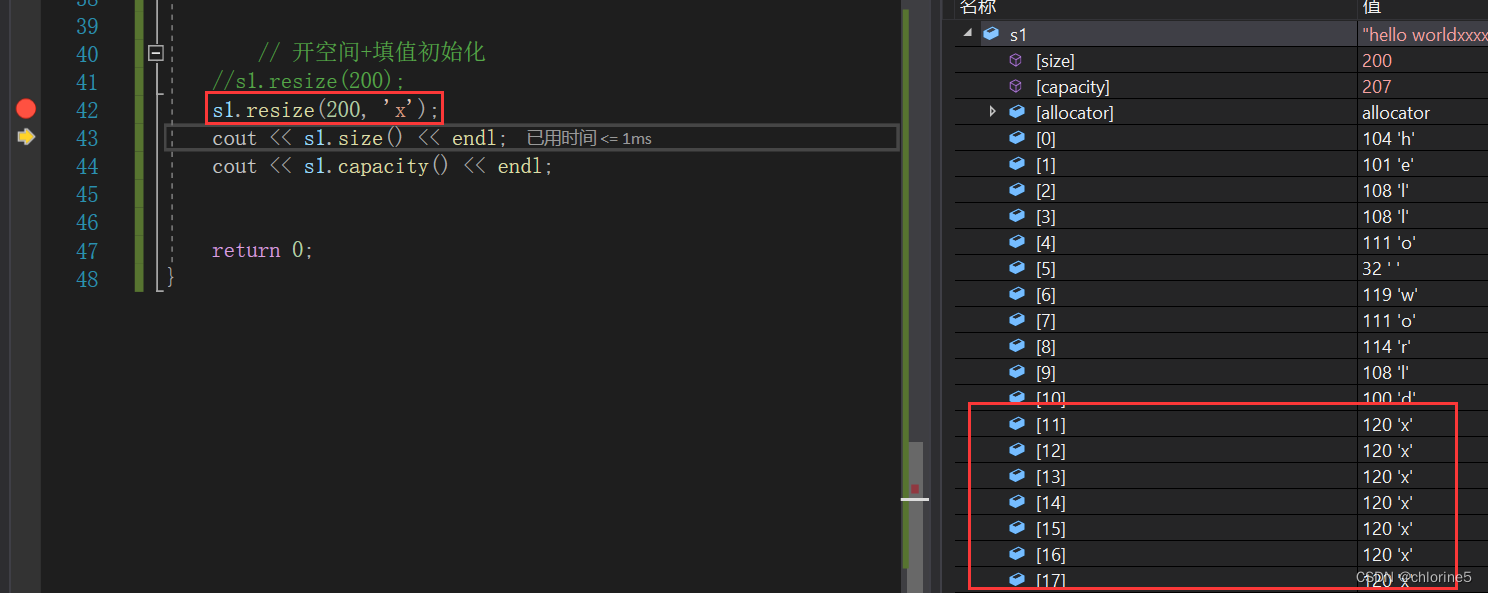
第二个函数不仅开空间,而且 填值初始化为'x'。

再次调用resize()函数是不会改变capacity的值,因为你想想,开辟了200个字符的空间,然后只需要20的空间,剩下的180空间直接交给操作系统了,那这样造成了极大的浪费,一般我们都是拷贝那20空间给新的字符串,然后free那剩下的空间。而不是这样直接丢弃,编译器是不会允许你这样做的。所以capacity是不可改变的。
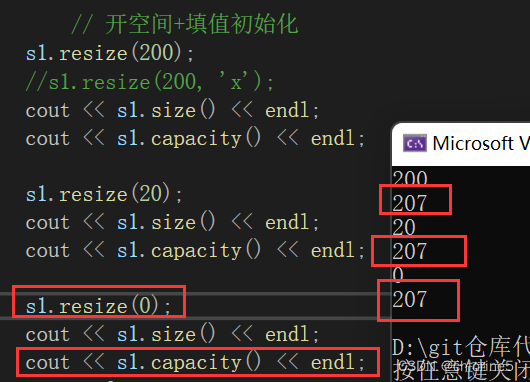 这里只限定在vs环境下,不同的环境下的处理不同,我们调用resize()函数至字符串长度为0,capacity也是不改变的。
这里只限定在vs环境下,不同的环境下的处理不同,我们调用resize()函数至字符串长度为0,capacity也是不改变的。
🚩string类对象元素访问操作
💻operator[]和at



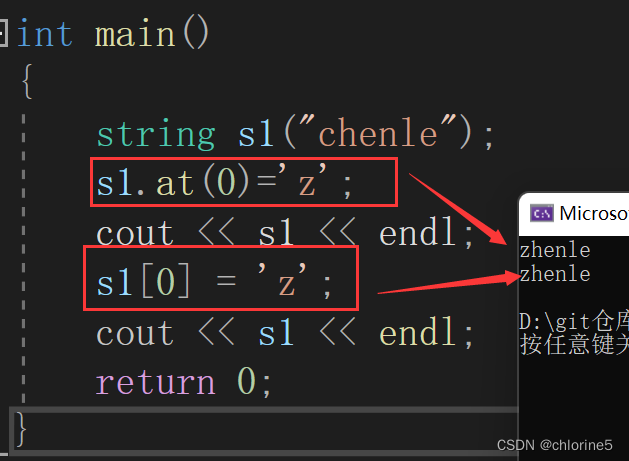
int main()
{string s1("chenle");s1.at(0)='z';cout << s1 << endl;s1[0] = 'z';cout << s1 << endl;return 0;
}
💻operator[]和at()函数有关越界访问
int main()
{string s1("chenle");s1.at(0)='z';cout << s1 << endl;s1[0] = 'z';cout << s1 << endl;s1[15];s1.at(15);return 0;
}
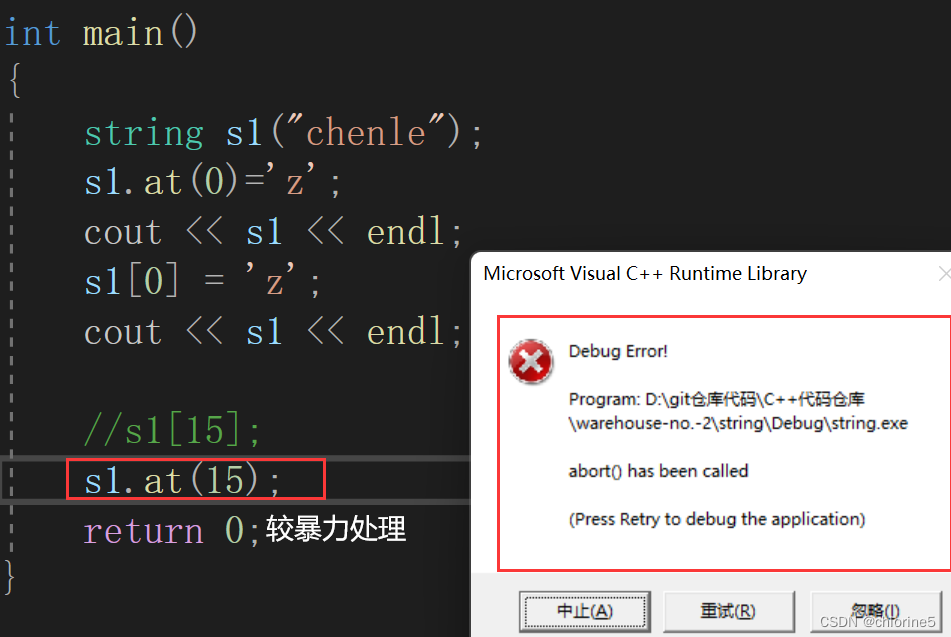
at()函数越界抛异常
 at()函数调用如果越界,那么会抛异常,用下面的格式就相对于调用operator[]函数相对温和一点的处理方式。
at()函数调用如果越界,那么会抛异常,用下面的格式就相对于调用operator[]函数相对温和一点的处理方式。
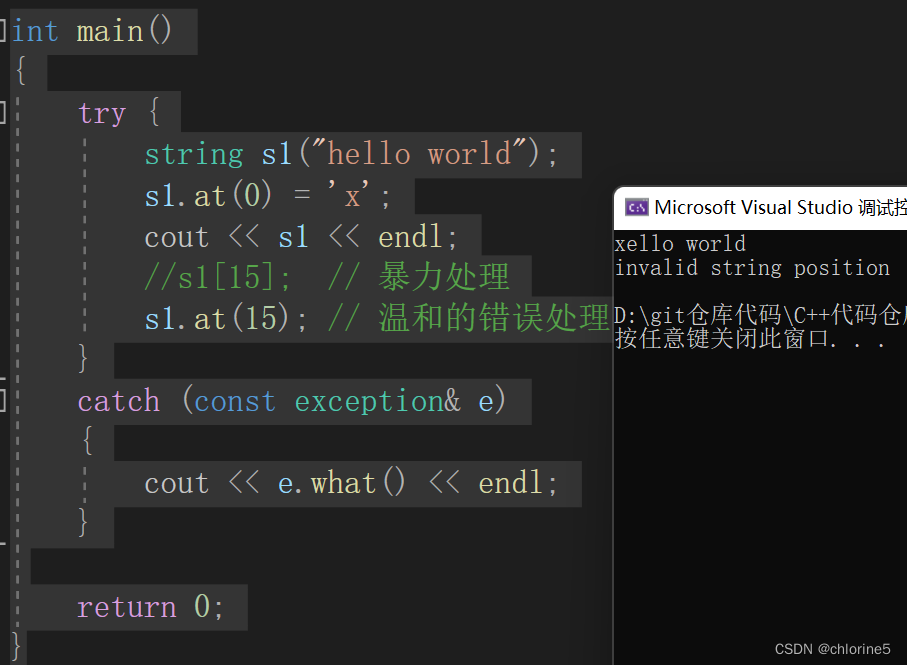
int main()
{try {string s1("hello world");s1.at(0) = 'x';cout << s1 << endl;//s1[15]; // 暴力处理s1.at(15); // 温和的错误处理}catch (const exception& e){cout << e.what() << endl;}return 0;
}
🚩string类对象修饰语操作

前面一篇文章我们讲了上面三个函数operator+=(),append(),push_back()。

💻assign()
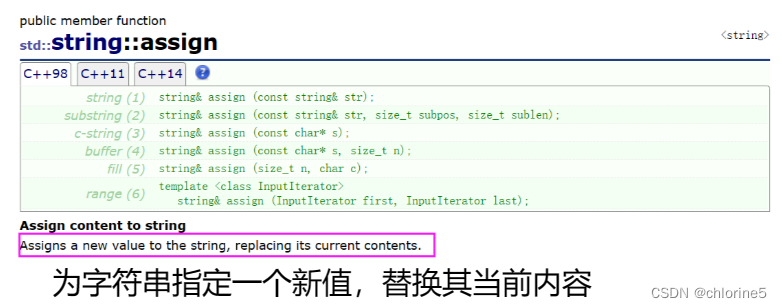
int main()
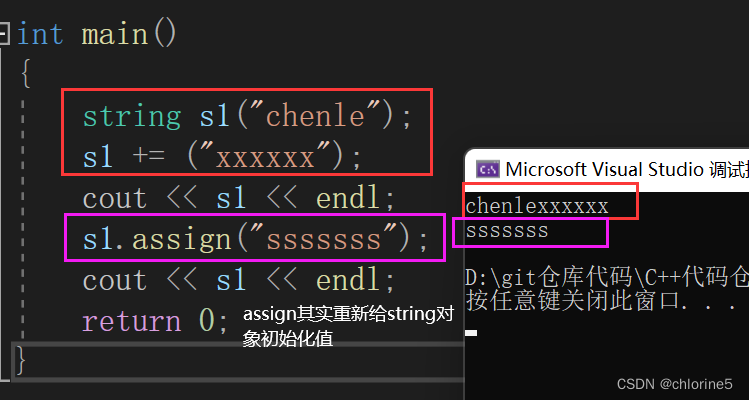
{string s1("chenle");s1 += ("xxxxxx");cout << s1 << endl;s1.assign("sssssss");cout << s1 << endl;return 0;
}
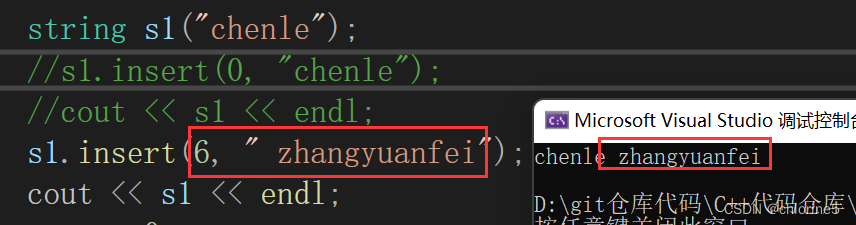
💻insert()



💻erase()

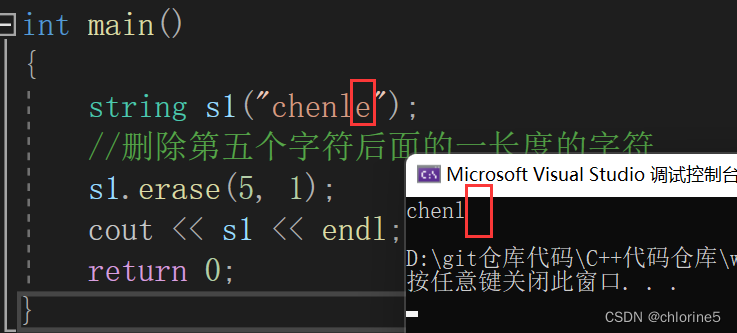
int main()
{string s1("chenle");//删除第五个字符后面的一长度的字符s1.erase(5, 1);cout << s1 << endl;return 0;
}
string s1("chenle");cout << s1 << endl;s1.erase(3);cout << s1 << endl;

int main()
{string s2("hello world");/*s2.erase(0, 1);cout << s2 << endl;*///利用迭代器,begin()函数,那么删除begin()所指的当前位置的字符s2.erase(s2.begin());//参数不是迭代器,是个数值,那么删除第三个元素后面的所有字符s2.erase(3);cout << s2 << endl;return 0;
}

💻replace()
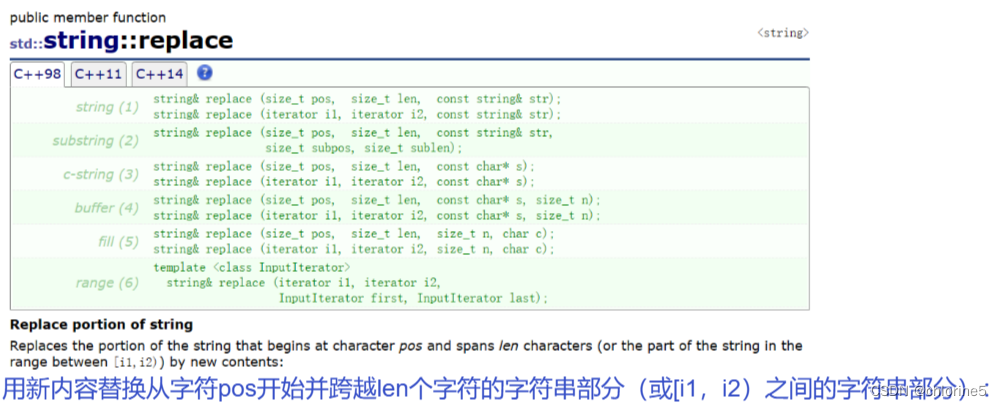
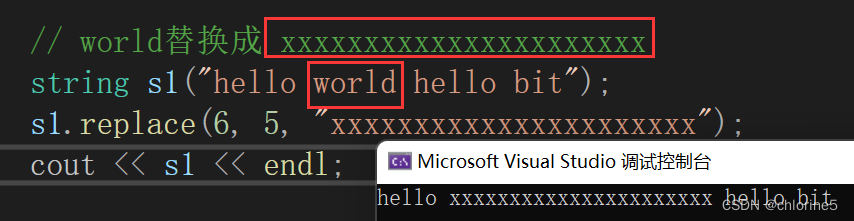
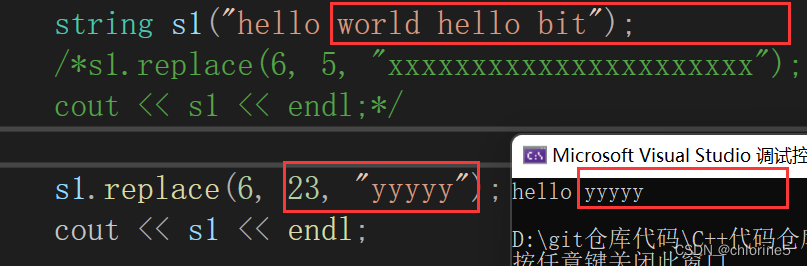
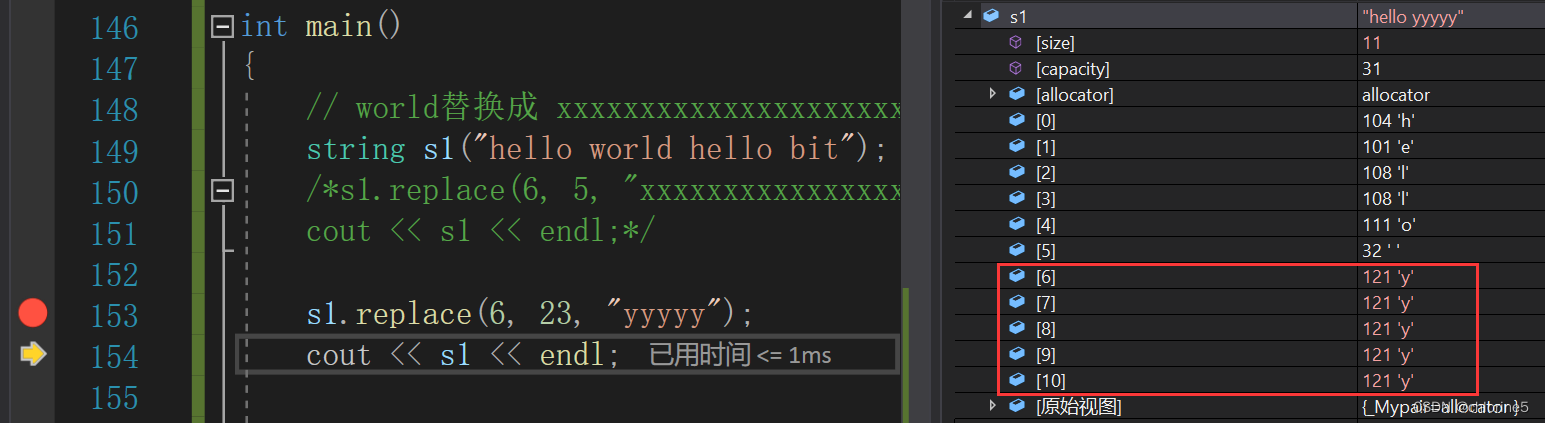
🎓replace()函数的应用
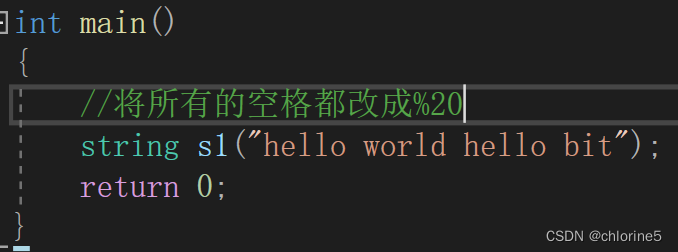
int main()
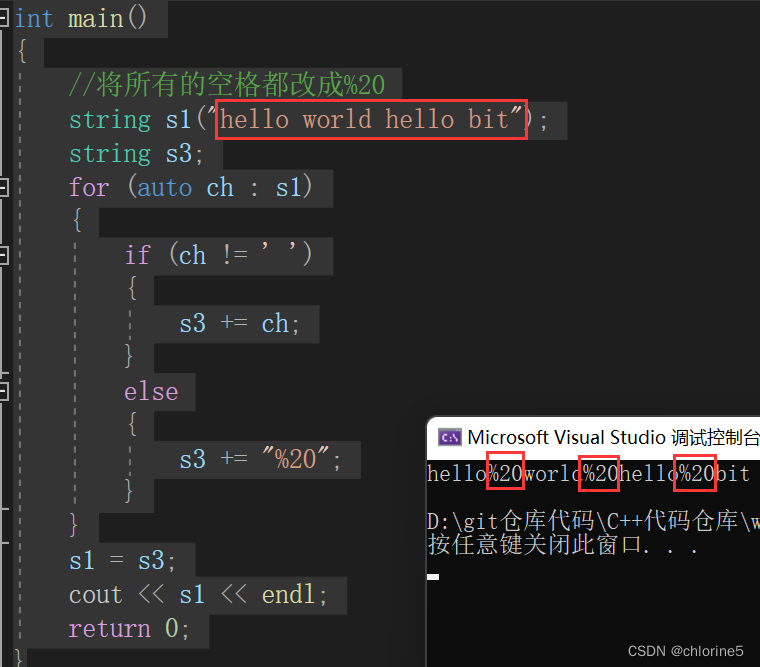
{//将所有的空格都改成%20string s1("hello world hello bit");string s3;for (auto ch : s1){if (ch != ' '){s3 += ch;}else{s3 += "%20";}}s1 = s3;cout << s1 << endl;return 0;
}
🚩string类字符串操作

💻substr() 截取子字符串

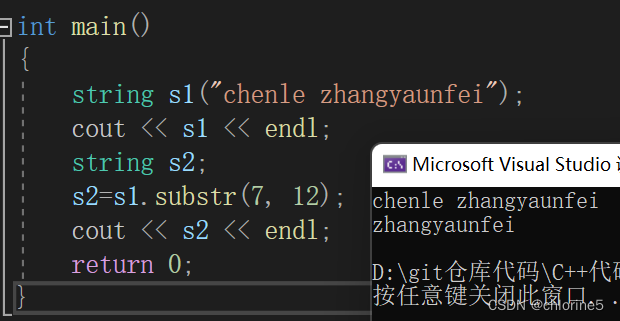
注意:这里需要创建一个新的string对象被子字符串初始化,因为截取字符串不改变原先的字符串。
int main()
{string s1("chenle zhangyaunfei");cout << s1 << endl;string s2;s2=s1.substr(7, 12);cout << s2 << endl;return 0;
}
💻find()函数

👉npos成员常量

这里我需要介绍一下npos
- npos可以表示string的结束位子,是string::type_size 类型的,也就是find()返回的类型。find函数在找不到指定值的情况下会返回string::npos。
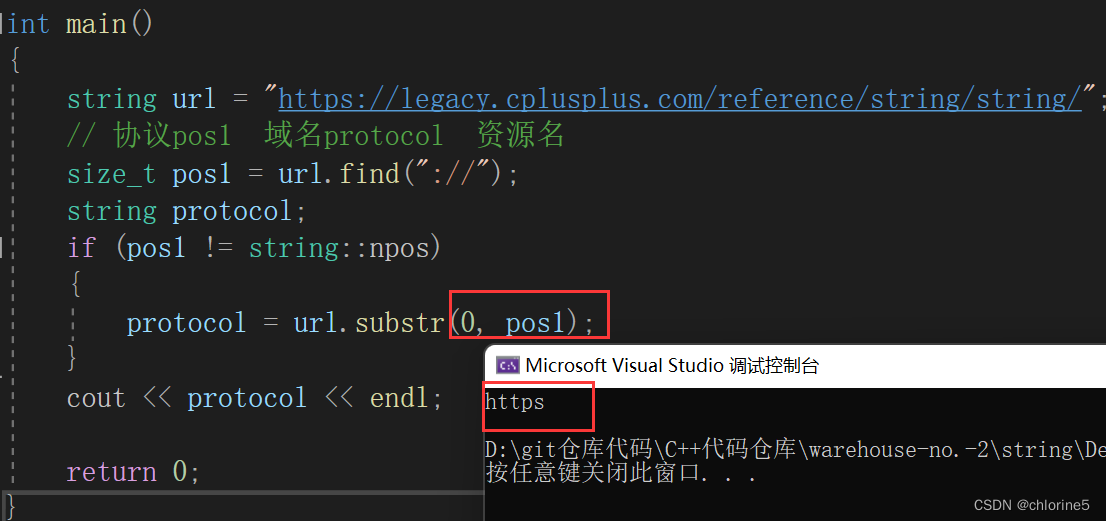
这里我需要打印出这段网址中的协议http。我们想要找到://,那么用string::npos,如果find函数找不到://,那么就返回string::npos。我们可以看到我们依次遍历找到了://,那么不返回string::npos,if判断为真,然后截取[0,pos1)字符串字段,然后打印出。
int main()
{string url = "https://legacy.cplusplus.com/reference/string/string/";// 协议pos1 域名protocol 资源名size_t pos1 = url.find("://");string protocol;if (pos1 != string::npos){protocol = url.substr(0, pos1);}cout << protocol << endl;return 0;
}
一个网址由三个部分组成,协议,域名,资源名组成,我们要分别打印出协议的部分,域名的部分,资源名的部分,该如何使用find(),substr()函数呢?
💻find()和substr()函数结合使用
int main()
{string url = "https://legacy.cplusplus.com/reference/string/string/";// 协议protocol 域名 资源名size_t pos1 = url.find("://");string protocol;if (pos1 != string::npos){protocol = url.substr(0, pos1);}cout << protocol << endl;string domain;//域名string uri;//资源名size_t pos2 = url.find('/', pos1 + 3);//从pos1+3位置开始找'/'if (pos2 != string::npos){domain = url.substr(pos1+3,pos2-(pos1+3));//从pos1+3的位置,截取(pos2-(pos1+3))的长度,读到遇到第一个'/'位置uri = url.substr(pos2 + 1);//直接从pos2+1位置后读到最后即可}cout << domain << endl;cout << uri << endl;return 0;
}
💻rfind()函数
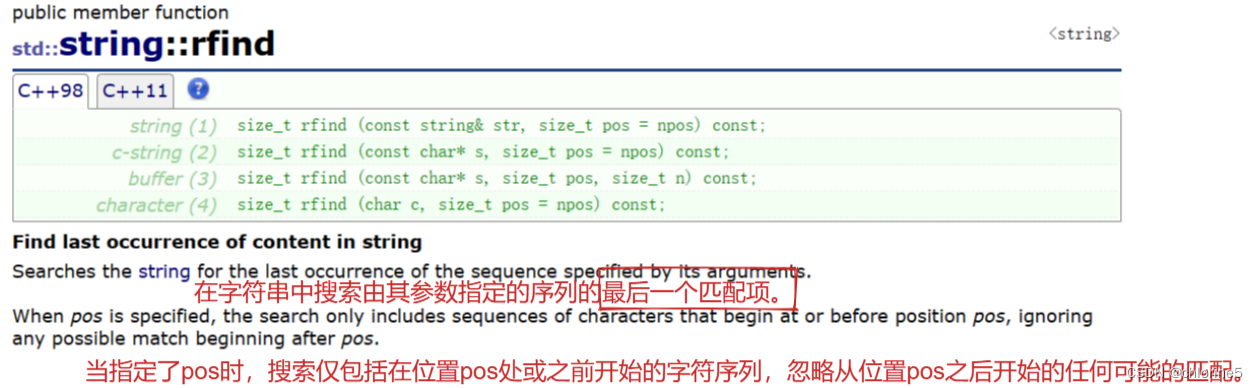
逆向查字符或字符串,若查找成功,则返回逆向查到的第一个字符下标或第一个字符串首字符的下标;若查找失败,无法返回正确的下标。逆向查到的第一个字符或第一个字符串也就是正向的最后一个。rfind()函数的返回值为无符号整数类型。(rfind从后向前逆向查,但匹配是正向匹配的,可以参考下面代码多理解。)
str.rfind(“fab”,4);//从下标为4开始逆向查找,正向匹配,结果找不到,返回npos。
str.find(“fab”);//如果没有第二个参数,默认从下标npos开始。npos定义为保证大于任何有效下标的值。结果为5。
🎓find()和rfind()的区别
#include<iostream>
using namespace std;
int main()
{string str="abcdefab";cout<<str.find('a')<<endl;//正向找到,返回有效下标0。cout<<str.find('h')<<endl;//正向找不到,返回npos。cout<<str.find("ab",1)<<endl;//正向找到并返回ab的首字母a下标6。cout<<str.find("ab")<<endl;//没有第二个参数,默认从0下标开始正向查找,结果为0。正向查找,正向匹配。cout<<str.find("ha")<<endl;//正向找不到,返回npos。cout<<str.rfind('b')<<endl;//逆向找到并返回b的下标7。cout<<str.rfind('h')<<endl;//逆向找不到,返回npos。cout<<str.rfind('a',100)<<endl;//从下标100逆向查找,找到并返回a下标6。如果没有第二个参数,默认从下标npos开始。npos定义为保证大于任何有效下标的值。//如果要设置rfind()的第二个参数,那么一般情况下大于等于len-1就可以。cout<<str.rfind("fab")<<endl;//逆向找到,结果为5。cout<<str.rfind("fab",4)<<endl;//逆向找不到,返回npos。cout<<str.rfind("fab",5)<<endl;//逆向可以找到,结果为5。rfind从后向前逆向查,但匹配是正向匹配的,可以参考这个代码多理解。return 0;
}
//有效的下标应该在0~len-1范围内。len=str.size();🎓题目—字符串最后一个单词的长度
#include <iostream>
using namespace std;int main()
{string str1;// 不要使用cin>>line,因为会它遇到空格就结束了// while(cin>>line)while(getline(cin, str1)){size_t pos1=str1.rfind(' ');cout<<str1.size()-pos1-1<<endl;}return 0;
}👉getline()

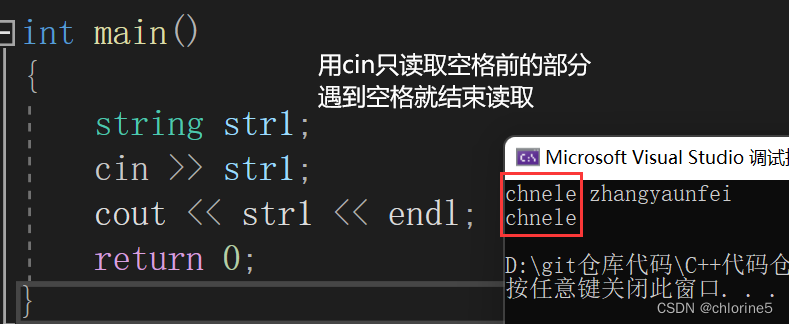
遇到这种情况我们用getline()这个非成员函数来进行操作

getline()函数读取一整行。
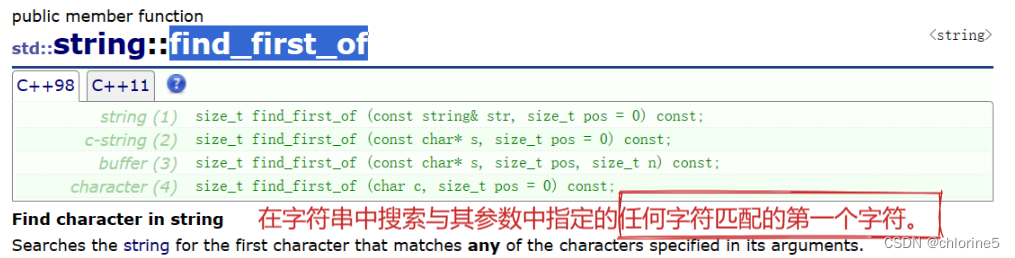
💻find_first_of()函数
int main()
{string str("Please, replace the vowels in this sentence by asterisks.");size_t found = str.find_first_of("abc");while (found != string::npos){str[found] = '*';//找到abc字符那么就改成*found = str.find_first_of("abc", found + 1);//继续从found后面一个字符开始找abc任意一个}cout << str << '\n';return 0;
}
💻find_last_of()函数
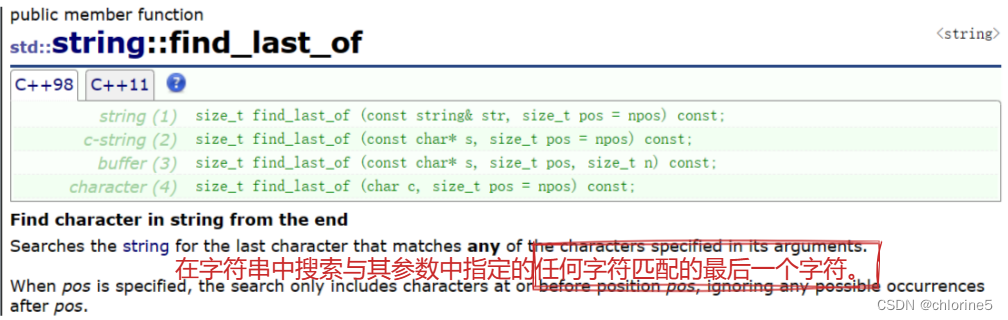
🎓find_first_of()和find_last_of()
- 1、find_first_of()函数
- 正向查找在原字符串中第一个与指定字符串(或字符)中的某个字符匹配的字符,返回它的位置。若查找失败,则返回npos。(npos定义为保证大于任何有效下标的值。)
- 2、find_last_of()函数
- 逆向查找在原字符串中最后一个与指定字符串(或字符)中的某个字符匹配的字符,返回它的位置。若查找失败,则返回npos。(npos定义为保证大于任何有效下标的值。)
#include<iostream>
using namespace std;
int main()
{string str="abcdefab";cout<<str.find_first_of('a')<<endl;//第二个参数为0,默认从下标为0开始查找。cout<<str.find_first_of("hce")<<endl;//待查串hce第一个出现在原串str中的字符是c,返回str中c的下标2,故结果为2。cout<<str.find_first_of("ab",1)<<endl;//从下标为1开始查,待查串ab第一个出现在原串str中的字符是b,返回b的下标,结果为1。cout<<str.find_first_of('h')<<endl;//原串没有待查字符h,故查不到,返回npos。cout<<str.find_first_of("hw")<<endl;//待查子串任一字符在原串中都找不到,故查不到,返回npos。cout<<str.find_last_of("wab")<<endl;//原串最后一个字符首先与待查子串的每一个字符一一比较,一旦有相同的就输出原串该字符的下标.。结果为b的下标7。cout<<str.find_last_of("wab",5)<<endl;//从原串中下标为5开始逆向查找,首先f与待查子串每一字符比较,若有相同的就输出该字符在原串的下标。//若一个都没有,就依次逆向比较,即e再与待查子串一一比较,直到原串的b与待查子串中的b相同,然后输出该b在原串的下标1。cout<<str.find_last_of("fab",5)<<endl;//输出f在原串的下标5。cout<<str.find_last_of("fab",7)<<endl;//输出b在原串的下标7。cout<<str.find_last_of("hwk")<<endl;//原串没有待查子串的任何字符,故返回npos。return 0;
}
//有效的下标应该在0~len-1范围内。len=str.size();
要相信别人能做出来自己一定可以做出来,只不过是时间没到而已