Pandas时序数据分析实践—基础(1)
目录
- 1. Pandas基本结构
- 2. Pandas数据类型
- 2.1. 类型概述
- 2.1.1. 整数类型(int):
- 2.1.2. 浮点数类型(float):
- 2.1.3. 布尔类型(bool):
- 2.1.4. 字符串类型(object):
- 2.1.5. 时间类型:
- 2.1.6. 分类类型:
- 2.2. 类型内存
- 2.3. Pandas数据类型与python、numpy对比
- 2.3. 类型转换
- 3. 常用函数
- 3.1. 基本函数
- 3.2. 窗口函数
- 3.3. 基本统计
1. Pandas基本结构
Pandas是一个基于Numpy的数据结构,它提供了两种主要的数据结构:Series和DataFrame。Series是一种一维的数组型对象,它包含了一个值序列。DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共同用一个索引) 。
- Series是一种一维的带标签数组对象,Series中的元素可以是任何类型的数据;
- DataFrame,二维数据表,是Series容器,而DataFrame中的元素必须是同一种类型的数据 。
其中,最常用的是DataFrame,做为数据分析数据载体——二维数据表,基于此有大量的统计分析函数。DataFrame结构如下图所示。
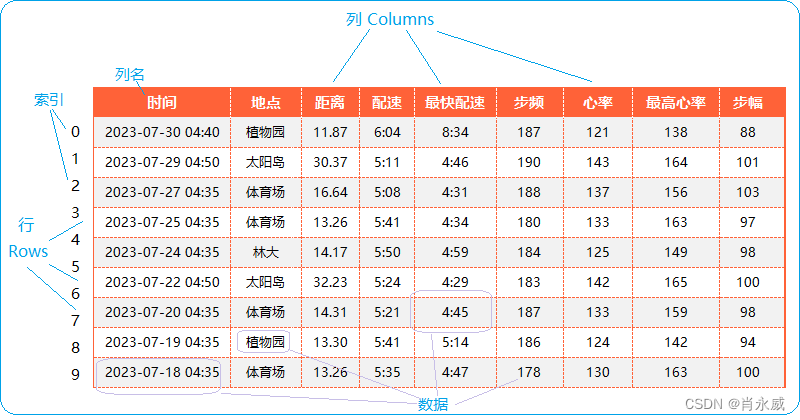
DataFrame是由多种类型的列构成的二维标签数据结构,类似于Excel、SQL表,或Series对象构成的字典。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共同用一个索引) 。
DataFrame的数据由三个部分组成:行索引、列索引和数据。每个元素都有一个行索引和一个列索引,它们都是唯一的。行索引和列索引都可以是任何类型的对象,例如整数、字符串、日期等。
2. Pandas数据类型
2.1. 类型概述
使用pandas进行数据分析时,最常用到的几种类型是:字符串类型、数值类型(整数和浮点数)、日期类型、category 类型。
import pandas as pd
import numpy as np# 创建一个包含各种类型的DataFrame
data = {'Integer': pd.Series([1, 2, 3], dtype='int32'),'Float': pd.Series([21.1, 25.2, 30.3], dtype='float64'),'Boolean': pd.Series([True, False, True], dtype='bool'),'String': pd.Series(['植物园', '湘江公园', '太阳岛'], dtype='object'),'Datetime': pd.to_datetime(['2022-01-01', '2022-02-01', '2022-03-01']),
}df = pd.DataFrame(data)# 添加一个分类类型的列
df['Category'] = pd.Series(['dog', 'cat', 'dog'], dtype='category')print("包含各种类型的DataFrame:\n", df)2.1.1. 整数类型(int):
概述: Pandas 提供不同精度的整数类型,如int8、int16、int32、int64,用于存储整数数据。
应用场景: 选择合适的整数类型有助于减小数据集的内存占用。
2.1.2. 浮点数类型(float):
概述: Pandas 支持不同精度的浮点数类型,如float16、float32、float64,用于存储带小数的数值。
注意事项: 选择适当的浮点数类型有助于平衡精度和内存占用。
2.1.3. 布尔类型(bool):
概述: 布尔类型用于存储逻辑值,通常在数据筛选中使用。
应用场景: 用于筛选数据集中的特定条件。
2.1.4. 字符串类型(object):
概述: Pandas 的字符串类型,通常使用 object 表示,适用于包含文本数据的列。
字符串操作: Pandas 提供了丰富的字符串操作,如字符串拼接、切片、替换等。
2.1.5. 时间类型:
概述: Pandas 提供 datetime 类型用于处理日期和时间数据。
日期操作: 支持日期的解析、格式化、加减等操作。
时间序列: 时间类型在 Pandas 中常用于创建时间序列索引。
2.1.6. 分类类型:
概述: Pandas 提供 category 类型用于处理有限个数的离散值,提高性能和内存效率。
应用场景: 适用于重复值较多的列,如性别、地区等。
2.2. 类型内存
通过观察内存使用情况,你可以更好地了解哪些列占用了大量内存,从而决定是否需要调整它们的数据类型。memory_usage 方法是一个非常有用的工具,可以用于查看 DataFrame 中各列的内存使用情况。合理选择数据类型是优化内存使用的重要步骤之一,特别是当处理大型数据集时。
# 接续上面的代码。
df.memory_usage(deep=True)
Index 128Integer 12Float 24Boolean 3String 266Datetime 24Category 400dtype: int64
在这个例子中,memory_usage(deep=True) 会返回一个 Series,其中包含每列的内存使用情况。deep=True 会深入到对象中,对于字符串类型的列,会计算字符串的实际内存使用情况。
2.3. Pandas数据类型与python、numpy对比
| Pandas dtype | Python类型 | Numpy类型 | 说明 |
|---|---|---|---|
| object | str | string_,unicode_ | 用于文本 |
| int64 | int | int_,int8_,int16,int32,int64,uint8,uint16,uint32,uint64 | 用于整数 |
| float64 | float | float_,float16,float32,float64 | 用于浮点数 |
| bool | bool | bool_ | 用于布尔值 |
| datetime64 | NA | NA | 用于日期时间 |
| timedelta[ns] | NA | NA | 用于时间差 |
| category | NA | NA | 用于有限长度的文本值列表 |
2.3. 类型转换
import pandas as pd# 创建一个包含不同类型数据的DataFrame
data = {'Float': [1.1, 2.2, 3.3],'Integer': [1, 2, 3],'Timestamp': pd.to_datetime(['2022-01-01', '2022-02-01', '2022-03-01']),'TimestampString': ['2022-01-01', '2022-02-01', '2022-03-01']
}df = pd.DataFrame(data)# 转换 'Float' 列为字符串
df['Float'] = df['Float'].astype(str)# 转换 'TimestampString' 列为 datetime64 类型
df['TimestampString'] = pd.to_datetime(df['TimestampString'])# 查看转换后的数据类型
print("\n转换类型后的数据类型:\n", df.dtypes)# 转换 'Float' 列为字符串
df['Float'] = df['Float'].astype('float32')df['TimestampString'] = df['TimestampString'].dt.strftime('%Y-%m-%d %H:%M')
# 查看再转换后的数据类型
print("\n再转换类型后的数据类型:\n", df.dtypes)
df

当数据类型转换处理 Pandas DataFrame 时,dtypes 和 astype 的使用是非常重要的。
-
dtypes:
dtypes 是 DataFrame 对象的一个属性,用于查看每一列的数据类型。它返回一个 Series,其中包含 DataFrame 的每一列及其相应的数据类型。这对于了解数据的初始类型非常有用。 -
astype:
astype 是 Pandas 中的一个方法,用于将一列的数据类型转换为指定的类型。这对于数据清洗和预处理非常有用。它返回一个新的 Series 或 DataFrame,而不会改变原始对象。
3. 常用函数
3.1. 基本函数
- head() 和 tail(): 展示数据的前几行和后几行。
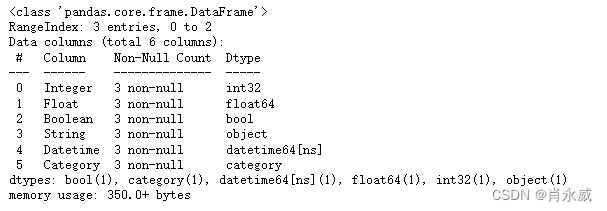
- info(): 提供有关 DataFrame 的详细信息,包括数据类型、非空值数等。
- describe(): 统计描述性统计信息,如平均值、标准差、最小值、最大值等。
- shape: 显示 DataFrame 的形状,即行数和列数。
以2.1章节的代码为例,继续代码,使用函数:

df.head(2)
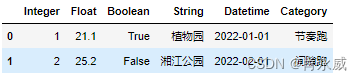
df.tail(2)
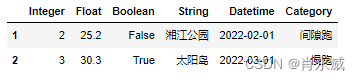
df.info()
df.describe()
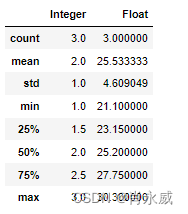
df.shape
(3, 6)
3.2. 窗口函数
- rolling(): 介绍窗口函数,用于执行滚动计算,如滚动平均值。
一般在使用了移动窗口函数rolling之后,我们需要配合使用相关的统计函数,比如sum、mean、max等。使用最多的是mean函数,生成移动平均值。
df.rolling(2).mean()
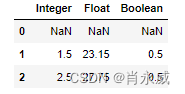
- expanding(): 展示扩展窗口,用于计算扩展窗口内的累积统计。
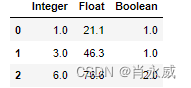
扩展窗口函数,扩展是指由序列的第一个元素开始,逐个向后计算元素的聚合值。expanding()函数,类似cumsum()函数的累计求和,其优势在于还可以进行更多的聚类计算。
df.expanding().sum()
3.3. 基本统计
首先,我们以sum()、mean()、median()常用统计函数的介绍,说明如何计算总和、均值、中位数等。
import pandas as pd
import numpy as np# 创建一个包含各种类型的DataFrame
data = {'Integer': pd.Series([1, 2, 3, 5, 3, 7, 6], dtype='int32'),'Float': pd.Series([21.1, 25.2, 30.3, 22.1, 10.1, 30.2, 32.3], dtype='float64'),'Boolean': pd.Series([True, False, True, True, False, True , False], dtype='bool'),'String': pd.Series(['植物园', '湘江公园', '太阳岛','植物园', '湘江公园', '太阳岛','八区体育场'], dtype='object'),'Datetime': pd.to_datetime(['2022-01-01', '2022-02-01', '2022-03-01', '2022-03-11', '2022-05-01', '2022-05-02','2022-06-01']),
}df = pd.DataFrame(data)# 添加一个分类类型的列
df['Category'] = pd.Series(['节奏跑', '间隙跑', '慢跑','节奏跑', '间隙跑', '慢跑', '慢跑'], dtype='category')print("包含各种类型的DataFrame:\n", df)print("包含合计sum::\n",df[['Integer','Float']].sum())
print("包含均值mean::\n",df[['Integer','Float']].mean())
print("包含中位数median::\n",df[['Integer','Float']].median())| 序号 | 函数 | 含义 |
|---|---|---|
| 1 | min() | 计算最小值 |
| 2 | max() | 计算最大值 |
| 3 | sum() | 求和 |
| 4 | mean() | 计算平均值 |
| 5 | count() | 计数(统计非缺失元素的个数) |
| 6 | size() | 计数(统计所有元素的个数) |
| 7 | median() | 计算中位数 |
| 8 | var() | 计算方差 |
| 9 | std() | |
| 10 | quantile() | 计算任意分位数 |
| 11 | cov() | 计算协方差 |
| 12 | corr() | 计算相关系数 |
| 13 | skew() | 计算偏度 |
| 14 | kurt() | 计算峰度 |
| 15 | mode() | 计算众数 |
| 16 | describe() | 描述性统计(一次性返回多个统计结果) |
| 17 | groupby() | 分组 |
| 18 | aggregate() | 聚合运算(可以自定义统计函数) |
| 19 | argmin() | 寻找最小值所在位置 |
| 20 | argmax() | 寻找最大值所在位置 |
| 21 | any() | 等价于逻辑“或” |
| 22 | all() | 等价于逻辑“与” |
| 23 | value_counts() | 频次统计 |
| 24 | cumsum() | 运算累计和 |
| 25 | cumprod() | 运算累计积 |
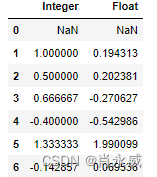
| 26 | pct_change() | 运算比率(后一个元素与前一个元素的比率) |
例如:
df[['Integer','Float']].pct_change()
统计函数是数据分析的核心内容之一,将 在后续内容中展开。