Linux:创建进程 -- fork,到底是什么?
相信大家在初学进程时,对fork函数创建进程一定会有很多的困惑,比如:
- 1.fork做了什么事情??
- 2.为什么fork函数会有两个返回值?
- 3.为什么fork的两个返回值,会给父进程谅回子进程pid,给子进程返回0?
- 4.fork之后:父子进程谁先运行??
- 5.如何理解同一个变量,会有不同的值??
本篇文章将来仔细回答一下这些问题。
目录
1.如何查看进程
2. 通过系统调用创建进程-fork
2.1 初识fork
2.2 fork原理
1.如何查看进程
1.1 进程的信息可以通过 /proc 系统文件夹查看
通过ls指令来查看所有的进程,proc是动态目录结构,用来存放所有的进程,目录的名称就是用进程的id命名的。

1.2 进程信息同样可以使用ps(process status)工具来获取
- 进程id(PID)通过getpid 系统调用获得
- 父进程id(PPID)通过getppid 系统调用获得
#include<stdio.h>#include<sys/types.h>#include<unistd.h>int main(){while(1){printf("I am a process! myid:%d parentid:%d\n",getpid(),getppid()) ;sleep(1);}return 0;}
我们可以使用shell再开一个窗口登录一次进行查看。

"aux" 是 "ps" 命令的选项之一,表示显示所有用户的所有进程,通过查询,可以看到你自己 ./ 启动的进程,最后一个进程是当前的grep的查找进程。
关于当前工作目录
我们在C语言学习文件操作是会提到当前目录,我们以 "w" 方式读取文件时,如果文件不存在,那么文件会在当前工作目录cwd下创建。那么一个进程是如何找到当前目录的呢?
我们让下面代码运行起来
1 #include<stdio.h>2 #include<sys/types.h>3 #include<unistd.h>4 int main()5 {6 //更改当前工作目录7 chdir("./wdz");//没有这个目录不会更改,我这里是创建好了这个目录 8 9 // cwd/hello.txt 10 FILE* file = fopen("hello.txt","w");//文件不存在会在当前工作目录下创建11 if(file==NULL)12 {13 return 1;14 }15 fclose(file);16 17 18 while(1)19 {20 printf("I am a process! myid:%d parentid:%d\n",getpid(),getppid());21 sleep(1);22 }23 return 0;24 }
这里通过修改当前目录已经对将文件创建在更改的目录下:
 可以发现:
可以发现:
- 默认情况下,进程所处的目录就是当前工作目录
- 一个进程可以找到自己的可执行程序
- 每一个进程都有自己的工作目录
2. 通过系统调用创建进程-fork
2.1 初识fork
首先使用fork创建一个进程
#include<stdio.h>#include<unistd.h>#include<sys/types.h>int main(){printf("我是一个父进程我的pid:%d\n",getpid());//创建一个子进程! pid_t id = fork();//fork之前只有父进程会执行fork之前的代码,fork之后父子进程都要执行后面的代码while(1){printf("我是一个进程,pid:%d,ppid%d,fork return:%d\n",getpid(),getppid(),id);//这个printf函数在代码这里只调用一次,但在运行时调用了两次sleep(1);//for test}return 0;}
运行结果:

看到这里大家的疑惑就出来了
目前可以发现:只有父进程执行fork之前的代码,fork之后,父子进程都要执行后续的代码!
一个函数竟然会有两个返回值???fork成功的时候,会有两个不同的返回值,给子进程返回0;
给父进程返回子进程的pid
fork代码的一般写法:
1.我们为什么要创建子进程?
我们想让子进程协作父进程完成一些工作,这些工作是单进程解决不了的
2.我们创建子进程是为了让子进程和父进程做一样的事情吗??
我们创建子进程,就是为了让子进程和父进程做不一样的事情,执行不一样的代码
3. 应该如何保证父子进程做不一样的事情呢?
可以通过判断fork的返回值,判断谁是父,谁是子,然后让他们执行不同的代码片段!!
使用 if 对父子进程分流:
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>int main()
{printf("我是一个父进程我的pid:%d\n",getpid());//创建一个子进程! //bash也是用C语言写的,命令行启动的进程,都是bash的子进程,所以bash源代码中创建子进程也是用的forkpid_t id = fork(); //fork()之后,用if进行分流 if(id<0) return 1; //进程创建失败 else if(id == 0) { //子进程 while(1) { printf("我是子进程,pid:%d,ppid%d,ret:%d,正在执行下载\n",getpid(),getppid(),id); sleep(1);//for test } } else { //父进程 while(1) { printf("我是父进程,pid:%d,ppid%d,ret:%d,正在执行播放任务\n",getpid(),getppid(),id); sleep(1);//for test }}return 0;
}执行结果
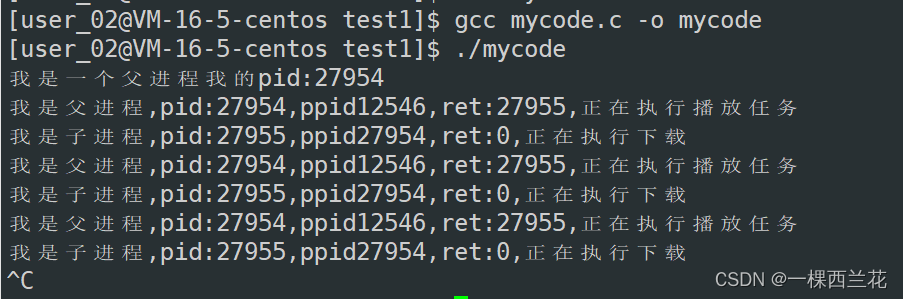
可以发现通过 if 对fork函数返回值进行判断,实现了父子进程可以执行不同的任务。
2.2 fork原理
对于上面的现象,我们来解答一下疑惑
- 1.fork做了什么事情??
- 2.为什么fork函数会有两个返回值?
- 3.为什么fork的两个返回值,会给父进程谅回子进程pid,给子进程返回0?
- 4.fork之后:父子进程谁先运行??
- 5.如何理解同一个变量,会有不同的值??
1. fork做了什么事情??
用于创建一个进程,在内核中操作系统重新为其申请了一个PCB,并使用父进程的PCB进行初始化,且子进程与父进程同时指向相同的代码。所以fork之前的代码子进程也是可以看到的。
那为什么子进程不从头开始执行呢?
因为有程序计数器pc,会使代码一句一句执行,子进程在创建时和继承父进程的pc。所以说也会继续向下执行。
2.为什么fork函数会有两个返回值?
首先fork是一个函数,如果一个函数return时,说明一个函数的核心工作已经做完。我们知道fork之后代码会共享,所以是fork函数做完核心工作后就会共享,return也会父子进程共享,所以会有两个返回值。
3.为什么fork的两个返回值,会给父进程谅回子进程pid,给子进程返回0?
因为一个父进程可以有多个子进程,父进程信息中只有pid 和 ppid,为了唯一确定子进程,所以返回子进程的pid,而子进程中由于有父进程ppid,所以返回0可以用来判断。
4.fork之后:父子进程谁先运行??
不确定。创建完成子进程,只是一个开始。创建完成子进程之后,系统的其他进程,父进程,和子进程,接下来要被调度执行的,当父子进程的PCB都被创建并在运行队列中排队的时候,哪一个进程的PCB先被选择调度,那个进程就先运行,由操作系统自主决定!!由各自PCB中的调度信息(时间片,优先级等)+调度器算法共同决定。
5.如何理解同一个变量,会有不同的值??
进程的独立性,首先是表现在有各自的PCB,进行之间不会互相影响!代码本身是只读的,不会影响!但是数据父子是会修改的,所以代码共享,但是数据各个进程必须想办法各自私有一份!!
这个怎么做到的?通过写时拷贝。这样做的好处就是不用将所有的数据都进行拷贝,当数据需要修改时才做拷贝,可以提高效率。
本篇结束!