优化记录 -- 记一次搜索引擎(SOLR)优化
业务场景
某服务根据用户相关信息,使用搜索引擎进行数据检索
软件配置
solr 1台:32c 64g 数据10gb左右,版本 7.5.5
应用服务器1台:16c 64g
应用程序 3节点
问题产生现象
1、因业务系统因处理能不足,对业务系统硬件平台进行升级,升级变更为 16c64g —> 32c64g 增加 16c
2、业务系统升级,处理能力增加,对原搜索引擎服务器的qps有所提升,原qps 1500 提升至 2600左右
3、搜索引擎负载发生极大变化,从原始负载60左右,提升至85左右,远超预期
分析问题
应用层:
链接数未提升,仅提升qps,应该不会对solr 造成过大的影响
SOLR 层
分析缓存
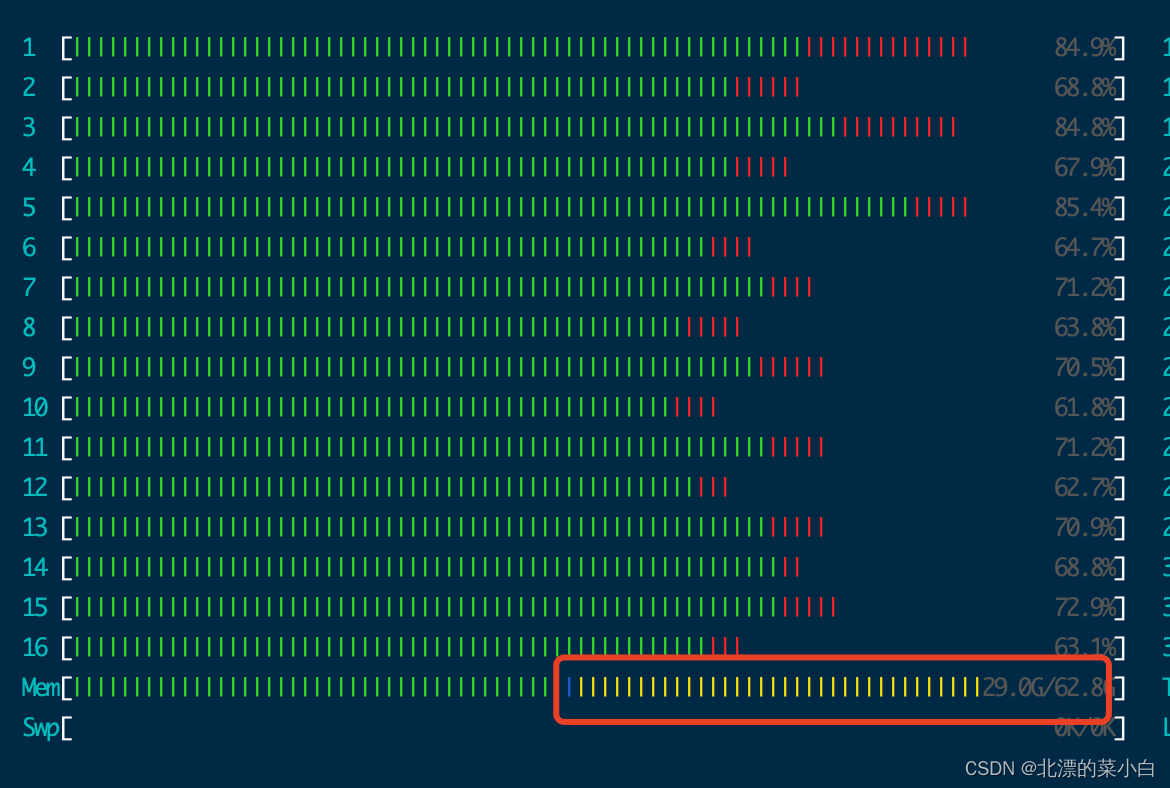
检查os 剩余内存
使用 htop 观测剩余内存还有将近30g,因此决定调整 solr 相关缓存配置
分析 SOLR 线程栈
1、使用 jstack pid >pid.jstack 导出solr 线程运行情况
2、通过 IBM JCA469.jar 分析工具,检查线程锁
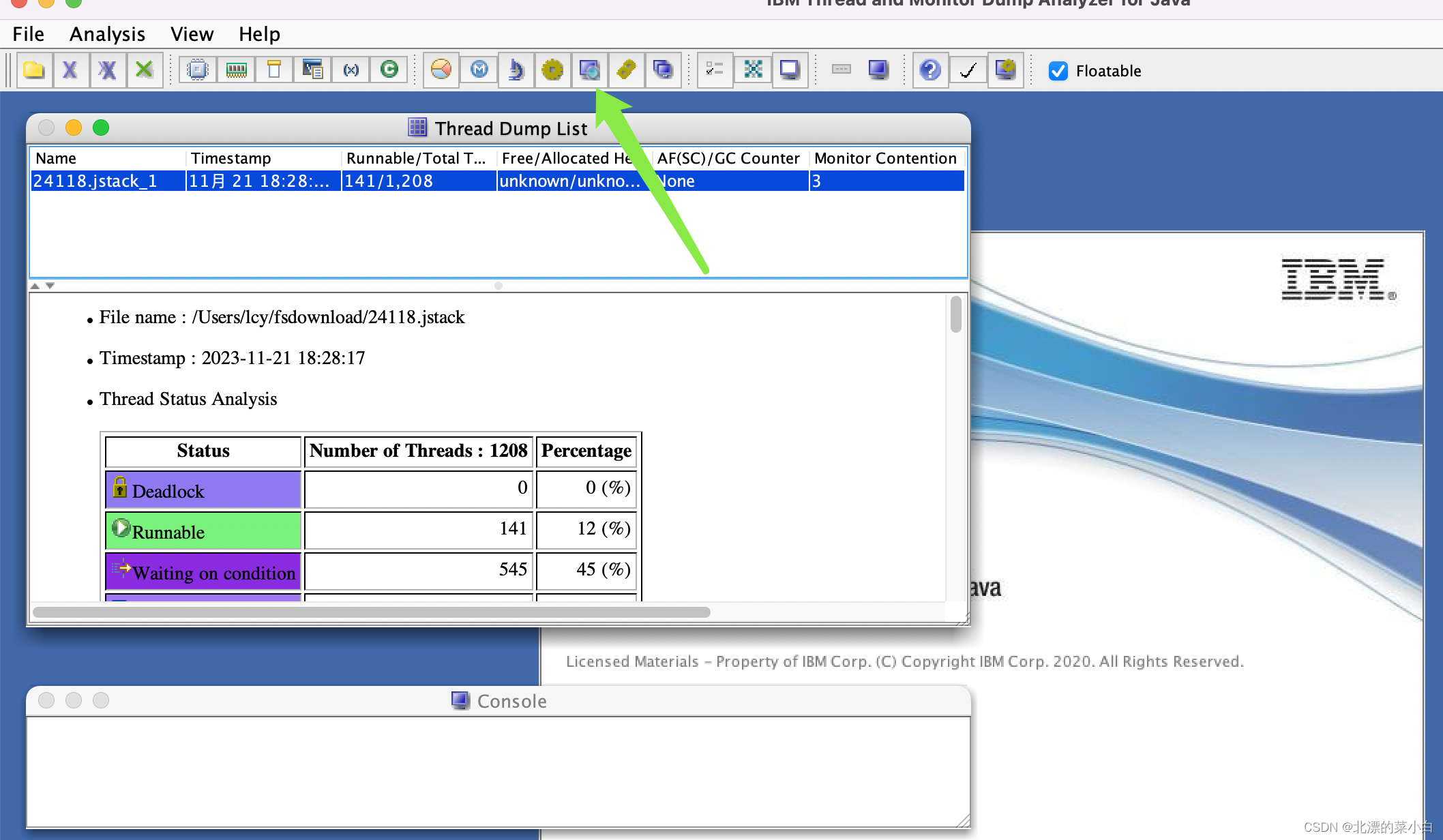
发现500+线程等待log锁
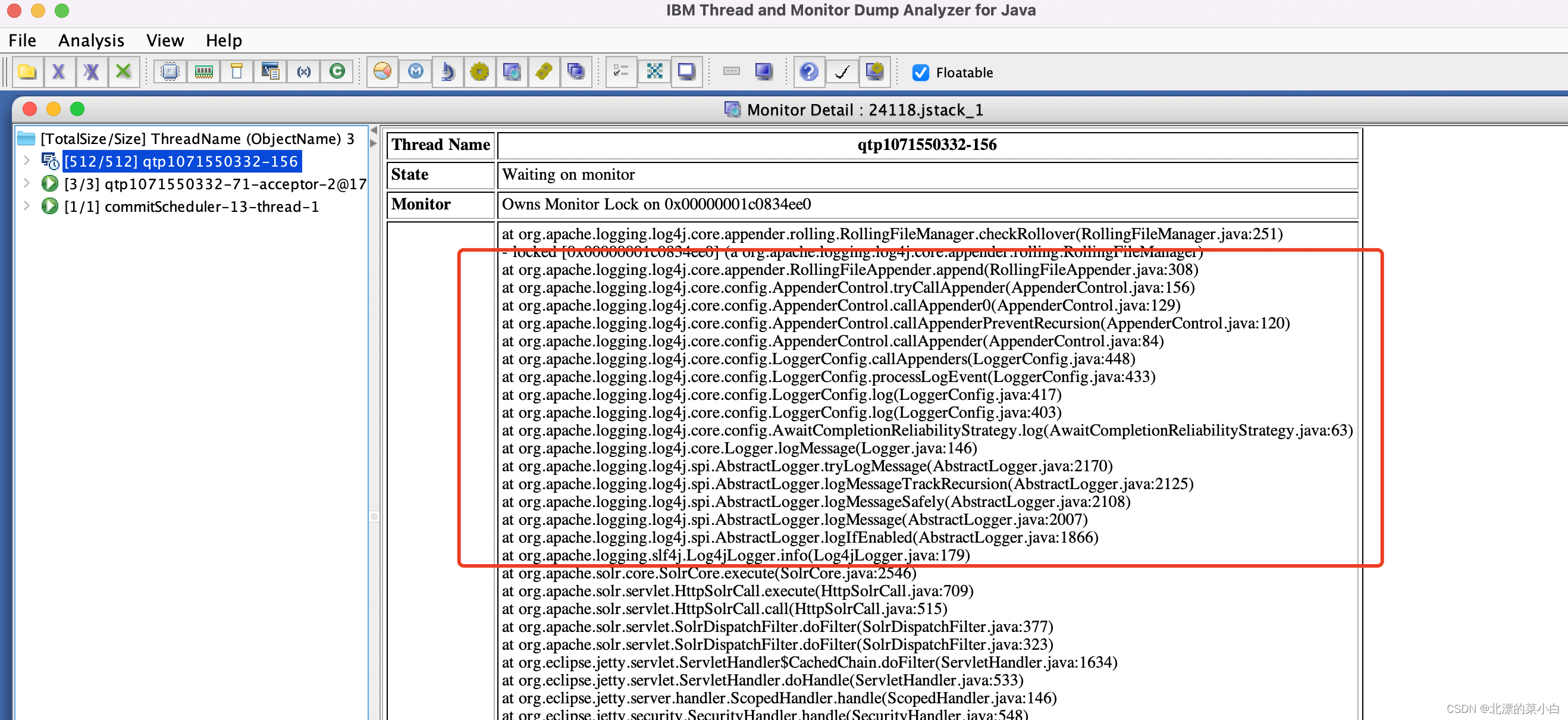
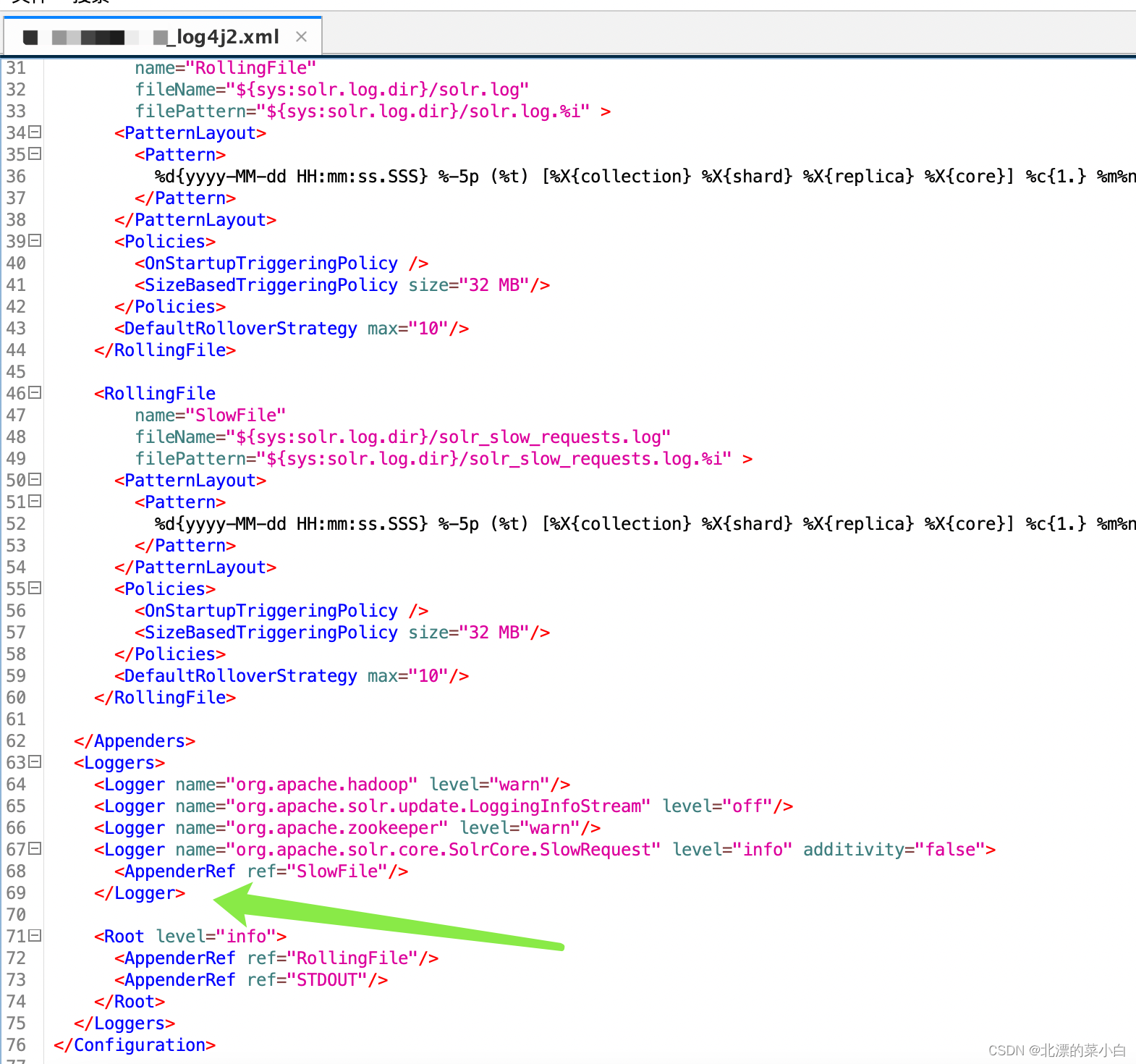
检查 solr 相关日志配置
发现 solr 7.5.5 使用 log4j2日志框架,且使用同步日志输出模式
调整方案
增加SOLR缓存,提升缓存命中率
原始配置
<filterCache class="solr.FastLRUCache"maxRamMB="2048"autowarmCount="150000"/><queryResultCache class="solr.LRUCache"size="65536"initialSize="65536"autowarmCount="0"/><documentCache class="solr.LRUCache"size="65536"initialSize="65536"autowarmCount="0"/>
更新后配置
<filterCache class="solr.FastLRUCache"maxRamMB="2048"autowarmCount="150000"/><queryResultCache class="solr.LRUCache"size="131070"initialSize="131070"autowarmCount="0"/><documentCache class="solr.LRUCache"size="131070"initialSize="131070"autowarmCount="0"/>增加JVM 内存
Xmx16g ---> Xmx24g
使用全局异步日志打印日志输出
在 solr.in.sh 添加JVM启动参数
-Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
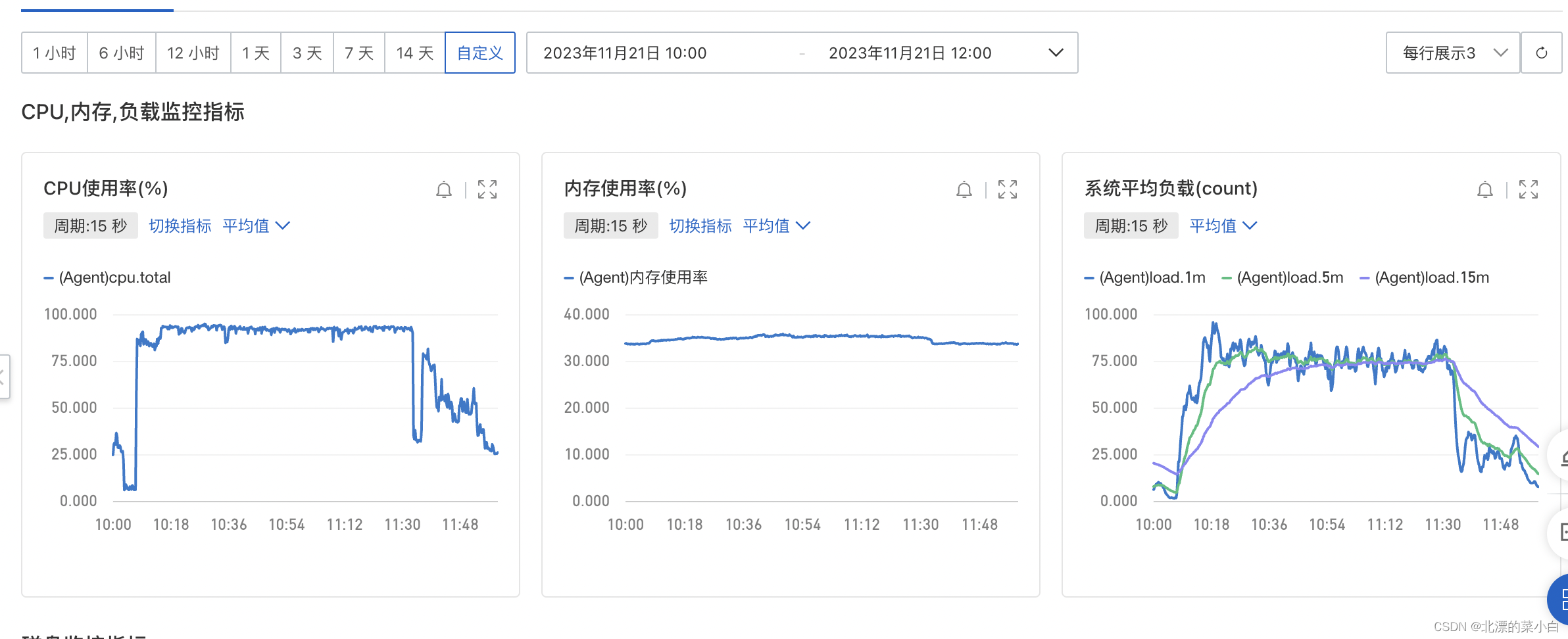
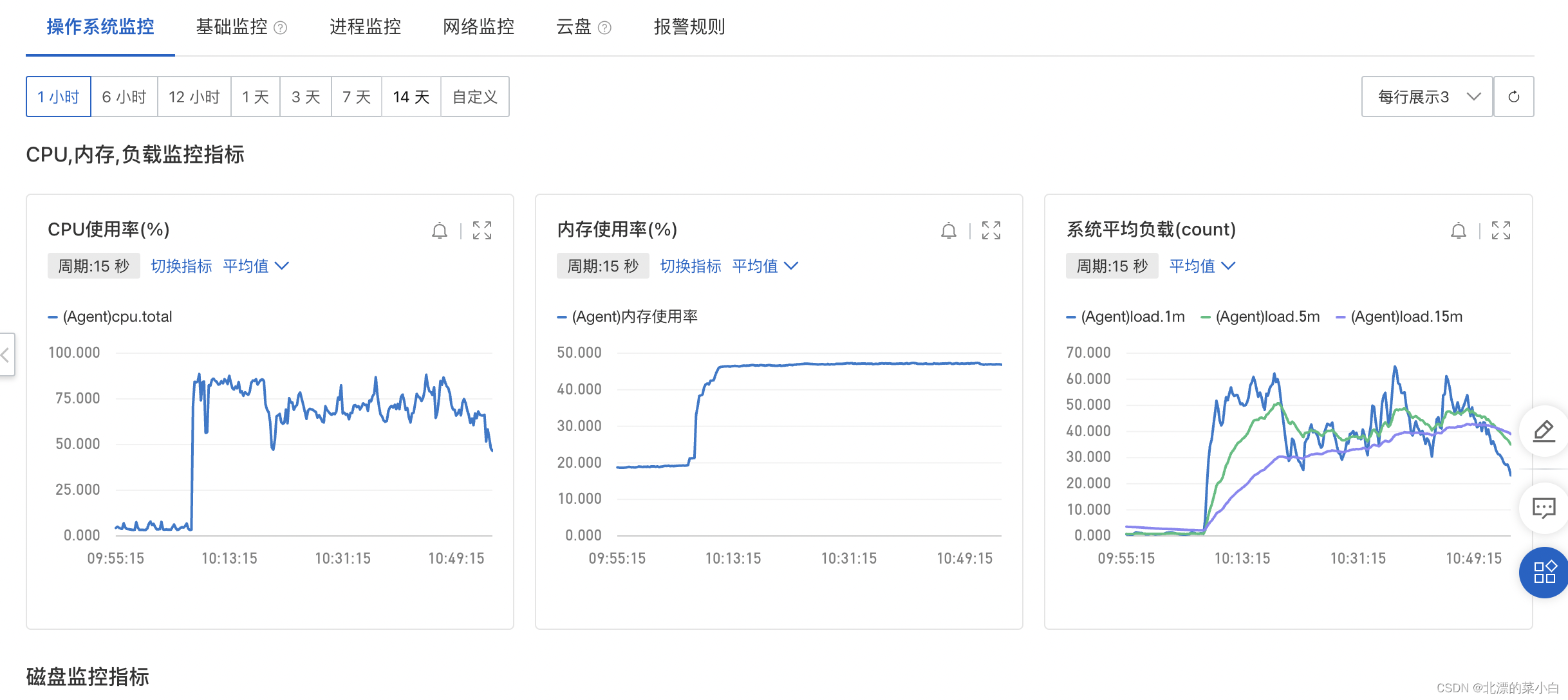
调整后效果如下
os 负载情况
调整前
调整后
线程锁情况
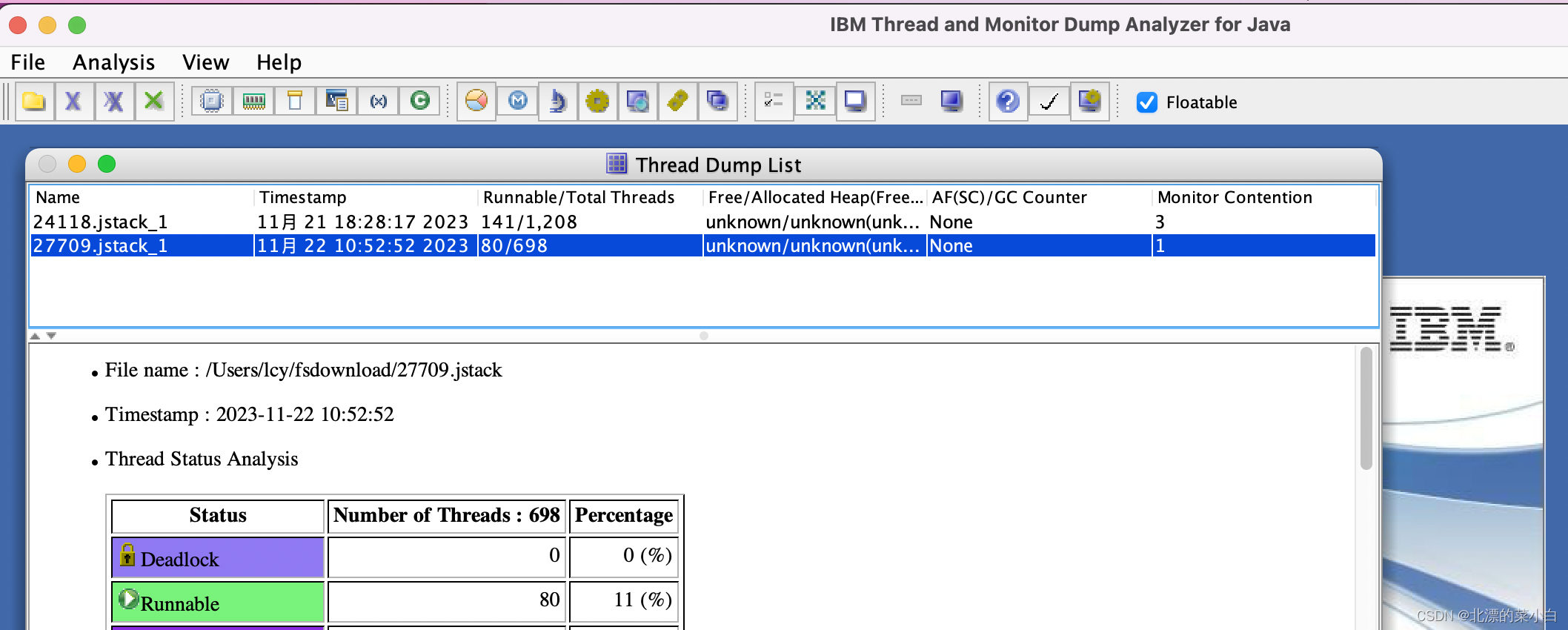
调整后