YOLOv3老矣尚能战否?基于YOLOv3开发构建建钢铁产业产品智能自动化检测识别系统,我们来与YOLOv5进行全方位对比评测
钢铁产业产品智能自动化检测识别相关的项目在我们前面的博文中已经有了相应的实践了,感兴趣的话可以自行移步阅读即可:
《python基于DETR(DEtection TRansformer)开发构建钢铁产业产品智能自动化检测识别系统》
《AI助力钢铁产业数字化,python基于YOLOv5开发构建钢铁产业产品智能自动化检测识别系统》
在前文中我们大都是使用较为新颖的检测模型来完成相应的项目开发的,这时我们不免有个疑问,早期提出来的模型比如YOLOv3是否还有一战之力呢?出于好奇就拿来开发实践了,首先看下实例效果:

整体使用层面上来说yolov3和yolov5的项目差异不大,所以比较熟悉yolov5的话,直接上手使用yolov3项目的话基本是没有什么难度的。
因为是出于好奇,这里就直接先选择的是yolov3-tiny版本的模型,目的就是能够比较快的训练完成,模型如下:
# parameters
nc: 10 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [10,14, 23,27, 37,58] # P4/16- [81,82, 135,169, 344,319] # P5/32# YOLOv3-tiny backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [16, 3, 1]], # 0[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2[-1, 1, Conv, [32, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4[-1, 1, Conv, [64, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8[-1, 1, Conv, [128, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16[-1, 1, Conv, [256, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32[-1, 1, Conv, [512, 3, 1]],[-1, 1, nn.ZeroPad2d, [0, 1, 0, 1]], # 11[-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12]# YOLOv3-tiny head
head:[[-1, 1, Conv, [1024, 3, 1]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)[-2, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 8], 1, Concat, [1]], # cat backbone P4[-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)[[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)]
训练数据配置文件如下所示:
# path
train: ./dataset/images/train/
val: ./dataset/images/test/# number of classes
nc: 10# class names
names: ['chongkong', 'hanfeng', 'yueyawan', 'shuiban', 'youban', 'siban', 'yiwu', 'yahen', 'zhehen', 'yaozhe']默认是100次epoch的迭代计算,训练日志如下所示:
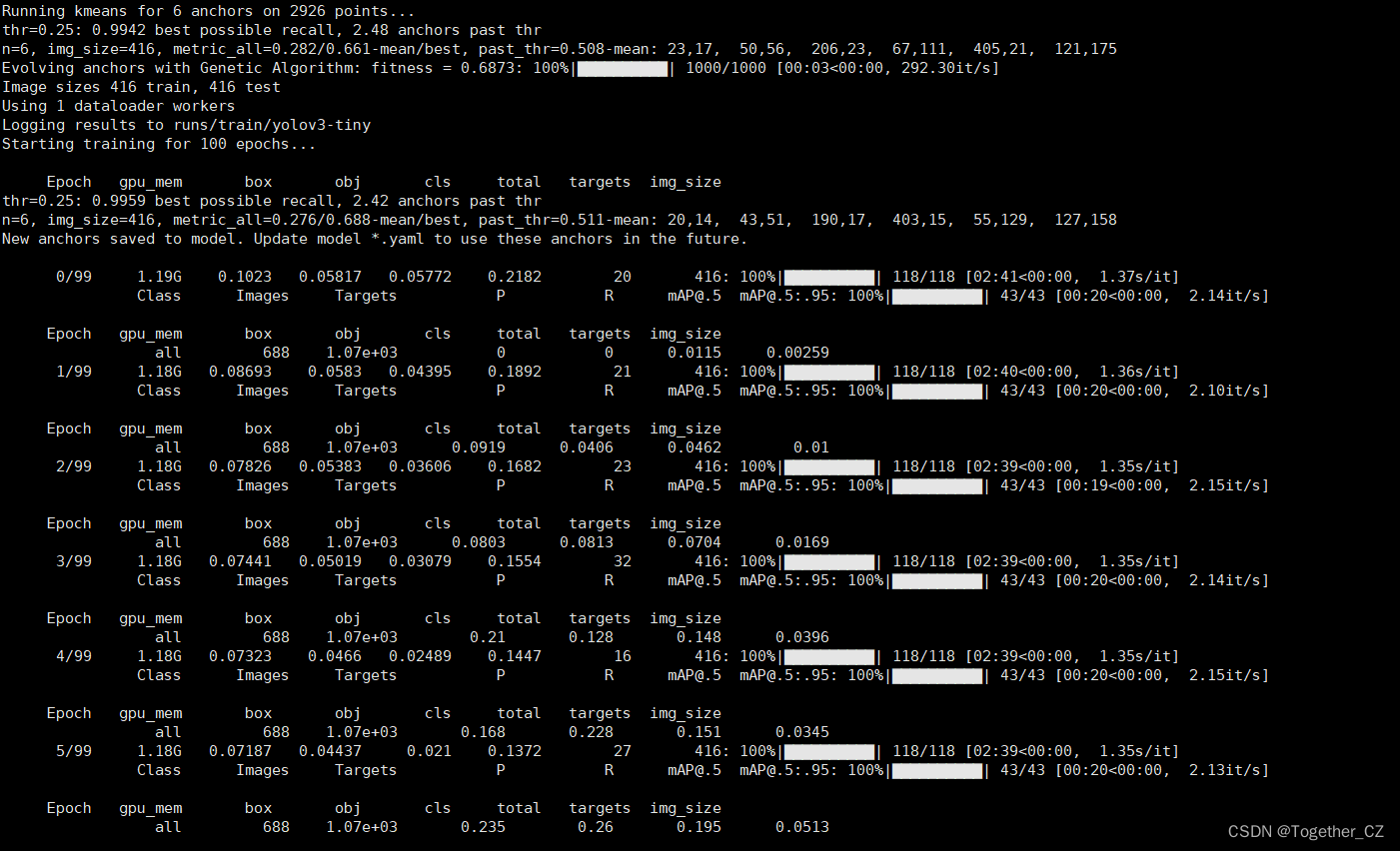
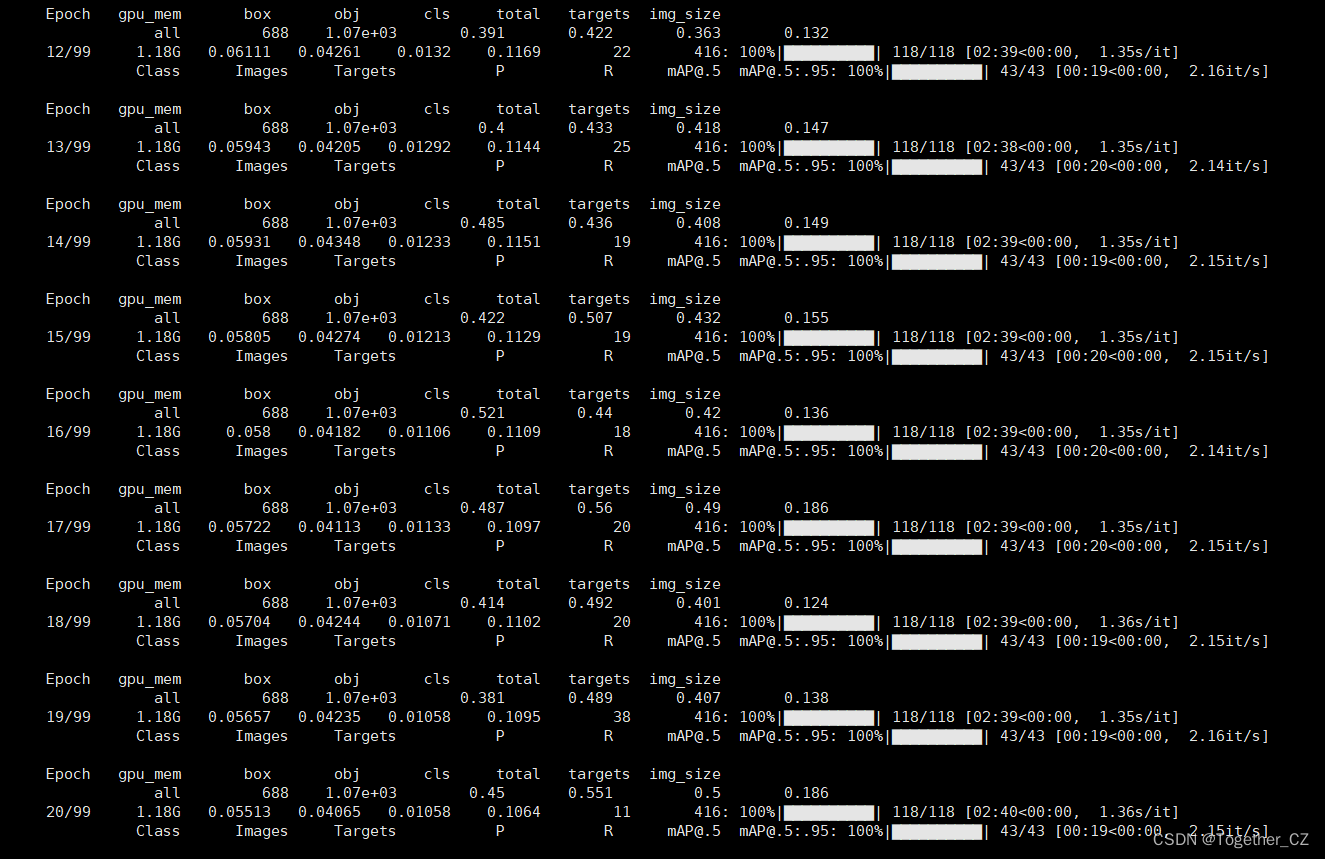
等待训练完成后,看下结果详情:
【混淆矩阵】
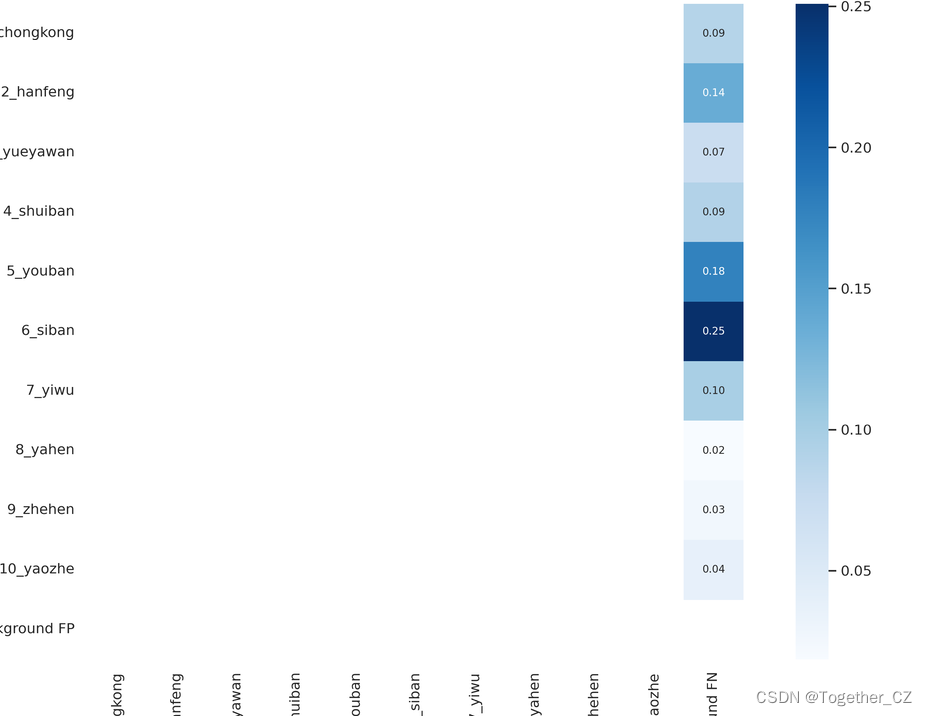
感觉yolov3项目提供的混淆矩阵不如yolov5项目的直观,下面是yolov5项目的混淆矩阵:

【Label数据可视化】
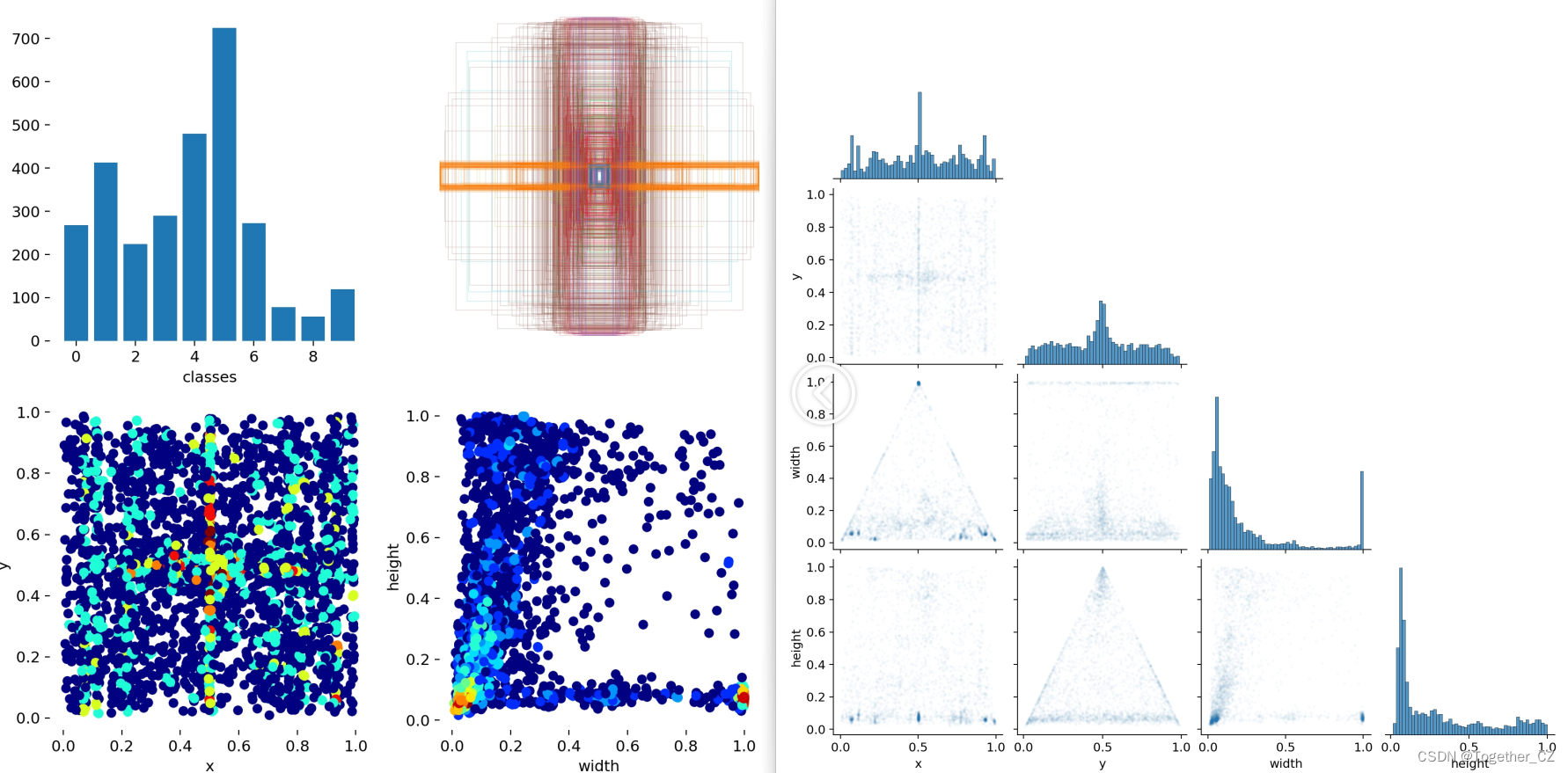
【PR曲线】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率-召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率-召回率曲线。
根据曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
精确率-召回率曲线提供了更全面的模型性能分析,特别适用于处理不平衡数据集和关注正例预测的场景。曲线下面积(Area Under the Curve, AUC)可以作为评估模型性能的指标,AUC值越高表示模型的性能越好。
通过观察精确率-召回率曲线,我们可以根据需求选择合适的阈值来权衡精确率和召回率之间的平衡点。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。
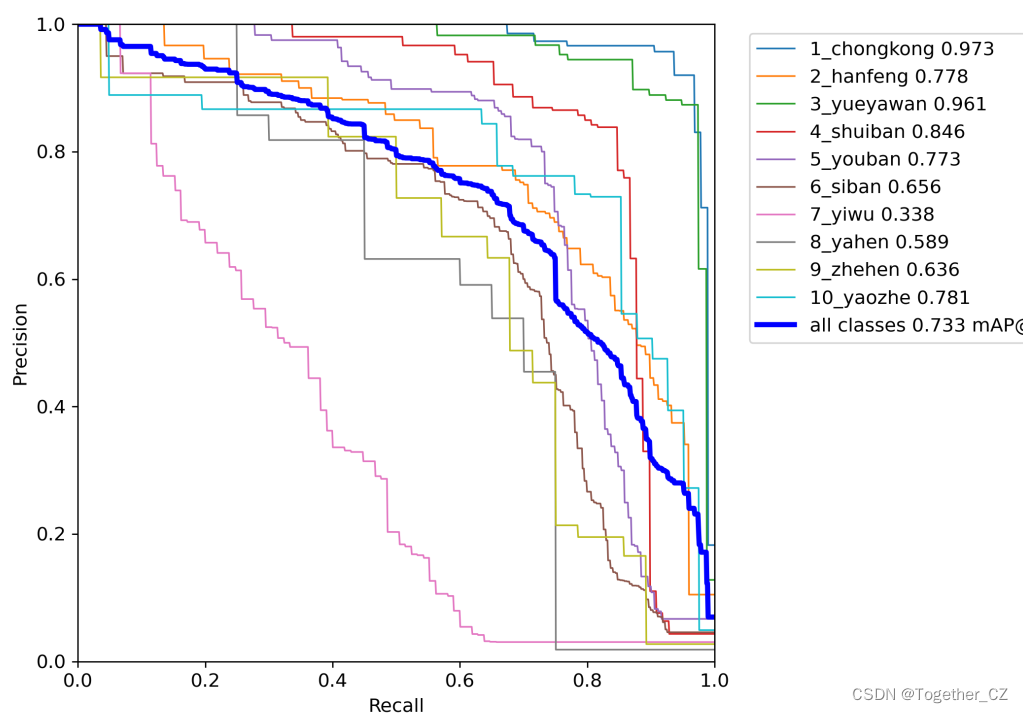
yolov3的项目只提供了PR曲线可视化,没有单独的precision曲线和recall曲线和F1曲线,这点感觉是肯定不如yolov5项目的。
【训练可视化】
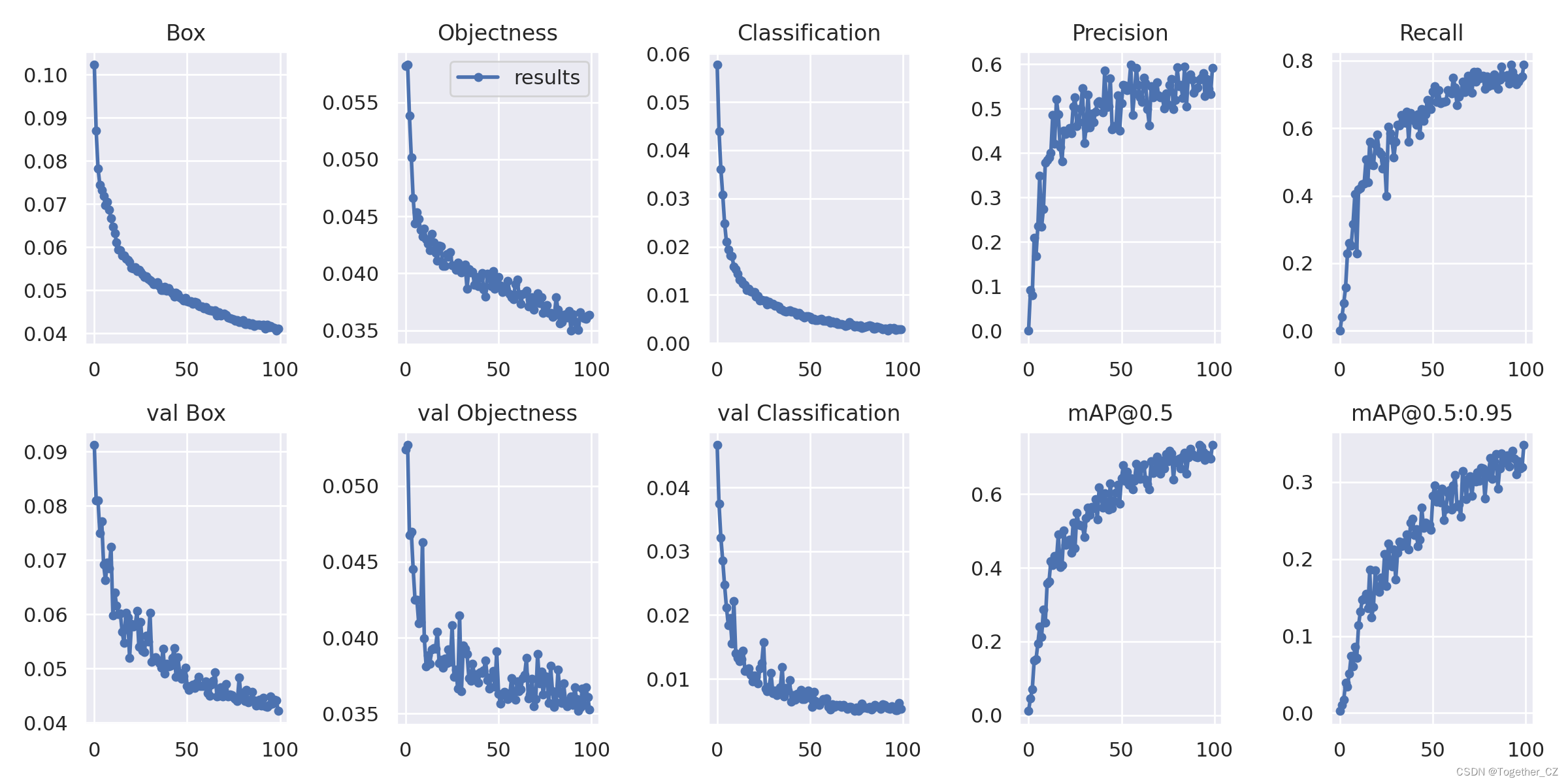
【Batch计算实例】


既然yolov3只提供了PR曲线,那我就直接基于PR曲线来进行对比吧,如下:

上面是yolov5最强的模型效果与yolov3-tiny的对比,可以说是毫不意外全面碾压了。
接下来我们来看yolov5系列最弱的模型与yolov3-tiny的对比效果,如下:
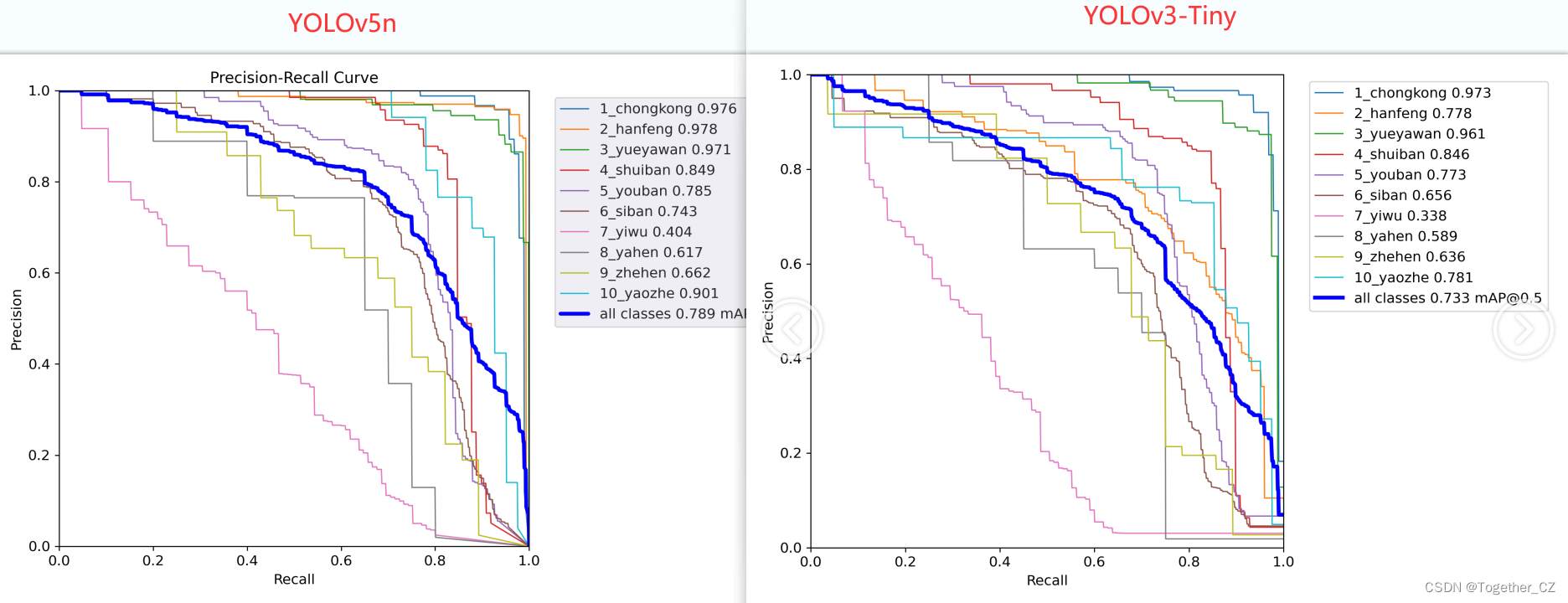
可以看到:即使是yolov5最弱的n系列的模型也做到了对yolov3-tiny系列模型的全面碾压了,所有的训练数据集等参数在整个过程是保持完全一致的。
那么你觉得YOLOv3在当下的目标检测类任务中是否还有一战之力了呢?感兴趣的话也都自行动手实践下吧!