python 爬虫之 爬取网站信息并保存到文件

文章目录
- 前期准备
- 探索该网页的HTML码的特点
- 开始编写代码
- 存入文件
- 总的程序
- 文件存储效果
前期准备
随便找个网站进行爬取,这里我选择的是(一个卖书的网站)
https://www.bookschina.com/24hour/62700000/

我的目的是爬取这个网站的这个页面的书籍的名称以及相对应的价格
探索该网页的HTML码的特点
在该网页右键,选择检查,就可以看到下面的样子
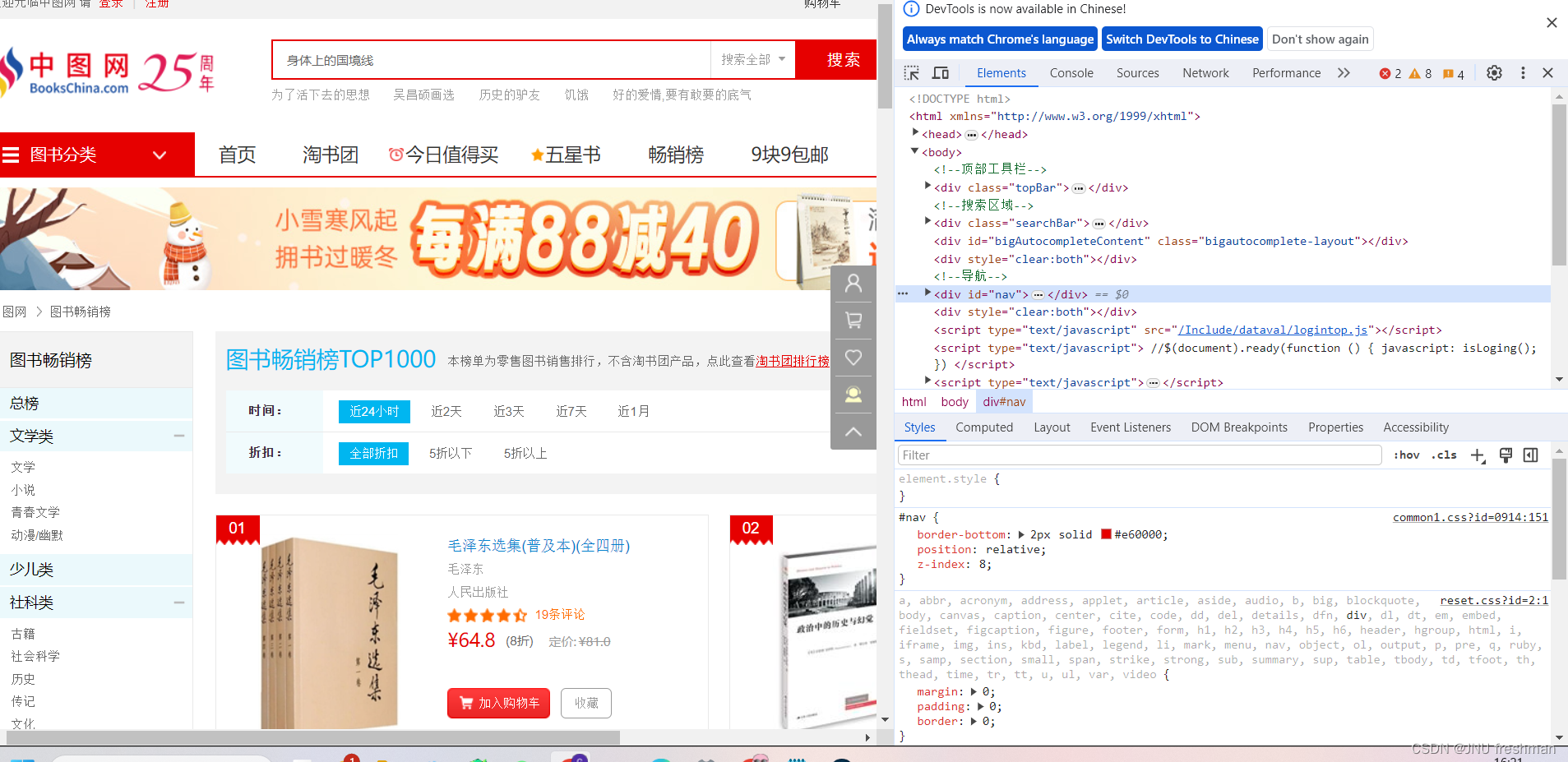
然后按下面图片的第一个按键(作用是:当你鼠标停留在网页时,会自动显示到对应的网页代码)

查找书名的特点
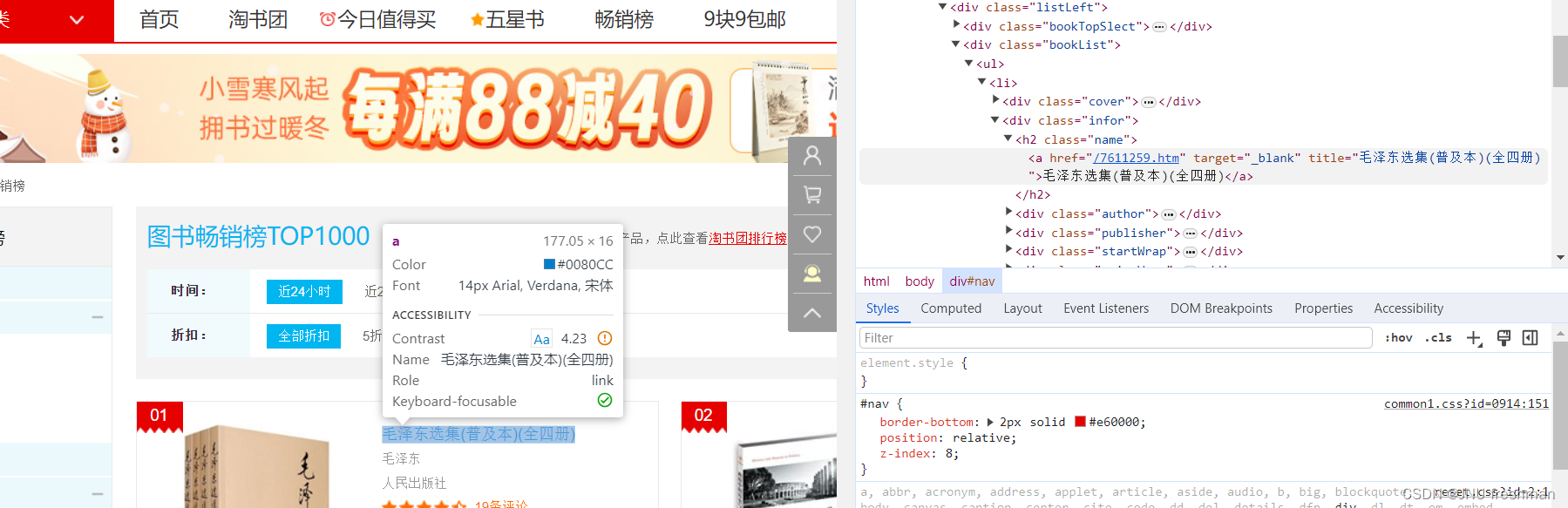

我们发现,书名是位于<h2 class = "name" >标签的 <a >标签里面的
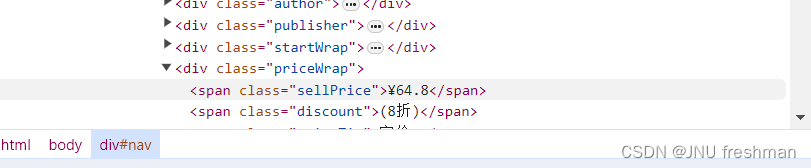
同理,可以找到价格是位于<div class = "priceWrap" 里面的<span class = "swllPrice>标签里面的 "
那么这么就好办了
开始编写代码
import requests
from bs4 import BeautifulSoup# 设置请求头,模拟浏览器访问
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}# 发送GET请求获取页面内容
response = requests.get(r'https://www.bookschina.com/24hour/62700000/', headers=headers)# 打印HTTP响应状态码
print(response.status_code)# 获取页面内容
content = response.text# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(content, "html.parser")# 存储书名的列表
namestore = []# 存储价格的列表
pricestore = []# 查找所有class为"name"的h2标签
allname = soup.findAll("h2", attrs={"class": "name"})# 遍历每个h2标签
for name in allname:# 在每个h2标签中查找所有的a标签realnames = name.findAll("a")# 遍历每个a标签for realname in realnames:# 将书名添加到namestore列表中namestore.append(realname.string)# 查找所有class为"priceWrap"的div标签
allprice = soup.findAll("div", attrs={"class": "priceWrap"})# 遍历每个div标签
for price in allprice:# 在每个div标签中查找所有class为"sellPrice"的span标签realprices = price.findAll("span", attrs={"class": "sellPrice"})# 遍历每个span标签for realprice in realprices:# 将价格添加到pricestore列表中pricestore.append(realprice.string)# 使用zip函数将书名和价格对应起来,并打印结果
for a, b in zip(namestore, pricestore):print(a, b)存入文件
# 打开文件,准备写入数据,使用UTF-8编码
with open(r"d:\Desktop\畅销书以及价格.txt", "w", encoding='utf-8') as f:# 使用zip函数将书名和价格对应起来,并写入文件for a, b in zip(namestore, pricestore):# 写入书名f.write(str(a) + '\n')# 写入价格f.write(str(b) + '\n')总的程序
import requests
from bs4 import BeautifulSoupheaders ={"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}responce = requests.get(r'https://www.bookschina.com/24hour/62700000/',headers = headers)print(responce.status_code)
content = responce.text
soup = BeautifulSoup(content,"html.parser")namestore = []
pricestore = []allname = soup.findAll("h2",attrs={"class" : "name"})
for name in allname:realnames = name.findAll("a")for realname in realnames:#print(realname.string)namestore.append(realname.string)allprice = soup.findAll("div",attrs={"class":"priceWrap"})
for price in allprice:realprices = price.findAll("span",attrs={"class" : "sellPrice"})for realprice in realprices:#print(realprice.string)pricestore.append(realprice.string)with open(r"d:\Desktop\畅销书以及价格.txt","w",encoding='utf-8') as f:for a, b in zip(namestore, pricestore):f.writelines(str(a) + '\n' )f.writelines(str(b) + '\n' )文件存储效果
