【追求卓越02】数据结构--链表
引导
今天我们进入链表的学习,我相信大家对链表都很熟悉。链表和数组一样,作为最基础的数据结构。在我们的工作中常常会使用到。但是我们真的了解到数组和链表的区别吗?什么时候使用数组,什么时候使用链表,能够正确的选取吗?
链表需要我们进行一些练习才能更好的掌握。我后面也会结合几个经典的练习题进行训练。
链表和数组区别
数组和链表的最大区别就是存储了。从上一栏,我们了解到数组的存储结构是连续的。链表与之恰恰相反,它可以利用内存中零碎的内存空间。如图:
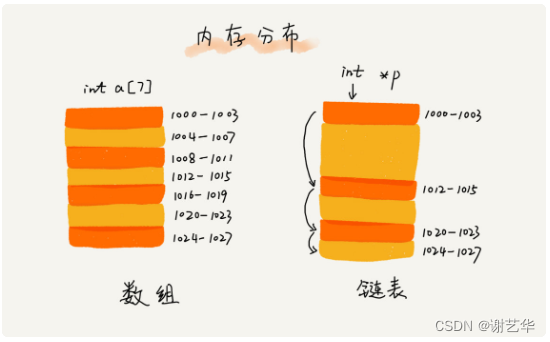
这样就存在一个问题;当我们向内存申请100M的数组时,即使内存剩余200M内存,但经常会提示申请失败“out of memory”。因为内存中存在着很多的内存碎片,导致200M内存中基本不存在100M连续的。但是链表就不会存在这种情况,因为它支持动态分配,不需要内存地址上的连续要求。
单链表
单链表,是比较简单的了,并且也比较常见。结构图如下:

单链表的删除,新增操作的时间复杂度?
我们知道数组的删除,新增操作,要进行数据的搬移(保证数据的连续性)。导致数组的复杂度为O(n)。但是单链表并不需要进行数据的搬移,只要修改节点的指针的指向即可。所以链表的复杂度时O(1)。
单链表的随机访问的时间复杂度?
数组的存储是连续的,当知道下标时,数组复杂度O(1);但是链表由于不是连续存储的,所以在访问第i个节点时,需要从头节点,一个接一个遍历。因此链表复杂度O(n)。
循环链表
循环链表其实就是特殊的单链表(尾节点指向了头节点)。因此它也不是很难。不过对于特殊的问题,使用循环链表比较方便。比图经典的约瑟夫问题。结构图如下:

双向链表
双向链表虽然我们接触的不多,但在项目中,双向链表比单链表使用的更加广泛。 双向链表其实就是多了一个指针变量,指向了前节点。结构图如下:
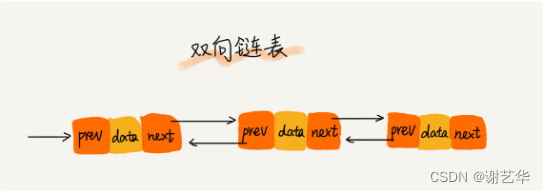
正如我们上面说的双向链表在工作中使用的往往比单链表要广泛,为什么呢?
从链表的删除举例,删除链表的中节点,无非就是以下两种情况:
- 删除节点中,值等于某个特定值的节点
- 删除给定指针指向的节点
对于第一种情况,无论是单链表或双链表都要先找到对应的节点,再进行删除操作。 根据复杂度的加法原则,O(n)+O(1)=O(n)。两者的复杂度都是O(n)。
对于第二种情况,给定一个需要删除节点之后,仅需要将该节点的前节点指向该节点的下一个节点即可。
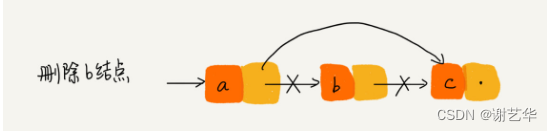
但是单向链表需要进行遍历,找到该节点的前节点。需要O(n)。所以单链表需要O(n)。但是由于双向链表每个节点有指向前节点的指针。故双向链表仅需O(1)。
其实第二种情况,是我们经常会遇到的,比如LinkedHashMap容器,就是使用了双向链表。
不仅仅时删除和插入操作,双向链表比单向链表高效。其实查询也会比单向链表高效。比如在一个有序的链表中,我们可以保存上一次查询节点,判断查询值的大小,采取向上还是从下查询的方式。
其实这就是一个空间换时间的例子,双向链表虽然比单向链表要高效,但是它比单向链表多一个指针变量。因此消耗的内存资源也会比较多。
数组和链表的选择
我觉得数组和链表的选择应该要结合以下几点因素考虑:
1. 时间复杂度
数组的随机访问时间复杂度是O(1),删除操作的复杂度O(n);链表的随机访问的复杂度是O(n),删除操作的复杂度O(1);结合你的业务逻辑,评价主要是查询操作居多还是删除操作居多。
2. 内存要求
因为链表中每个节点需要一个指向下一个节点的指针变量,所以链表比数组消耗更多的内存资源。当你的内存资源比较有限的情况下,我还是建议你使用数组。
3. 性能提高--CPU缓存机制
我们知道数组的访问比链表要高效。但是这只是从时间复杂度来分析的。但是不仅仅如此,数组在访问操作时,因为cache机制的存在,效率会更加高。因此,如果你想更进一步提高访问的效率,我建议你也选择数组。
总结:综上所述,数组有这么多的优势,我们是不是基本都选择数组呢?我们工作中基本还是选择链表较多。因为我们基本不会存在性能和内存资源上的担忧,并且链表使用起来还是比较方便的。
什么是CPU缓存机制?
上面我们谈到了CPU缓存机制,数组对CPU缓存机制比较友好能够加快访问效率,但是链表对其不友好,不能提高效率。但是何为CPU缓存机制呢?其实它是依据操作系统中局部性原理来实现的。
所谓的局部性原理,包括两个部分:时间局部性和空间局部性。时间局部性指的是最近访问的存储位置,很可能在不久的将来还要访问;空间局部性指存储访问有聚集的倾向,当访问了某一个位置之后,很有可能也要访问附近的位置。
我们知道Cache是高速访问的缓存,比内存的访问还要快。CPU从内存中访问数据并不会仅仅只获取该地址的内容。而是会将该内容在内的物理块一起放到Cache缓存中。下次再读取内容时,首先再Cahce中找,找不到再从内存中重复上面的操作。
因为数组的存储空间是连续的,所以能够很好的适应CPU缓存机制。但是链表是非连续存储的,所以对CPU缓存机制不友好。
总结
了解了数组和链表之间的区别,以及如何选择数组和链表数据结构。数组对CPU缓存机制更加友好。