FLASK博客系列6——数据库之谜
我们上一篇已经实现了简易博客界面,你还记得我们的博客数据是自己手动写的吗?但实际应用中,我们是不可能这样做的。大部分程序都需要保存数据,所以不可避免要使用数据库。我们这里为了简单方便快捷,使用了超级经典的SQLite,它是一种基于文件,不需要启动后台服务的数据库。当然了,仅限于操作简单,访问量比较低的应用中使用,这也正是我们选用它的原因。
SQLAlchemy——python数据库工具
SQLAlchemy是python下的一个数据库工具,它提供了SQL工具包及对象关系映射(ORM)工具。你可以通过定义python类来表示数据库中的一张表,然后通过这个类来进行各种操作,从而代替书写SQL语句,而这个类我们称之为模型类。
但是,我们今天用另一个包——Flask-SQLAlchemy。它是一个简化了SQLAlchemy 操作的flask扩展,是SQLAlchemy的具体实现,封装了对数据库的基本操作。简而言之,可以更快更方便地帮助我们去构建博客,而不用细致去深究其原理。等以后有时间了我们另开一篇,讲讲SQLAlchemy的操作。
先把包装一下。
pip3 install flask-sqlalchemy接着初始化一下,将其跟flask关联起来。
import os
from flask_sqlalchemy import SQLAlchemy # 导入扩展类basedir = os.path.abspath(os.path.dirname(__file__)) # 绝对路径
app = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir, 'blog.db')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = Falsedb = SQLAlchemy(app) # 初始化扩展,传入程序实例 app
接着我们在pycharm打开控制台,创建数据库:
>>> from app import db
>>> db.create_all()然后在当前目录下我们可以看到生成了blog.db。是不是很简单呢?但这种方式会有问题,因为采用db.create_all在后期修改字段的时候,不会自动的映射到数据库中,必须删除表,然后重新运行db.create_all才会重新映射,这样不符合实际的工作要求。因此flask-migrate就是为了解决这个问题,它可以在每次修改模型后,可以将修改的东西映射到数据库中。
Flask-Migrate
使用flask_migrate必须借助flask_scripts,那么flask-script的作用是什么呢?flask-script的作用是可以通过命令行的形式来操作Flask。例如通过命令跑一个开发版本的服务器、设置数据库,定时任务等。
老样子,动手装包:
pip install Flask-Script如果用过django的同学都知道,操作很多命令都是通过python manager.py + 命令 来实现的。那我们也来模仿一番。
我们来定义下命令:
- python manage.py db init:初始化一个迁移脚本的环境,只需要执行一次,实际就是db.create_all()
- python manage.py db migrate:将模型生成迁移文件,只要模型更改了,就执行一遍这个命令。
- python manage.py db upgrade:将迁移文件真正映射到数据库中,每次运行migrate命令后,记得要运行这个命令。
我们接着新建一个models.py,用来定义模型类。定义一下User类和Article类。
from app import dbclass User(db.Model): # 表名将会是 user(自动生成,小写处理)id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 主键name = db.Column(db.String(20)) # 用户名class Article(db.Model): # 表名将会是 user(自动生成,小写处理)# id 主键 自增id = db.Column(db.Integer, primary_key=True, autoincrement=True)# 文章标题 非空title = db.Column(db.String(100), nullable=False)# 文章正文 非空content = db.Column(db.Text, nullable=False)# 关联表,这里要与相关联的表的类型一致, user.id 表示关联到user表下的id字段author_id = db.Column(db.Integer, db.ForeignKey('user.id'))# 给这个article模型添加一个author属性(关系表),User为要连接的表,backref为定义反向引用# lazy表示禁止自动查询,后面可以直接操作这个对象。只可以用在一对多和多对多关系中,不可以用在一对一和多对一中author = db.relationship('User', backref=db.backref('articles'), lazy='dynamic')
我们新建一个manage.py。
manage.py
from flask_script import Manager
from flask_migrate import Migrate, MigrateCommand
from app import app, db
from models import User, Articlemanager = Manager(app)# 1. 要使用flask_migrate,必须绑定app和db
migrate = Migrate(app, db)
# 2. 把MigrateCommand命令添加到manager中
manager.add_command('db', MigrateCommand)if __name__ == '__main__':manager.run()把上面生成的blog.db删除,在命令行中执行 python manage.py db init。同样的,生成了blog.db。同时在我们的项目中会生成一个migrations文件夹,其中versions中没有任何内容。如下图:
然后我们开始迁移数据库。上面的命令成功后,执行如下命令,将模型生成迁移文件。
python manage.py db migrate如下所示,versions文件夹中生成了一个文件88ae96b5a85e_.py。
这个就是迁移文件了。我们打开来看看里面是什么。
"""empty messageRevision ID: 88ae96b5a85e
Revises:
Create Date: 2020-05-24 19:51:53.279700"""
from alembic import op
import sqlalchemy as sa# revision identifiers, used by Alembic.
revision = '88ae96b5a85e'
down_revision = None
branch_labels = None
depends_on = Nonedef upgrade():# ### commands auto generated by Alembic - please adjust! ###op.create_table('user',sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),sa.Column('name', sa.String(length=20), nullable=True),sa.PrimaryKeyConstraint('id'))op.create_table('article',sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),sa.Column('title', sa.String(length=100), nullable=False),sa.Column('content', sa.Text(), nullable=False),sa.Column('author_id', sa.Integer(), nullable=True),sa.ForeignKeyConstraint(['author_id'], ['user.id'], ),sa.PrimaryKeyConstraint('id'))# ### end Alembic commands ###def downgrade():# ### commands auto generated by Alembic - please adjust! ###op.drop_table('article')op.drop_table('user')# ### end Alembic commands ###
这就是ORM能够帮我们操作数据库的秘密,emmmm。这时候你的数据库里是还没有创建表的。必须执行下面的语句。
python manage.py db upgrade我们借助pycharm来查看下创建的表结构是不是跟我们预期的一样。
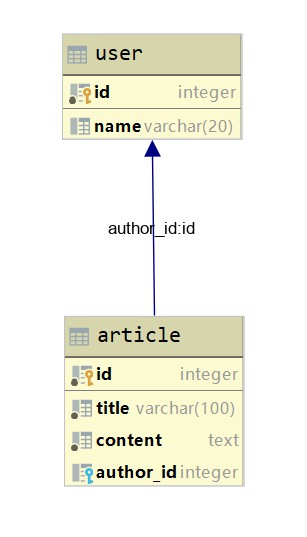
奈斯,一模一样。
好啦,至此我们的数据库部分就完成了创建,下一节我们将会介绍如何去插入数据并展示在我们的博客中。